Simplify Logic (Q-M Methods)
免责申明
本文不是学习用途, 只是一个为了打游戏做的 “攻略” 笔记罢了.
游戏的名字叫做 Turing Complete, (只要 70 元, 还有学生版).
简单来说就是一个连连看小游戏吧. (目前只玩了几关, 感觉挺有意思的).
那么为什么会有这篇攻略笔记呢? 因为这个游戏的交互我个人认为是非常不友好的. 甚至我可以说, 这个游戏的交互还不如我写的那个 垃圾节点编辑器: 拖动节点竟然不会同时移动边, 并且快捷键和操作比较反人类. (不过我的也没高级到哪里去了就是, 并且里面的功能和效果肯定是远超我的版本了).
啊, 闲话说多了, 那么这个和游戏有什么关系呢? 答案就是, 因为连线太麻烦了, 所以我想要来一个能够一键化简的程序, 来减少我连线的负担.
关于使用的符号和其他
符号约定
我在这里使用的符号大多都是和我在 离散数学课 上学到的差不多. 唯一不同的是, 可能我会为了好看而将部分的 \(¬ A\) 写成 \(\overline{A}\).
并且因为我熟悉的是 and, or, not 门, 而不是在游戏中提供的 nand 门,
所以我会使用前者来表示大多数的逻辑符号.
NAND 和其他的门 (如果你懒得思考但是又很好气的话)
NAND (\(↑ = λ xy. ¬(x ∧ y)\)) 代表了什么呢?
实际上可以看成 Not-AND 即与非门的缩写.
NAND 拥有表述所有逻辑关系的能力, 其自身便可以构成联结词的完备集, 用人话来说, 就是可以通过 NAND 门组合来实现其他各种门的功能, 比如:
- NOT (非门): \(¬ = λ x. x ↑ y\)
- AND (与门): \(∧ = λ x y. ¬(x ↑ y)\)
- OR (或门): \(+ = λ xy . \overline{\overline{x} ∧ \overline{y}} = λ xy . \overline{x} ↑ \overline{y}\) (德摩根定律)
如果你不了解离散数学, 也不想的话, 实际上, 可能可以做得丑一点也没关系的.
这游戏, 能玩通关么?
我也不知道, 毕竟我可是连初始台地都打不过的废人啊… 并且感觉还挺忙的, 如果能玩游戏的话, 肯定优先选择和别人玩联机游戏啦.
(吐槽一下这该死的校园网联机和该死的作息表. )
使用的编程语言?
我使用的是 Common Lisp, 至于为什么要用 Lisp 类型的编程语言, 只能说是因为自己想要学学看吧… 其他倒是没有什么特别的想法, 毕竟也不能说对 Common Lisp 得心应手, 甚至不能够做到描述好了算法 (或者说脑子里有一个简单的过程), 就能够用代码来直接地表示出来.
总而言之就是代码写少了, 平时接触得还不够多呢…
化简逻辑表达式的方法: Q-M 方法
尽管化简逻辑表达式的方式有很多, 但是为了方便, 我选择使用 Quine–McCluskey algorithm 来执行.
并且为了方便理解, 我选择写一个程序来理解这个问题. 或者可以参考这个 视频, 只要你能够接受印度老哥的神奇口音…
逻辑运算, 最小表达式和真值表
一些简单的逻辑运算约定和方法
- 符号 ='A= 用
0,1来表示真假 (∧ A B)与门(defun ∧ (&rest in-s) "Logic AND for IN-S." (labels ((iter (in) (if (car in) (if (eq (car in) 0) 0 (iter (rest in))) 1))) (iter in-s)))
(∨ A B)或门(defun ∨ (&rest in-s) "Logic OR for IN-S." (labels ((iter (in) (if (car in) (if (eq (car in) 1) 1 (iter (rest in))) 0))) (iter in-s)))
Note: 我觉得可以写得更加高明一些: 比如用高阶函数的方式来进行定义这两个函数.
(¬ A)非门(defun ¬ (in) "Logic NOT for IN." (if (eq in 0) 1 0))
- 顺便来个 NAND (与非门)
(defun ↑ (A B) "NAND A and B. " (¬ (∧ A B)))
- 通过
to-bits来将整数变成以base为底, 长度为length的一个 List.(defun to-bits (num length &optional (base 2)) "Turn NUM into LENGTH bits list in BASE (default to binary)." (let ((res '())) (dotimes (i length) (push (mod num base) res) (setq num (floor (/ num base)))) res))
当然, 高位溢出.
- 以及对应的转换函数:
(defun to-num (bits &optional (base 2)) "Turn BITS into number in BASE (default to binary)." (let ((acc 1) (num 0)) (loop for val in (reverse bits) do (setq num (+ num (* val acc)) acc (* acc base))) num))
- 通过 ='(∧ A B)= 这样的形式来表示符号表达式,
通过
truth-table来计算:(defun logic-exp-eval (exp pattern) "Replace SYM in EXP by VAL. PATTERN like '((SYM VAL)). " (let ((exp-val exp)) (loop for sym-val in pattern do (destructuring-bind (sym val) sym-val (setq exp-val (subst val sym exp-val)))) (eval exp-val))) (defun truth-table (exp vars) "Generate Truth Table of EXP using VARS. " (let ((length (length vars)) (table `((,vars VAL)))) (dotimes (idx (expt 2 length)) (let* ((pattern (to-bits idx length)) (val-pattern (mapcar (lambda (sym val) (list sym val)) vars pattern)) (val (logic-exp-eval exp val-pattern))) (push `(,pattern ,val) table))) (reverse table)))
实际上, 需要了解的事情基本上只有一个: 那就是真值表. 比如一个真值表可能如下:
| (A B C D) | VAL |
| (0 0 0 0) | 0 |
| (0 0 0 1) | 0 |
| (0 0 1 0) | 1 |
| (0 0 1 1) | 1 |
| (0 1 0 0) | 0 |
| (0 1 0 1) | 0 |
| (0 1 1 0) | 0 |
| (0 1 1 1) | 1 |
| (1 0 0 0) | 0 |
| (1 0 0 1) | 1 |
| (1 0 1 0) | 1 |
| (1 0 1 1) | 1 |
| (1 1 0 0) | 0 |
| (1 1 0 1) | 1 |
| (1 1 1 0) | 0 |
| (1 1 1 1) | 1 |
实际上可以发现用这样的方式写起来还是挺麻烦的.
所以会想用一种叫做 minterm 的形式来进行缩写,
如 \(m_3\) 对应的就是 (A B C D) -> (0 1 0 1) 的情况;
并且使用 \(m(1, 3, 4) = m_1 + m_3 + m_4\) 来进行缩写.
譬如上面的就可以写成 (minterm '(2 3 7 9 10 11 13 15) '(A B C D)).
实际上, 对于任意的真值表, 都能够通过上面的 minterm 的形式来构建表示方法:
首先找出所有的一个真值对应的逻辑组合 (即输出为 1 的点),
然后计算它们对应输入的 \(m_i\) (比如 (1 1 0 1) 的输入就是 11,
就对应的是 \(m_{11}\) 的结果).
将这些值 \(m_i\) 全部合在一起就得到了最终的结果了.
一些代码
如何通过逻辑真值表来得到 minterm 的表示法:
(defun to-minterm (table)
"Trun truth table TABLE into minterm expression."
(let* ((vars (caar table))
(body (rest table))
(minterms (loop for row in body
when (eq (cadr row) 1)
collect (to-num (car row))))
(length (length minterms)))
(cond ((eq length 0) 0)
((eq length 1) `(minterm (quote ,(car minterms)) (quote ,vars)))
(t `(minterm (quote ,minterms) (quote ,vars))))))
关于如何通过 minterm 来还原完整的的逻辑表达式:
(defun minterm (patterns vars)
"Make logic expressions by PATTERNS using VARS.
PATTERNS can be a list: `(minterm '(1 2) '(A B))';
or could be a single item: `(minterm 1 '(A B))'. "
(let ((length (length vars)))
(labels ((single (num)
(cons '∧ (mapcar (lambda (sym val)
(if (eq val 0) `(¬ ,sym) sym))
vars (to-bits num length)))))
(if (atom patterns)
(single patterns)
(cons '∨ (mapcar #'single patterns))))))
OK, 那么前置知识大概就是这么多了吧.
Q-M 方法的一步步解释
根据 这篇文档 里面介绍的方式, Q-M 方法有 4 步:
- Generate Prime Implicants
- Construct Prime Implicant Table
- Reduce Prime Implicant Table
- Remove Essential Prime Implicants
- Row Dominance
- Column Dominance
- Solve Prime Implicant Table
但是这里面写得全是看不懂的术语, 加上我最讨厌背东西, 所以离散代数一结束, 我就啥也不记得了…
那么可以通过看看实际操作, 然后理解如何实现吧… 下面的例子参照的是前文提到的 视频.
Step 1: Generate Prime Implicants
对于一个真值表
(truth-table
(minterm '(0 1 3 7 8 9 11 15) '(A B C D))
'(A B C D))
| (A B C D) | VAL |
| (0 0 0 0) | 1 |
| (0 0 0 1) | 1 |
| (0 0 1 0) | 0 |
| (0 0 1 1) | 1 |
| (0 1 0 0) | 0 |
| (0 1 0 1) | 0 |
| (0 1 1 0) | 0 |
| (0 1 1 1) | 1 |
| (1 0 0 0) | 1 |
| (1 0 0 1) | 1 |
| (1 0 1 0) | 0 |
| (1 0 1 1) | 1 |
| (1 1 0 0) | 0 |
| (1 1 0 1) | 0 |
| (1 1 1 0) | 0 |
| (1 1 1 1) | 1 |
要得到它的 Prime Implicants 需要如下的操作: (这里仅仅只是一个非常粗略的介绍, 具体的细节步骤请看下面的实现和详细说明)
- 仅仅关心 \(m_i\), 所以首先不考虑真值表中结果为
0的项; 对每一个(A B C D)的取值的1的数量进行计数; 并根据这个来对真值表进行分类.比如真值表中
1个数为1个的组为(0 0 0 1)和(1 0 0 0), 即 \(m_1\) 和 \(m_8\). - 将相邻类之间的两两元素进行比较并将不相同的部分做标记.
如 \(m_0\)
(0 0 0 0)和 \(m_1\)(0 0 0 1)分别属于count-1 -> 0和count-1 -> 1的类, 它们间不相同的只有D位, 于是将其进行标记(0 0 0 -).于是可以发现, 如果想要表示 \(m_0 + m_1\), 由于结合律 \(\overline{A} \overline{B} \overline{C} (D + \overline{D})\), \(D\) 就被消除了. 于是在这里就有了第一次简化.
之所以是相邻类, 也是因为每个类之间最少也会有
1个不同的元素, 所以可以做到消去的功能. (当然, 如果是两个不同的元素的话, 就做不到消去的目标了, 不过让我感到奇怪的是, 竟然没有一个教材专门指出这一点, 至少我看的这个没有, 可能是因为太简单吧… 不过至少对我这种笨蛋友好一点吧…) - 在完成了上一步的基础上, 继续使用上面的技巧进行化简直到得到最简式.
即可以用最简式的或来表示原本的逻辑表达式.
但是很显然, 这些逻辑表达式的和并不一定是最简的表达式. 所以需要之后的进一步的约化.
Step 1.1 Group by count-1
分组代码
- 计数
BINS中的1的数量:(defun count-1 (bins) "Count `1' number in BINS." (let ((sum 0)) (loop for val in bins when (eq val 1) do (setq sum (1+ sum))) sum))
- 去掉不关心的部分
(defun strip-zero-and-format (table) "Read truth table TABLE and produce a formatted output for further process. For example: `(strip-zero-and-format (truth-table LOGIC-EXP VARS))'. " (let* ((vars (caar table)) (body (rest table))) (labels ((val (row) (cadr row)) (bin (row) (car row))) (cons `(GROUP MINTERM ,vars) (loop for row in body when (eq (val row) 1) collect (let ((bins (bin row))) (list (count-1 bins) (to-num bins) bins)))))))
- 或者根据
minterm来快速生成:(defun format-by-minterm-exp (minterm) "Input MINTERM expression: `(minterm 'MINTERMS 'VARS)', generate formatted table. For example: `(format-by-minterm-exp '(minterm '(0 1) '(A B)))'. " (destructuring-bind (- (- minterms) (- vars)) minterm (cons `(GROUP MINTERM ,vars) (loop for term in (if (atom minterms) (list minterms) minterms) collect (let ((bins (to-bits term (length vars)))) (list (count-1 bins) term bins))))))
- 以及根据
GROUP进行分组(defun assoc-update (key obj alist) "Insert OBJ into ALIST at KEY position." (if (assoc key alist) (push obj (cdr (assoc key alist))) ; push to existed key (push (cons key (list obj)) alist)) ; add new key alist) (defun group-by (func lst) "Group items in LST by the value of FUNC. Return a AList." (let ((groups '())) (loop for item in lst ; kinda like bucket-sort do (setq groups (assoc-update (funcall func item) item groups))) groups))
使用
group-by函数就可以轻松对格式化的真值表进行分类了:(defun group-formatted (formatted) "Group formatted truth table FORMATTED. For example: `(group-formatted (format-by-minterm-exp MINTERM))'. " (let ((vars (nth 2 (car formatted))) (body (rest formatted))) (cons `(GROUP MINTERMS ,vars) (group-by #'first body))))
- 为了得到更加好看一点的结果,
这里做一个格式化输出:
(defun grouped-and-format-output (grouped) "Input table with `(GROUP MINTERM (VALS))' pattern, output grouped one. For example: `(grouped-and-format-output (group-formatted FORMATTED))'. " (let ((title (car grouped)) (grouped (rest grouped)) (res '())) (loop for group in grouped ; for all groups do (loop for row in (cdr group) ; push items to output table do (push row res))) (cons title res)))
根据 (A B C D) 中 1 的数量进行计数 (count-1),
然后分类的结果为:
| GROUP | MINTERMS | (A B C D) |
| 0 | 0 | (0 0 0 0) |
| 1 | 1 | (0 0 0 1) |
| 1 | 8 | (1 0 0 0) |
| 2 | 3 | (0 0 1 1) |
| 2 | 9 | (1 0 0 1) |
| 3 | 7 | (0 1 1 1) |
| 3 | 11 | (1 0 1 1) |
| 4 | 15 | (1 1 1 1) |
Step 1.2 Mark Difference
可以发现, 在相邻的类之间, 因为它们的 minterm 的 count-1 的数量相差 1,
所以在 (A B C D) 的比较形式中, 在相邻类间的两个元素, 至少会有一项是不相等的.
其中核心的部分就是找出两个 (A B C D) 形式之间是否只有一位不同,
并将该位进行标记.
具体代码
- 比较两个
(A B C D)形式:(defun compare-bins (bins-a bins-b) "Compare BINS-A and BINS-B, return marked bins or NIL for fail. For example: + `(compare-bins '(0 0 1) '(0 0 0))' returns `(0 0 -)' + `(compare-bins '(0 1 1) '(0 0 0))' returns `NIL'." (let* ((count-diff 0) (tape (loop for a in bins-a for b in bins-b while (< count-diff 2) if (eq a b) collect a else collect '- and do (setq count-diff (1+ count-diff))))) (if (eq count-diff 1) tape NIL)))
- 将相邻两组之间进行比较 (比较
count-1为n和n + 1的情况):(defun compare-two-group (n g-n g-n+1) "Compare two group G-N and G-N+1. The input two group are list of bins, for example: `((m1 (0 0 1)) (m2 (0 1 0)))'. The output are like `(((m1 m2) (1 0 -)) ((m3 m4) (0 - 0)))'. The input two group can also be like `(((m1 m2) (- 0 1)) ((m1 m2) (0 - 0)))', which will be passed in Step 1.3 for further simplify. " (labels ((minterm-list (m-pattern) (let ((m (car m-pattern))) (if (atom m) (list m) m)))) (let ((compare-res '())) (loop for m-a in g-n do (loop for m-b in g-n+1 do (let* ((m1 (minterm-list m-a)) (bin-1 (cadr m-a)) (m2 (minterm-list m-b)) (bin-2 (cadr m-b)) (cmp (compare-bins bin-1 bin-2))) (when cmp (push (list n (append m1 m2) cmp) compare-res))))) compare-res))) (defun compare-grouped-nexts (grouped) "Compare the GROUPED input. The input will be like `((GROUP MINTERM VARS) GROUPED-ALIST)'. " (let* ((vars (nth 2 (car grouped))) (body (rest grouped)) (length (length vars))) (labels ((content (group) (mapcar (lambda (lst) (cdr lst)) (cdr group)))) (let ((n-group NIL) (n+1-group NIL) (compare NIL)) (cons `(GROUP MINTERMS ,vars) (loop for n from 0 to (1- length) if (and (setq n-group (assoc n body)) (setq n+1-group (assoc (1+ n) body)) (setq compare (compare-two-group n (content n-group) (content n+1-group)))) collect (append (list n) compare)))))))
- 为了方便查看, 进行格式化输出:
(defun compared-group-format (compared-group) "Format the COMPARED-GROUP for output." (let ((title (first compared-group)) (body (rest compared-group)) (res '())) (loop for group in body do (loop for pattern in (cdr group) do (push pattern res))) (cons title (reverse res))))
于是可以列出表来:
| GROUP | MINTERMS | (A B C D) |
| 0 | (0 1) | (0 0 0 -) |
| 0 | (0 8) | (- 0 0 0) |
| 1 | (1 3) | (0 0 - 1) |
| 1 | (1 9) | (- 0 0 1) |
| 1 | (8 9) | (1 0 0 -) |
| 2 | (3 7) | (0 - 1 1) |
| 2 | (3 11) | (- 0 1 1) |
| 2 | (9 11) | (1 0 - 1) |
| 3 | (7 15) | (- 1 1 1) |
| 3 | (11 15) | (1 - 1 1) |
Step 1.3 Repeat Step 1.2 Until NIL To Get Prime Implicants
重复 Step 1.2 的操作, 可以得到如下的表:
| GROUP | MINTERMS | (A B C D) |
| 0 | (0 8 1 9) | (- 0 0 -) |
| 0 | (0 1 8 9) | (- 0 0 -) |
| 1 | (1 9 3 11) | (- 0 - 1) |
| 1 | (1 3 9 11) | (- 0 - 1) |
| 2 | (3 11 7 15) | (- - 1 1) |
| 2 | (3 7 11 15) | (- - 1 1) |
那么再一次重复, 会发现没有可以列出的表了:
| GROUP | MINTERMS | (A B C D) |
于是可以说, 在执行 2 次之后, 就得到了 Prime Implicant 表. (按照中文维基百科上说的, 叫做素蕴涵. )
总结起来就是:
(defun find-prime-impilcant-of-formatted (grouped)
"Find the Prime Impilcant of GROUPED. "
(labels ((iter (formatted-input)
(let ((res (compare-grouped-nexts formatted-input)))
(if (rest res) ; ALIST of formatted
(iter res)
formatted-input))))
(iter grouped)))
(注: 前文中提到的视频并没有提到一个中止条件的判断, 这里需要强调一下, 当然, 如果你逻辑那部分学得很好并且清楚地知道啥是素蕴涵的话, 当我没说, 毕竟我学得一塌糊涂… )
在做完这一步的时候, 可以说原本的 \(∑ m_i\) 可以被类似 \(\{m_p\}\) 这样的表达式的和 (或) 进行表示.
Step 2: Construct Prime Implicant Table
既然已经得到了最简单的 Prime Implicant 形式,
将其写成 Prime Implicant Table 不过就是一个 format 的工作了:
- 去掉重复的表达式
- 在表格中将表达式对应的
minterm部分做标记
一些代码
因为传入的 Prime Implicants 并不包含完整的 minterms 的信息,
所以需要首先从其中还原出来 (虽然看起来像是很多于的事情就是了).
(defun restore-minterms (prime-implicants)
"Restore minterms from PRIME-IMPLICANTS. "
(let ((body (rest prime-implicants))
(minterm-lst '()))
(labels ((read-minterms (pattern)
(let ((m (nth 1 pattern)))
(if (atom m) (list m) m))))
(loop for group in body
do (loop for pattern in (cdr group)
do (loop for m in (read-minterms pattern)
do (when (not (find m minterm-lst))
(push m minterm-lst)))))
(sort minterm-lst #'<))))
于是构建表就比较轻松了:
(defun construct-prime-implicant-table (prime-implicants)
"Format the PRIME-IMPLICANTS, for convenice"
(let ((vars (nth 2 (first prime-implicants)))
(body (rest prime-implicants))
(minterm-lst (restore-minterms prime-implicants))
(minterm-read '()))
(labels ((make-exp (pattern)
(let ((vals (nth 2 pattern)))
(when (not (find-if (lambda (elem) (equal elem vals))
minterm-read))
(push vals minterm-read)
(cons '∧
(loop for val in (nth 2 pattern)
for sym in vars
if (not (eq val '-))
collect (if (eq val 0) `(¬ ,sym) sym))))))
(read-minterms (pattern)
(let* ((minterms (nth 1 pattern))
(min (if (atom minterms) (list minterms) minterms)))
(mapcar (lambda (m) (if (find m min) 'X '_))
minterm-lst))))
(let ((res '()))
(loop for group in body
do (loop for pattern in (cdr group)
do (let ((minterms (read-minterms pattern))
(logic-exp (make-exp pattern)))
(when logic-exp
(push (cons logic-exp minterms) res)))))
(cons (cons 'LOGIC-EXP minterm-lst)
res)))))
于是可以得到最终的表格:
| LOGIC-EXP | 0 | 1 | 3 | 7 | 8 | 9 | 11 | 15 |
| (∧ C D) | _ | _ | X | X | _ | _ | X | X |
| (∧ (¬ B) D) | _ | X | X | _ | _ | X | X | _ |
| (∧ (¬ B) (¬ C)) | X | X | _ | _ | X | X | _ | _ |
为何构建如此的表格的原因, 在下面将会介绍:
Step 3: Reduce Prime Implicant Table
上面的表格将表达式和其对应的 \(m_i\) 形式进行对应, 并且可以发现一些表达式之间存在重复, 于是只要找到能够覆盖所有 \(\{m_i\}\) 的最小的表达式集合, 将这些集合进行组合就可以描述最小的逻辑表达式了.
显然, 通过穷举不失为一个可行的方法, (注: 在我写了大半代码之后回来看, 感觉还是不如穷举算了… ) 另一种可行的方法可以如下:
- 去掉所有在 \(m_i\) 中仅出现一次标记的表达式和对应的 \(m_i\), 这些表达式是要覆盖 \(\{m_i\}\) 不可或缺的元素
- 在去掉前者的基础上, 根据行和列去消去重复的元素, 消除的策略是尽可能地去消除可以被其他元素表示的项.
Step 3.1 Remove Essential Prime Implicants
对于上面的表格, 按列来看, 一列中只含有一个 X 的标记的行,
显然是一定会包含的必要的项:
- 对列进行计数
- 如果该列有且仅有一个
X标记, 将该标记的表达式从表格中去除 (去除该列).
一些代码
(defun transpose-table (table)
"Transpose input TABLE."
(apply #'mapcar #'list table))
转置的结果
| LOGIC-EXP | (∧ C D) | (∧ (¬ B) D) | (∧ (¬ B) (¬ C)) |
| 0 | _ | _ | X |
| 1 | _ | X | X |
| 3 | X | X | _ |
| 7 | X | _ | _ |
| 8 | _ | _ | X |
| 9 | _ | X | X |
| 11 | X | X | _ |
| 15 | X | _ | _ |
- 首先在表中找到 Essential Prime Implicants:
(defun find-essential-prime-implicants (trans-table) "Find essential parts in TRANS-TABLE. " (let* ((exps (rest (first trans-table))) (rows (rest trans-table))) (labels ((count-X (row) (let ((count 0) (expr NIL)) (loop for val in (rest row) for exp in exps while (< count 2) if (eq val 'X) do (setq count (1+ count) expr exp)) (if (eq count 1) expr NIL)))) (let ((count NIL) (essential '())) (loop for row in rows do (setq count (count-X row)) if count do (when (not (find-if (lambda (elem) (equal elem count)) essential)) (push count essential))) essential))))
- 然后在表中删除 Essential 对应的行:
(defun remove-essential-prime-implicants (table) "Delete essential primes of TABLE, return removed table and essential ones." (let* ((trans-table (transpose-table table)) (essential (find-essential-prime-implicants trans-table)) (title (first trans-table)) (exps (rest title)) (rows (rest trans-table)) (remain-rows '())) (loop for row in rows if (let ((remain-p T)) (loop for val in (rest row) for exp in exps if (and (eq val 'X) (find-if (lambda (elem) (equal elem exp)) essential)) do (setq remain-p NIL)) remain-p) do (push row remain-rows)) (values (delete-if (lambda (row) (find-if (lambda (elem) (equal elem (first row))) essential)) (transpose-table (cons title (reverse remain-rows)))) essential)))
因为视频中的例子没有覆盖所有情况, 第一步去除之后就空了, 所以不太能够说明所有的问题, 换一个例子: \(m(0,2,5,6,7,8,10,12,13,14,15)\).
其去除前的列表如下:
| LOGIC-EXP | 0 | 2 | 5 | 6 | 7 | 8 | 10 | 12 | 13 | 14 | 15 |
| (∧ B D) | _ | _ | X | _ | X | _ | _ | _ | X | _ | X |
| (∧ B C) | _ | _ | _ | X | X | _ | _ | _ | _ | X | X |
| (∧ A B) | _ | _ | _ | _ | _ | _ | _ | X | X | X | X |
| (∧ C (¬ D)) | _ | X | _ | X | _ | _ | X | _ | _ | X | _ |
| (∧ A (¬ D)) | _ | _ | _ | _ | _ | X | X | X | _ | X | _ |
| (∧ (¬ B) (¬ D)) | X | X | _ | _ | _ | X | X | _ | _ | _ | _ |
其去除后的列表如下:
| LOGIC-EXP | 6 | 12 | 14 |
| (∧ B C) | X | _ | X |
| (∧ A B) | _ | X | X |
| (∧ C (¬ D)) | X | _ | X |
| (∧ A (¬ D)) | _ | X | X |
注: 不过我认为用 “去除” 这个词倒是有点不太妥当, 为什么呢? 因为这些去除掉的元素, 原则上来说应该是最终需要保留的项. 以上面的去掉的元素为例, 它们在最后应该作为表达式中的一项进行保留才对.
(注意这里和之后的消除的不同)
Step 3.2 & 3.3 Row & Column Dominance
(注: 因为接下来的操作实际上行列原则上是一样的, 所以这里就用其中一个来表示. )
代码 (建议先看例子后看代码)
(defun remove-dominate (table)
"Remove dominate elements in TABLE. "
(let ((title (first table))
(remain (sort (rest table) (lambda (a b) (exp-leq (first a)
(first b))))))
(labels ((detect-dominate (the-row body)
(let ((the-id (first the-row))
(the-content (rest the-row))
(dominate? T))
(loop for val in the-content
for idx from 1
while dominate?
if (eq val 'X)
do (progn
(setq dominate? NIL)
(loop for row in body
while (not dominate?)
if (and (not (equal (first row) the-id))
(eq (nth idx row) val))
do (setq dominate? T))))
dominate?)))
(loop for idx from 0
while (< idx (length remain))
if (detect-dominate (nth idx remain) remain)
do (progn
(setq remain (nconc (print (subseq remain 0 idx))
(print (nthcdr (1+ idx) remain))))
(setq idx (1- idx))))
(cons title remain))))
注: 这里实际上还应该做一个按照表达式的复杂度进行排序的操作, 然后按照复杂度从高到低进行删除.
(defun exp-greater (a b)
"Compare expressions A and B if A > B. "
(cond ((and (atom a) (atom b))
(if (and (symbolp a) (symbolp b)) NIL (< a b)))
((and (not (atom a)) (atom b)) T)
((and (atom a) (not (atom b))) NIL)
(t (if (> (length a) (length b))
T
(or (exp-greater (nth 1 a) (nth 1 b))
(exp-greater (nth 2 a) (nth 2 b)))))))
(defun exp-leq (a b)
"Compare expressions A and B is A ≤ B. "
(not (exp-greater a b)))
先从列来看: 在上面的结果中 \(m_{14}\) 出现的部分, 在其他的元素中都有出现, 也就是说, 只要其他元素有出现的话, 就可以忽略 \(m_{14}\).
| LOGIC-EXP | 6 | 12 |
| (∧ B C) | X | _ |
| (∧ A B) | _ | X |
| (∧ C (¬ D)) | X | _ |
| (∧ A (¬ D)) | _ | X |
然后从行来看: 同样地可以去消除掉包含有其他元素出现的行, 最后剩下的就是需要进行保留的项了. (注意这里和前面的不一样… )
| LOGIC-EXP | 12 | 6 |
| (∧ A B) | X | _ |
| (∧ B C) | _ | X |
于是问题变成如何找到这样的包含其他元素的项? (这样的项可以被叫做 Dominance 项, 尽管我觉得这个名字很烂, 听起来像是它在支配其他的项, 实际上却是它被其他项支配. )
于是最终剩下的就只有最少的部分了.
Step 4: Solve Prime Implicant Table
于是只需要将剩下的元素提取出来, 就得到了最终的结果了:
(defun simplify-formatted (formatted)
"Simplify the formatted input FORMATTED.
Note: the FORMATTED could be:
+ `strip-zero-and-format';
+ `format-by-minterm-exp'."
(multiple-value-bind (removed essential)
(remove-essential-prime-implicants
(construct-prime-implicant-table
(find-prime-impilcant-of-formatted
(group-formatted formatted))))
(cons '∨
(append essential
(rest (first
(transpose-table
(remove-dominate
(transpose-table
(remove-dominate
(transpose-table removed)))))))))))
又
顺带附送一个格式化输出的函数:
(defun exp-latex-format (exp)
"Export EXP to LaTeX format. "
(labels ((2-to-latex (op)
(lambda (a b)
(concatenate 'string
(exp-latex-format a)
op
(exp-latex-format b)))))
(if (atom exp)
(string exp)
(let ((op (first exp)))
(cond ((eq op '∧) (reduce (2-to-latex " ") (rest exp)))
((eq op '∨) (reduce (2-to-latex " + ") (rest exp)))
((eq op '¬)
(concatenate 'string
"\\bar{" (exp-latex-format (nth 1 exp)) "}")))))))
于是化简结果:
(exp-latex-format
(simplify-formatted
(format-by-minterm-exp
'(minterm '(0 2 5 6 7 8 10 12 13 14 15) '(A B C D)))))
也就是这个结果啦:
\[B D + \bar{B} \bar{D} + A B + B C\]
About the Code
你可以在这里 下载 这个的全部的代码.
代码一般般, 还请随便看看.
免责申明
不过当前的代码基本上还是用于个人了解使用, 难说能不能有很好的效率和所谓的稳定性.
实际上真的好用么?
我不太觉得, 因为在游戏里面的体验并不是很好就是了…
比如计数器那关的代码:
(let* ((pos 1)
(truth-tbl
(cons
'((A B C D) VAL)
(loop for input from 0 to (1- (expt 2 4))
collect (let* ((bits (to-bits input 4))
(count (count 1 bits)))
(list bits
(nth pos (reverse (to-bits count 3)))))))))
(exp-latex-format
(simplify-formatted
(strip-zero-and-format truth-tbl))))
最终化简结果:
\[A B \bar{D} + A \bar{C} D + A \bar{B} C + \bar{B} C D + \bar{A} B C + B \bar{C} D\]
其实也没有多简单, 甚至还有点地狱绘图的感觉…
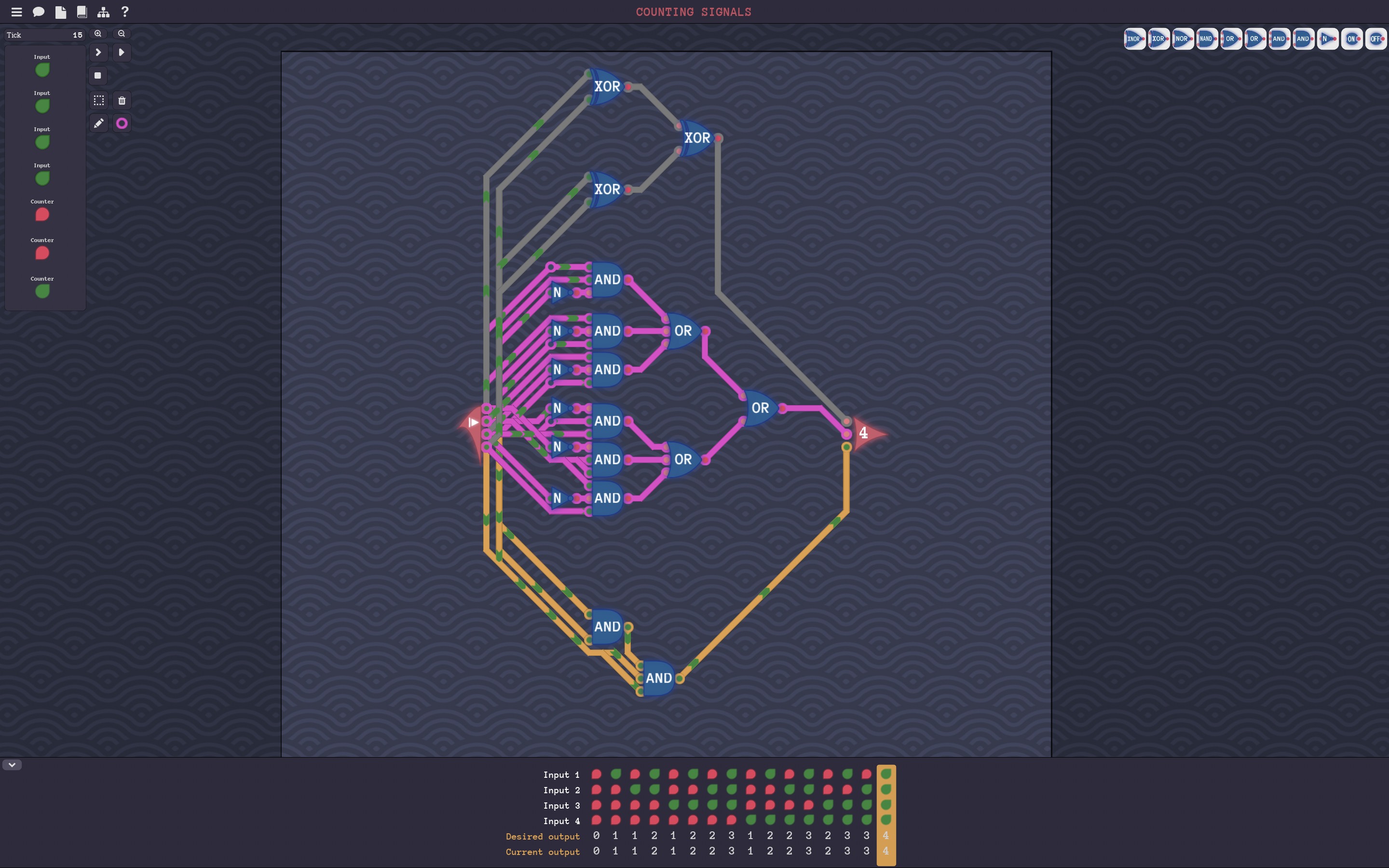
原因我觉得可能是因为只用了两种门而没有用其他的门, 看来这个算法一般般欸. 要是有那种可以根据目标进行简化的算法就好了.
Others
深夜的 EMO
在我调查并编写复现这个算法的时候, 我突然感到了十分的惶恐, 因为在实现这个算法的时候, 我感觉可以看到它的限制了: 那就是它的时间复杂度非常的大. (并且我的代码不能说普通吧, 只能说是完全不太行).
这样的技术是否有像这样掌握的必要呢? 大概是没有的吧, 毕竟早已经有非常成熟的项目实现了, 并且实现了这个玩意, 除了对于我打游戏的某几关可能有那么点用处, 并不能直接给我带来什么有益的帮助. 而最没用的帮助就是它可能会吃掉我不少的时间使得我面临一个非常严重的灾难性的问题:
- 这假期结束了的考试怎么办?
- 这考试前布置的作业怎么办?
淦啊, 他喵的时间安排!
说实在的, 之所以我觉得这个算法有值得一试的可能性, 是因为它很简单, 并且它的基本单元很简单. 一个很简单的程序性的事情, 本来就不应该由人类来完成.
而之所以我没有想过去实现什么数学物理方程里面的计算步骤, 只是因为它们的基本单元并不是那么的好实现. (当然用 Mathematica 加上一堆的条件 Patch 估计能行, 基本上我的作业都是这么实现的, 但是有什么意义呢? ) 这实在是过于痛苦了.
算了, 继续造轮子吧… 管它那么多什么轮子不轮子的.
白天的 EMO?
怎么说呢, 感觉自己学得有点慢… 不仅仅是理解, 编程实现也很慢.
看来研究这种估计已经没什么人搞的技术, 估计唯一的好处就是不会有人来卷我吧 (毕竟已经有成熟的软件提前帮我把他们卷死了).
想到这里, 心情感觉还行. 闭门造车的井底之蛙的快乐还是要有的.
写完代码后又感觉自己行了
嘿嘿.
实际上只剩下一天时间复习了