Basic Emacs for those who are Free
About
标题参考翻译: 给那些竟然还挺闲的人的一个幼稚的 Emacs 介绍.
写这个的原因是因为一直在安利, 却总被 “挖藕~ Vim 耶, 配置很难吧” 为由婉拒.
不是, 好歹也是叫 Emacs 吧
其他关于 “Emacs” 的吐槽
仅有一些摘录, 并不是什么针对, 只是感觉可能很好玩:
- 在 Google 查找 Emacs 的时候, 会弹出一个 “Did you mean vi” 的一个建议;
而在搜索 vi 的时候, 则会是 “Did you mean emacs”…
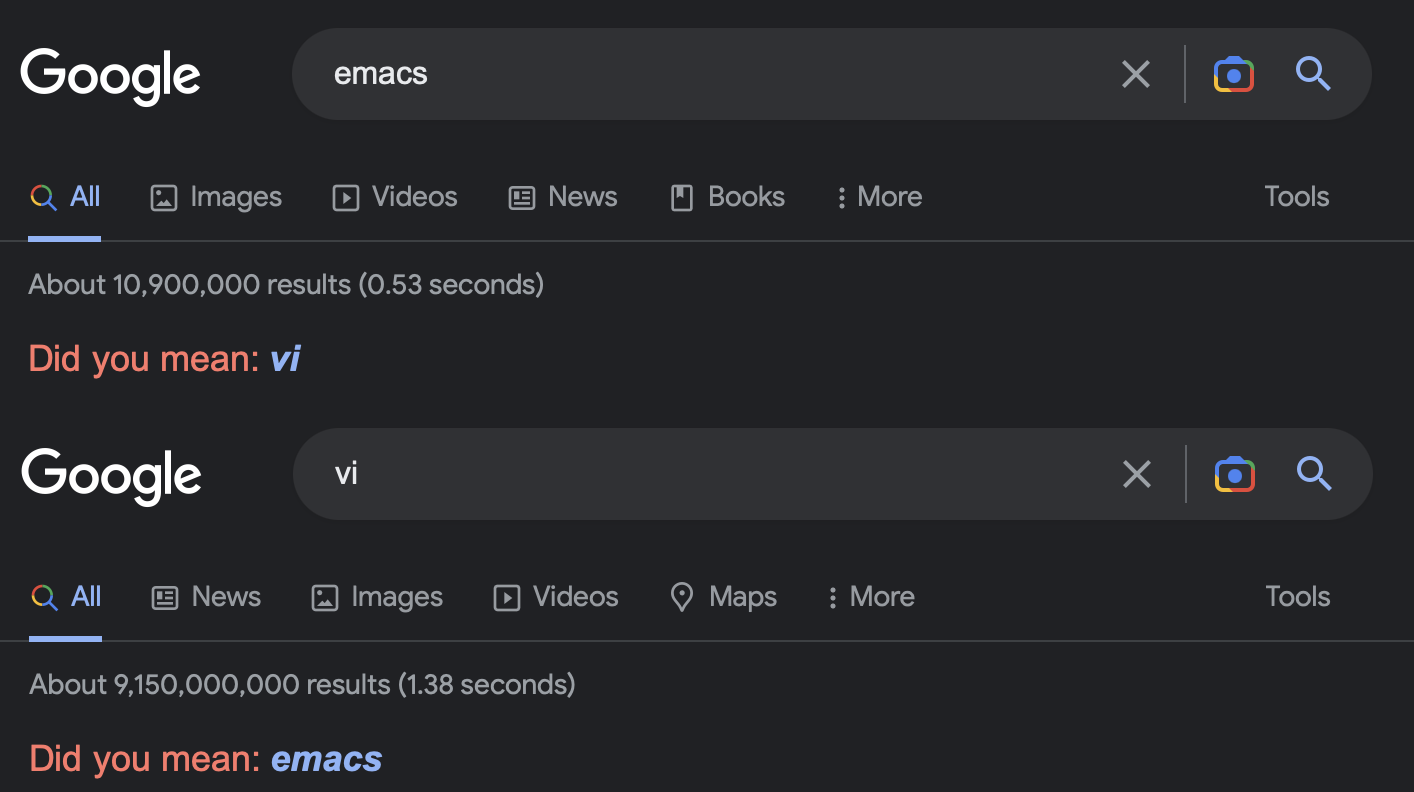
只能说好活…
- 在使用 dashboard 包没有什么配置的时候, 你可以常常在底下的 Quotes 中看到对 Vim 的 diss.
- 也不知道为什么, 一个非常尴尬的事情是, macOS 可能由于其 臭名昭著 的封闭性,
导致了大部分我的同学在看到我使用 Emacs 记笔记的时候, 虽然会觉得还行一软件,
却都会在听到 Emacs (
ee·maks) 之后都会说: 啊, 啊, 苹果 (mac) 专用的吧…啊, 苹果, 你坏事做尽!
(类似的还有 TeXmacs)
遂决定写此, 旨在构造 “最小” 的配置文件, 来实现推销之务.
实际上是临近期中考了, 压力有点大, 找点东西干扰一下注意力
免责声明 (bushi)
注: 本人实际上并未写过多少 Emacs 代码, 也啥也不会, 本文的作用也仅仅只是一个 “差不多得了” 的简单入门教程.
旨在诱拐萌新入坑
如果真的想要上手 Emacs 并且非常精通, 或者是想要看更加详细的教程, 获得更多的帮助, 请看:
- 【新手教程】一个面向产品经理的Emacs新手教程
一个有点 “标题党” 的教程, 因为里面的内容绝对不只用于产品经理, 目前看来是一个非常简单容易上手的教程, 现在重构的配置建立在这个教程的基础上.
- 21 天学会 Emacs
最开始我看的教程, 也是非常棒的一个教程.
- Emacs 自力求生指南 ── 来写自己的配置吧
实际上当前我的大部分配置的根本来源于这个网站的教学.
- AbstProcDo/Master-Emacs-From-Scratch-with-Solid-Procedures
- Emacs 入门指南:Why & How
- Emacs China
一个好论坛, 常常潜水也可学到很多东西
- awesome-emacs 一个 Emacs 相关的列表.
先看疗效
作为一个水平不咋样, 又菜又爱玩的垃圾, 我也能很轻松地配置出如下的效果:
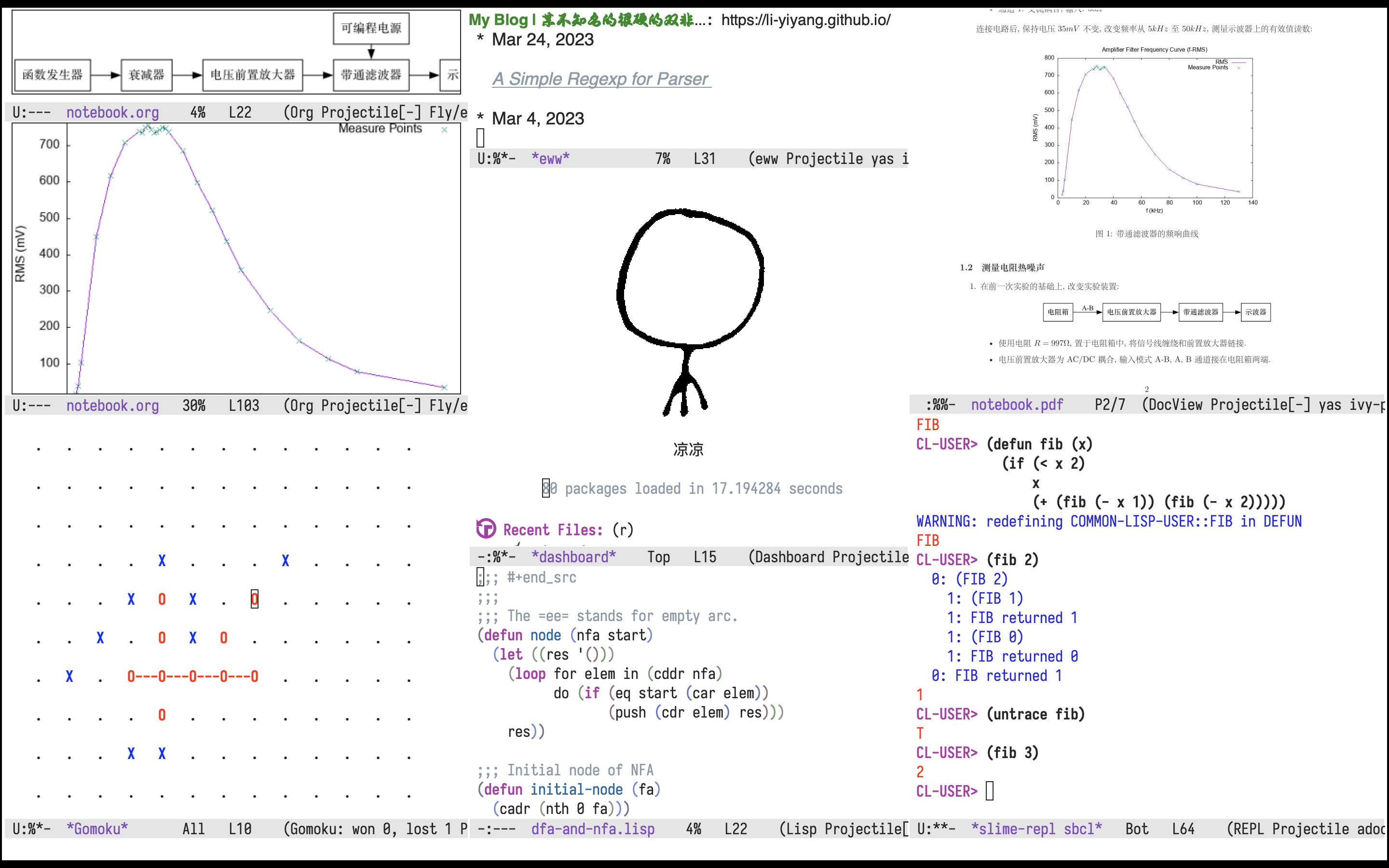
(注: 平时使用的时候并不会这么夸张地开这么多的窗口的, 只是为了演示而已. 实际上, 如果你花一些时间, 基本上都能够做到和我演示的效果差不多. )
一些说明
在上图中使用到的 Emacs 的功能:
Installation
如果啥也不想管
下面的这一堆是不是看起来很可怕?

如果什么也不想管, 可以尝试直接下载安装已经提前打包好了的各种版本:
- macOS
- emacsformacos (Up to: 30)
- emacs-builds (Release: 28.2)
- Windows
不过一个比较尴尬的事情就是可能这样会更加麻烦就是了…
因为一些打包的版本都感觉非常的老旧, 用的 Emacs 版本还挺老的… 尽管这些打包的版本里面都把配置写好了, 属于是无脑使用, 比如很多日本的大佬魔改了 Emacs (我能找到的大多在 24~25 左右的版本), (感觉有点像是一个研究室里老师实在懒得给学生配环境, 一气之下直接自己打包了一个分发给学生用的感觉…). 一个可能的猜测是之前对 CJK 字符集支持不太好, 所以需要比较多的修改?
不过也可能够是我没有用过, 不能肯定就是了.
对于 mac 用户且正在使用 homebrew 的用户, 可以选择无脑安装 emacs-plus:
> brew tap d12frosted/emacs-plus
> brew install emacs-plus
稍微详细一点的说明补充
- 当然, 你可以选择添加一些可能的参数 (在 emacs-plus 仓库里面有介绍).
比如我使用的参数貌似 (太久了, 忘了, 不过基本上不会有太多差别的) 有:
> brew install emacs-plus@30 --with-xwidgets --with-imagemagick
--with-xwidgets在编译的时候加入xwidgets支持, 好处是可以在 Emacs 里面看网页, 坏处是貌似也只有这么些, 不如 EAF. (虽然这两个我都没怎么用过)--with-imagemagick在编译的时候加入imagemagick支持, 好处是可以增加图片处理功能.
- 其他可以选择的是 emacs-mac:
> brew tap railwaycat/emacsmacport > brew install emacs-mac
甚至还有打包好 Release 可以直接下载…
Linux 用户可以在自己的包管理器上直接安装. Windows 用户可能可以考虑按照 Download & Install 中所写的, 通过 GNU Mirror 上的包来安装.
如果想更狠一点?
当然, 有能力和愿意折腾的可以考虑从源码进行编译, 这样的自由度更大 (甚至有通过往里面编一个 OpenGL 的方式来实现在 Emacs 中进行图形学的一些 折腾 (emacs-gl)). 不过对于我来说, 因为没有用过, 也不会, 所以就不展开了.
一般来说, 建议的是直接上最新的呗. Harder Better Faster Stronger
(注: 不过建议可以试试 Emacs 29 以后的版本, 其中直接内置了很多的包, 用起来感觉很爽. )
The Very First Step(s)
The Ultimate First Step: To Open Emacs
当然, 前面还有 Ultimate Pro Max First Step: 打开电脑 ;p.
然后, 打开 Emacs.
虽然这可能听起来像是茴香豆的 “茴” 字的几种写法的感觉. 但是实际上还是有一些微妙的区别的. (因为我只有 macOS 系统, 所以下面的全部以 macOS 为例, 不过 Linux 和 Windows 应该差不多.)
- 点击图标打开 – 这, 好像, 没什么吧…
- 命令行
emacs打开 (图形界面, 和上一条效果一样), 好像也没什么吧… - 命令行
emacs -nw打开终端界面 (nw代表no window) - 命令行
emacs -q使用无配置进行启动更进一步
emacs -Q, 请自行观察区别 (bushi)[答案:
-Q了之后啥都没了, 直接进入*scratch*, 即在不加载.emacs.d,.emacs,default.el的基础上, 还不加载site-start.el. ] - Emacs Server 和 Emacs Client: 将 Emacs 作为服务在后台运行,
通过
emacsclient连接进入. (没怎么用过, 毕竟我开了 Emacs 之后就基本不关了, 并且目前也没有远程服务器的需求… ) cd $(dirname $(realpath $(where emacs))) && pwd嗯, 如果你在想 “打开” emacs 的话…
此时你应该看到如下类似的界面 (我使用的是 emacs -q 启动):
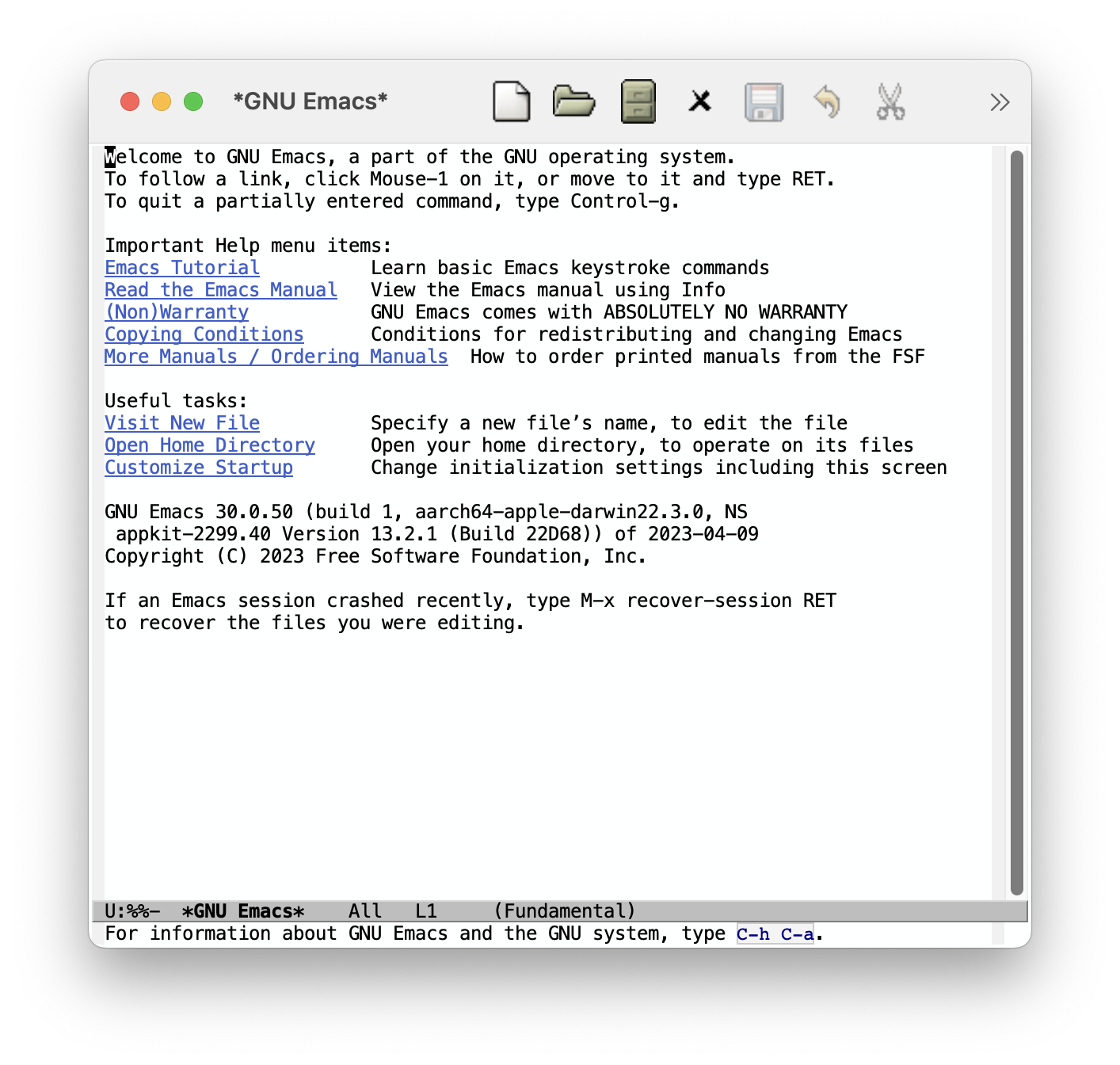
嗯, 丑得就像是个原装 vi (bushi). 但是这可不代表它像 vi 一样不好用.
Oh, Yeah, You can Still Use Mouse, Why NOT?
在 Emacs 里, 你当然可以继续使用鼠标进行点点点的操作.
只是习惯了之后还是觉得快捷键操作更爽呗… 大家难道不是都习惯 =Ctrl-S= 保存么?
(上面的是打开文件的一个截图. 注: 图片有所编辑, 但是差不多就这样. )
关于快捷键
你可以使用快捷键进行很多的操作, 但是可能在不同的系统上会遇到不同的坑:
- 在 macOS 上, 可能你会遇到 Option 键 (
Meta) 加按其他键的时候会被系统拦截并转换为一些特殊的字符. 比如按下 Option+x (M-x) 键, 你会输入≈.这个时候就可能需要一些折腾了 (不过因为太久没遇到过了, 所以不太清楚怎么解决. ) 祝你好运 (苦笑)…
- 一些快捷键可能会被系统占用, 比如在全屏的时候按下
Esc键有机率触发退出全屏事件, 不过也有可能是因为窗口失焦导致Esc没有被 Emacs 捕获. 因为出现得比较少, 所以就懒得管了. - 按快捷键可能对你的指头有一些压力和一些不可逆的影响:
比如会习惯性地按下
Esc来取消, 按下hjkl来试图在其他应用中移动光标… 并且某些按键确实不太容易按到, 一个富贵的解决方法是通过买一把高级的人体工学键盘, 一个穷鬼的做法是直接修改按键 (推荐 Karabiner macOS), 比如把从来没用过的大小写按键换掉之类的… 好处是非常自定义, 坏处是如果你把键位乱换, 别人上你的电脑就会一通乱按, 然后说, 啊, mac 真是高贵啊… - 来统一一下对这些快捷键的叫法吧:
- Meta 键: 在我的电脑上是 Option 键,
在各种关于 Emacs 文章中看到的
M就是 Meta 键. - Ctrl 键: 在我的电脑上是 Control 键,
在各种关于 Emacs 文章中看到的
C就是 Ctrl 键. - Super 键: 在我的电脑上是 Command 键,
在各种关于 Emacs 文章中看到的
s键就是 Super 键. - 连招: 正如街霸系列中的连招一样 (音速手刀: ←蓄→+拳, 来源网络, 不一定对),
在 Emacs 里面, 想要打出一套华丽的攻击技, 不可缺失的也是快捷键组合.
比如
C-x C-f,C-x b等等.那么想要打出这么一套攻击, 首先要学会看 “谱”:
- 使用
-连字符来表示同时按下, 如s-s表示同时按下 Meta 键和 s 键. - 使用空格符来分割两次按键, 如
C-x C-f表示按下C-x后再按下C-f键.
当然, 如果想要了解更多, 或者了解当前的按键是啥, 建议使用
C-h k为打开按键帮助界面. - 使用
- Meta 键: 在我的电脑上是 Option 键,
在各种关于 Emacs 文章中看到的
那么你已经会使用鼠标对 Emacs 进行操作了, 就像使用记事本一样使用它吧.
(还真别说, 一助教有一次还真跟我们说他偶尔用记事本来写代码… 强者如斯…)
Oh, You mean Seriously, You want a BETTER Experience?
没问题, 你并不需要做多少牺牲便可以获得很棒的体验, 不如先从国产游戏最喜欢的换皮开始练习吧:
- 按下快捷键
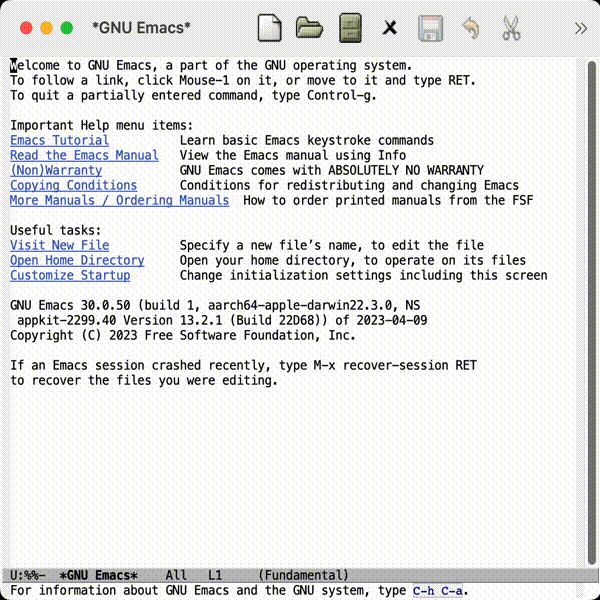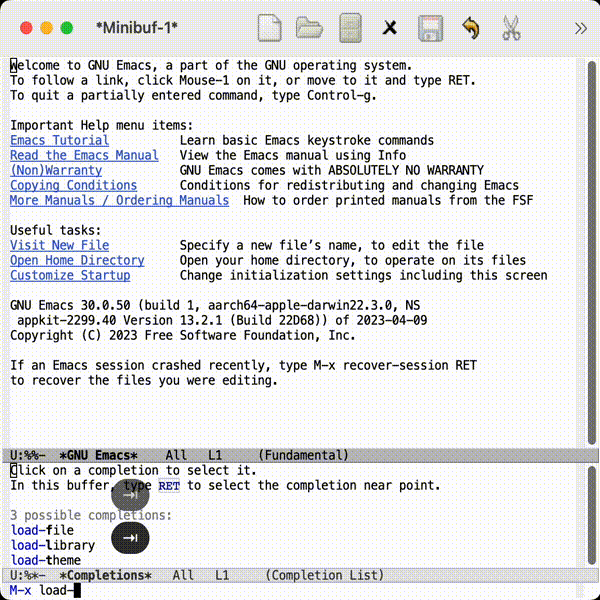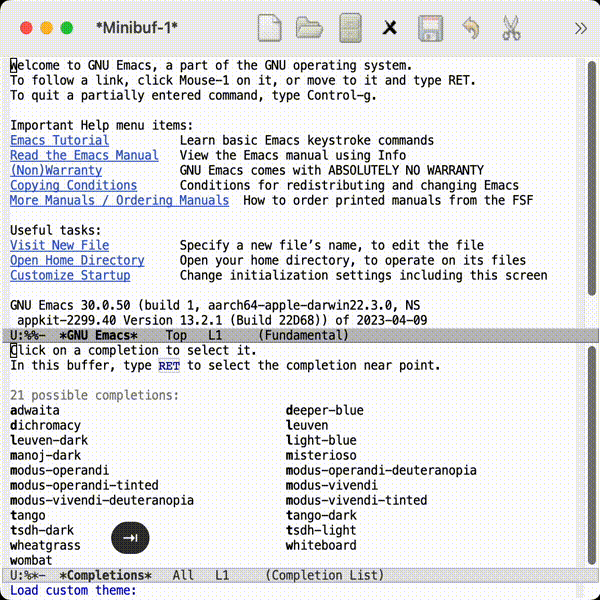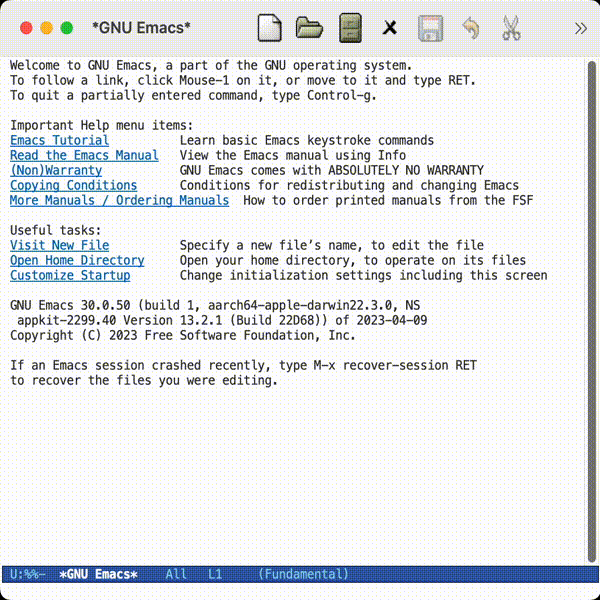
M-x, 你会发现窗口下方的空间发生了一些小小的变化, 在最下方的空间出现了一个M-x的提示符, 并且你的光标移动到了它的后面.这个 “下面的空间” 被叫做 Mini-buffer, 这个 Mini-buffer 里面会显示消息, 可以进行互动等等.
一个粗浅的类比的理解便是 VSCode 中的
C-P栏 + 状态栏 + 消息框, 以及 Vim 中的命令栏.当然, 如果你觉得命令输入错了也没有关系, 按下
C-g可以取消. 类似于 Vim 中万能的ESC键吧 - 哪怕什么也没有配置, 你也可以轻松地使用很多 Emacs 内置的小工具,
比如此时你可以在输入
lo之后按下 Tab 键进行补全, 或者继续按下 Tab 展开补全提示等等. load-theme是 Emacs 的一个命令, 可以载入一个主题样式, 比如上图中使用的leuven主题. (你可以自行切换选择一个自己喜欢的)
现在这个界面看起来更加漂亮一些了. 假如现在是新手教程的话, 那么这应该就是你捡到了一根树枝, 一个在火堆旁的老头 NPC 烤着苹果, 然后跟你说: 哦, 年轻人, 你的这把武器, 看起来还挺顺手, 挥一挥手看看吧. (哦! 该死, 不要玩火啊! )
希望东半球最强法务部能够放我一马… 我只是一个在初始台地都被薄纱的菜狗
你现在学到的是使用
M-x执行命令 (函数)load-theme. 并且正如在上面的动图中所看到的, 使用M-x可以执行的命令有很多, 不过你并不需要知道所有的命令就可以轻松使用它们.(注: 一个温馨提示, 如果你在输入命令的时候发现了问题, 可以使用
C-g来取消. )
你可能会觉得, 一步步执行命令就像是在搬砖, 感觉很麻烦, 假如都是这样配置的话, 那么重启 Emacs 之后不就还要再来一次么? 这不是太麻烦了么?
所以一个简单的做法便是将这些命令写在一个配置文件
(建议放在 ~/.emacs.d/init.el 中, 原因见下方的说明) 里面,
(这个配置文件在 Emacs 每次启动的时候都会被执行),
那么这便是你开始拥抱自动化的真正的第一步了.
关于配置文件
实际上 Emacs 在启动的时候会去特定的位置寻找配置文件, 这些文件可能在:
~/.emacs即当前用户的根目录下的一个叫.emacs的文件~/.emacs.d/init.el即当前用户根目录下.emacs.d文件夹中的init.el文件
在历史上, .emacs 是最早的, 所以如果你在配置文件的时候, 发现自己的配置不会被执行,
可以考虑是否存在 .emacs 文件导致 Emacs 发现了 .emacs
文件之后就不会主动去读取其他的位置的配置了. (别问我为什么说这个)
但是像 .emacs 这样和 .vimrc 这样的一个文件写配置的方法,
虽然简单粗暴, 但是十分的不容易维护 – 尤其是当你的配置文件非常长的情况下.
现代的配置方式一般是将配置在 .emacs.d 文件夹中进行组织,
并通过 init.el 作为入口进行调用. 可以的配置方式有很多种,
比如通过 org-mode 进行组织等等.
不过本文可能并不打算介绍这些, 如果有兴趣, 请了解一下 org-tangle 或者可以看看我的 配置 (虽然很烂).
不过相比直接在配置文件里面动手然后通过反复重启的方式来进行配置, 为什么不尝试通过测试代码能否工作 (在一个 playground 里面), 然后在确认后再写入配置呢?
那么这个 playground, 在哪里呢? 答案就是 *scratch* buffer:
什么是 Buffer, Frame, Window? 以及 scratch? 是什么?
实际上严格的定义我也不懂.
- Buffer 有点像是一个文件打开之后的存放空间. 在 Emacs 中对文件的修改实际上更像是对 Buffer 的修改, 在保存 Buffer 的时候则像是将 Buffer 中的数据写入磁盘.
- Frame 有点像是打开的 Emacs 的窗口而 Window 更像是在每个 Emacs 中,
分隔出的每个分屏. 这两个听起来挺容易让人搞混的.
(我是这样理解的: Emacs 的 “Window Manager” 是管理一个 Frame 中的所有的窗口. )
- 每个 buffer 都有一个自己的主模式 (major-mode), Emacs 根据不同的模式会进行不同的操作.
主模式下会有一些小模式 (mini-mode), 用来拓展主模式的功能.
使用
C-h m快捷键 (C-h为帮助快捷键进入口, 可以追加说明或者追加?来打开相应的帮助) 可以查看当前模式. *scratch*buffer 的主模式是Lisp Interaction mode使用eval-buffer命令可以将*scratch*里面的代码运行.或者可以通过将光标移动到命令上, 按下
C-M-x快捷键执行该条命令.
- 上面的操作中, 使用
switch-to-buffer命令来进行切换当前 Window 显示的 Buffer.实际上, 正如在切换后下方 Mini-buffer 显示的那样, 可以使用
C-x b来进行切换. (我会更加倾向于使用这个方法). 当然, 也可以从菜单的 Buffer 下拉栏选择对应的 buffer, 不过用得很少就是了.不过我为了图省事, 直接使用回车键切换了提示的默认
*scratch*, 你也可以使用 Tab 键来进行补全提示. - Emacs 使用 elisp 来进行配置, 尽管是个 “邪恶” 括号语言 (Lisp 方言),
但是如果你看多了的话, 实际上括号便不是一个什么大事了. 多么眉清目秀呢… (bushi)
(load-theme <theme>)这条命令, 实际上就是在使用M-x load-theme时做的事情, 只是相比于interactive模式下的交互式的操作, 现在你只需替换掉<theme>即可更换.- 并且更棒的是, 在你输入错误的时候, Emacs 会告诉你在哪里出了茬子.
(比如在输入
(load-theme 'leuven-this-is-not-exist)的时候, 我们提供了一个并不存在的符号名字, 所以在最下方会有一个提示. ) - 注: 所谓的 “符号名字” 指的是用一个单引号开头的东西 ='=,
或者你可以用
(quote ...)的完整形式来进行表达, 但是为什么不省点力气呢?
- 可以使用
eval-buffer来运行整个 Buffer 中的代码, 或者使用C-M-x来运行光标所在位置的代码. (后者我觉得比较方便就是了)
于是将上面的这段代码写进 ~/.emacs.d/init.el 中,
你就开始进入了 Emacs 的配置之路了 (bushi).
(外一则) Emacs 配置笑话
Vim 用户已经将代码写完了, Emacs 用户还在配置编辑器.
但是先别急着重启你的 Emacs, 籍希望于重启解决一切的操作并不是很好呢,
在 Emacs 中, 更加优雅的做法是通过动态地拓展编辑器,
比如通过 load-file 的方式来重新载入 init.el. 这就比较不错.
啥是动态的拓展?
就我本人的使用经历的普通的理解:
- 之前用过一些 Ruby, 里面的 REPL 用得很爽,
唯一可惜的是编辑代码的功能太不舒服, (最近版本的加入了一个自动补全,
感觉做得不能说好也不能说差, 就是有点怪怪的… )
最后变成了使用 pry 里面的
edit方法调用 nvim 来编写代码.但是那种写完代码立刻就能够修改部分, 并且得到反馈的感觉很好. 至少用那样的方式写的代码在 debug 的时候还是很快乐的. 比那种写完, 运行, 然后通过步进跟踪打断点狂
print的好多了.比如可以在 Emacs 里面使用
ielm来打开一个 REPL. - 在我一开始上手 Emacs 的时候, 每一次想要更新的时候都会去重启一下,
现在看来就是很浪费时间. 因为菜, 所以配置启动大概要十几秒,
来回启动真的很浪费时间. 并且经常会出现配置崩了要用 vim 来修.
当然, 这里还有一个我一开始的误区, 大概是用 VSCode 里面引入的吧… 因为在 VSCode 里面卸载部分的插件想要它失效就需要重新启动. (诶, 只要在 Emacs 里面把这个 mode 给关掉不就好了, 重新启动, 何必呢? (bushi))
并且现在开始有一点点开始慢慢开始组合已有的代码进行拓展了, 目前的一个想法是, 与其把一把武器 (比如一把小刀) 用到炉火纯清, 不如将这个武器和其他的工具结合起来去减少我的一个负担.
- 那么感觉好像还是没有给出 “动态拓展” 的很严谨的一个说法,
感觉只有主观的感情输出是吧. 那还是客观一点来看吧…
感觉客观不出来啊, 我又不搞计算机, 哪里憋得出那么多客观的评价名词啊.
- 所以等我以后会用 Emacs 之后再好好想想如何描述它的动态性吧.
所以, 啥括号语言?
一些碎碎念
初めてのルーブルは
なんてことはなかったわ
私だけのモナリザ
もうとっくに出会ってたから
One Last Kiss
也许第一次见到 Lisp 的时候, 你会觉得这个语言非常的古怪. 怎么所有的东西都是括号, 太可怕了.
当然, 如果你脑子里想的是 One Last Kiss 的话当我没说…
但是实际上, 用惯了 Lisp 之后, 你可能会逐渐觉得括号好像并不是很重要, 甚至渐渐地, 你可能会选择性忽略这些括号 (毕竟可以交给程序来辅助你闭合括号).
这里会用一些非常简单的例子来进行 “新手教学”, 倘若想要跳过这又臭又长的新手教学的话, 可以跳过本节.
一个比较不负责任的说法: 一个 Lisp 的语法大概只有两个,
至少我会的就只有两个, 一个是 list, 另一个则是 atom.
Recursive Functions of Symbolic Expressions and Their Computation by Machine, Part I
以下是 Recursive Functions of Symbolic Expressions and Their Computation by Machine, Part I 这篇文章的一个摘录和简短的翻译. 仅仅只是类似于一时兴起的无聊翻译, 大概仅仅是因为我考完试太闲了吧.
因为不是事无巨细的翻译, 所以想要看完全文的, 或者觉得翻译得狗屎一样的话, 还请直接看原文. 我的翻译会加上自己的恶俗的一些修改和注记.
注: 在我翻译完了之后, 感觉, 这篇论文一定得多来几遍, 直到最终能够实现一个 LISP 机. 只可惜目前我还没有能力做到, 等我有这个水平了之后, 一定要实现一个. 嗯.
- Introduction
我们希望这个形式系统的作用不仅仅是一门编程语言, 而能够作为通用计算机计算理论的一个基石.
- Functions and Function Definitions
[我觉得里面的一段话还挺有意思的]
We shall need a number of mathematical ideas and notations concerning functions in general.
[谁说数学对计算机没用的啊, 摊手~ 尽管我真说不上来这些和数学有什么关系… 听起来就像是来碰瓷数学的玩意. ]
- Partial Functions
一个局部函数仅在其作用域 (domain) 中有作用. 比如在 Emacs Lisp 中这样的表达式:
(let ((partial-functions (lambda (x) (+ x 1)))) (funcall partial-functions 1))
或者采用 Common Lisp 类似的语法:
(cl-labels ((partial-functions (x) (+ x 1))) (partial-functions 1))
- Propositional Expressions
[不太会翻译这个, 维基百科上和数学相关的词条 Proportionality 是数学中的比例, 但是感觉又并不是这样的… 翻译成关系表达式算了. ]
一个判断函数 (predicate, 貌似也有翻译成谓词的?) 的返回值为
T(真) 或者F(假). - Conditional Expressions
[条件表达式和前面的关系表达式不同, 其作用更像是一个选择功能, 根据判断函数的返回值来选择不同的值作为映射.]
用数学的定义来说:
\[(p_1 → e_1, \cdots, p_n → e_n)\]
即若判断函数 \(p_i\) 的返回值为真, 则条件表达式的值被映射为 \(e_i\). 显然, 可以通过 \((p_1 → e_1, \cdots, p_n → e_n, T → \mathrm{fall\ back})\) 的形式来处理默认情况. 使用 \(\frac{0}{0}\) 可以用来表示 undefined (未定义).
在 Emacs Lisp 中, 可以这样来写:
(cond (p1 e1) (p2 e2) (t fall-back))
- Recursive Function Definitions
表达递归的能力, 即一个函数可以被递归地定义和调用.
比如一个数值计算平方根的函数定义: \(\mathrm{sqrt}(a, x, ε) = (|x^2 - a| < ε → x, T → \mathrm{sqrt}(a, \frac{1}{2}(x + \frac{a}{x}), ε))\)
- Functions and Forms
在数理逻辑之外的数学中, 使用一个表达式, 比如 \(y^2 + x\) 来 “不那么确定地” 表示一个函数, 因为虽然我们最终总是能够通过对表达式的计算来确定一个函数的值, 但是如果在之后想要将函数作为表达式中的一个元素 [也就是 Lisp 中常见的高阶函数, 即函数的函数], 这个时候, 仅仅使用普通的表达式就不太够了. 所以引入 Church 提出的 \(λ\) 表达式:
若 \(\mathcal{E}\) 是一个由 \((x_1, \cdots, x_n)\) 组成的表达式, 那么用 \(λ ((x_1, \cdots, x_n), \mathcal{E})\) 来表示一个 \(n\) 元函数.
而在求值时, 其所做的就是一个按照顺序替换符号的操作, 如 \(λ ((x, y), y^2 + x) (1, 2) = 1^2 + 2 = 3\).
更加形式化的说法就是, 在 \(λ\) 表达式的变量列表 \((x_1, \cdots, x_n)\) 中的符号, 被称为哑指标 (dummy variable 或者 bound variable). 一个哑标是局部绑定的名字, 可以被自由地替换为其他的名字, 如: \(λ (x, x) = λ (y, y)\).
与之对应的是不在哑指标列表中却在 \(\mathcal{E}\) 中的变量, 称其为自由变量 (free variable).
[这个解释我觉得可能不是很清楚, 正如文中所说的, 可以用数学中的解释来理解, (但是文中没写), 所以我从数学里面抄来了下面的定义]
Dummy Variable (Wolfram MathWorld)
A variable that appears in a calculation only as a placeholder and which disappears completely in the final result.
- Expressions for Recursive Functions
使用 \(λ\) 表达式, 原本的函数应当写成类似如下的形式:
\[\mathrm{sqrt} = λ ((a, x, ε), (|x^2 - a| < ε → x, T → \mathrm{sqrt}(a, \frac{1}{2}(x + \frac{a}{x}, ε)))\]
但是在 \(λ\) 表达式中, \(\mathrm{sqrt}\) 的名字是未知的
[因为还没有定义名字, 尽管可以做成将名字保留, 在运行时查找, 类似于下面这样, 类似于将 \(λ\) 表达式推迟计算. 可能会遇到运行时环境名字查找的一个困难. ]
(let ((f (lambda (x) (if (< x 2) x (funcall f (- x 1)))))) (funcall f 5))
为了更加形式化地来表示引入记号 \(\mathrm{label}(a, \mathcal{E})\) 来表示: 在表达式 \(\mathcal{E}\) 中的符号 \(a\) 是存在在由 \(\mathrm{label}\) 确定的一个空间中:
\[\mathrm{label}(\mathrm{sqrt}, λ((a, x, ε), (|x^2 - a| < ε → x, T → \mathrm{sqrt}(a, \frac{1}{2}(x + \frac{a}{x}, ε))))\]
可以发现, \(\mathrm{label}\) 中的 \(a\) 是哑标, 可以被形式地替换而不改变原意, 但是要注意, 其和 \(λ\) 表达式中的哑标的功能实际上还是有一些不同的.
[请放心, 上面的名词我全部都是瞎翻译的, 如果有高人说我翻译错了的话, 那肯定是翻译错了, 嘿嘿.]
- Partial Functions
[接下来就是一堆对 Lisp 中的函数的形式和功能的定义了, 实际上还是非常有意思的. 可以说, 这部分就是对 Lisp 该如何被解释的一个解释. 嘿嘿, 这里有一个文字游戏: 最后一个 “解释” 指的是]
- Recursive Functions of Symbolic Expressions
- A Class of Symbolic Expressions
使用如下符号
\[.\] \[)\] \[(\]
以及一组数量无限的相互可分辨的单元符号 (an infinite set of distinguishable atomic symbols).
[注: 在论文中的单元符号的定义是由于其对 List 定义的形式导致的, 因为当时使用的 List 的形式通过
.符号 (或者说, 是后来的 =,=) 来分隔每个元素, 和现在的使用空格的方式不同. 所以其单元符号是由大写的拉丁字母, 数字和单个空格 (非多个连续空格) 来组成的.][作为 “稍微现代一点的人”, 我们可以放一下马后炮, 在 Lisp 里面, 基本上只要你想, 实际上可以使用 “几乎” 任何的符号来作为一个合格的单元符号:]
(cl-labels ((我 (谓语 宾语) (funcall 谓语 '我 宾语)) (吃 (人 东西) (message (format "%s吃了%s" 人 东西)))) (我 #'吃 '🍚))
[上面的代码写得并不是很漂亮, 实际上我觉得如果可以的话, 估计可以变得很人性化, 欸, 突然想到一点, 所谓的中文编程, 这样来实现也不是不可能嘛… 并且中文的灵活性也很符合前序表达式, 比如:]
(令 ((求和 (方术 (表) ; (let ((求和 (lambda (表) (使缩并之 #'相加 表)))) ; (reduce #'+ 表)))) (求和 1 2 3 4 5)) ; (求和 1 2 3 4 5))
[于是在这些基本元素 – 用编译原理的感觉来说就是 tokens, 或者有点像是图灵机中的接受字符集的一个感觉 – 之上, 就可以用来构造语言的规则 – 类似于上下文无关语法.]
- Atomic Symbols [单元符号] 是 S-expression
- 如果 \(e_1\) 和 \(e_2\) 都是 S-expression, 那么 \((e_1 . e_2)\) 也是 S-expression.
使用 EBNF 的形式来写就是:
S-EXP ::= ATOMIC-SYMBOLS | (S-EXP . S-EXP)将满足这样的规则的元素称为 S-expression (S 表示 Symbolic [欸, 我以前还以为是 Superior, 前级, 前置的意思]).
于是对于 Lisp 中最基本的元素 List \((m_1, \cdots, m_n)\) 就可以用如下的形式来实现了:
(m1 . (m2 . (… (mn . NIL)))). 其中NIL是一个用来表示中止的一个记号.[在不同的 Lisp 实现中,
NIL这个符号对应的值是不一样的, 虽然在学习不同的 Lisp 的时候可能会有点尴尬. 在 Emacs Lisp 中,NIL和 ='()= 一个空 List 是等价的. ]下面是一些将书写的 List 转换为 S-expression 的表示:
(m)表示(m . NIL)(m1, m2, …, mn)表示为(m1 . (… (mn . NIL) …))(m1, …, mn · x)表示为(m1 . (… (mn · x) …))
- Functions of S-expressions and the Expressions That Represent Them
[在 S-expression 中的函数和函数的表示方式]
为了区分处理 S-expression 的函数的表达式和 S-expressions, 通过使用 M-expressions (Meta-expression) 来作为表示方法: 将函数和变量使用小写字母来表示. 并用
[]来表示传入参数, 通过;来分隔传入的参数.[注: 这里的 M-expressions 是对 S-expression 进行处理的函数, 举一个比较简单的类比作为例子: Meta-Language, 用来表述其他语言的语言, 在 Lisp 里面, 常常会有类似的一个思想. 并且有点像是编译器的自举]
- The Elementary S-functions and Predicates
一些最基本的函数和判断函数:
atom[X] = T,atom[(X . A)] = Feq[x; y] = T当且仅当x和y是相同的符号 (是符号且相同eq[X;(X . A)] = undefined)car[lst]取lst = (X . A)中的X部分cdr[lst]取lst = (X . A)中的A部分cons[x;y]使得cons[e1;e2] = (e1 . e2)
car,cons, 这样的函数的名字现在看起来并没有什么记忆上的用处, 在了解了其在计算机中的表示方式之后, 估计会容易理解一些. - Recursive S-functions
递归定义的 S-functions [实际上这部分很无聊也很有意思]:
ff[x]得到 S-expression 中, 不考虑括号关系的第一个元素, 如ff[((A . B) . C)] = A.可以有如下的定义:
\[\mathrm{ff}[x] = [atom[x] → x; T → \mathrm{ff}[car[x]]]]\]
[使用 Emacs Lisp 可以得到]
(defun ff (x) (if (atom x) x (ff (car x))))
subst[x;y;z]用x将在z中出现的所有的y替换掉, 如subst[(X . A);B;((A . B) . C)] = ((A . (X . A)) . C).可以有如下的定义:
\[\mathrm{subst}[x;y;z] = \left[\begin{matrix}\mathrm{atom}[z] → [\mathrm{eq}[z;y] → x; T → z]; \\T → \mathrm{cons}[subst[x;y;\mathrm{car}[z]]];subst[x;y;\mathrm{cdr}[z]]]]\end{matrix}\right]\]
[写成 Emacs Lisp 代码如下]
(defun subst (to from s-exp) (if (atom s-exp) (if (eq s-exp from) to s-exp) (cons (subst to from (car s-exp)) (subst to from (cdr s-exp)))))
equal[x;y]若x和y有相同的 S-expression, 则返回T, 和eq[x;y]不同的是, 它不仅能够匹配 atomic symbol, 匹配的是 S-expression. 其定义可以写作如下:\[\begin{matrix}\mathrm{equal}[x;y] & = & [\mathrm{atom}[x] ∧ \mathrm{atom}[y] ∧ \mathrm{eq}[x;y]] \\ & ∨ & \left[\begin{matrix} & ¬ \mathrm{atom}[x] ∧ ¬ \mathrm{atom}[x] \\ ∧ & \mathrm{equal} [car[x];car[y]] \\ ∧ & \mathrm{equal}[ \mathrm{cdr}[x]; \mathrm{cdr}[y]]\end{matrix}\right] \end{matrix}\]
[使用 Emacs Lisp 来写就是]
(defun equal (x y) (or (and (atom x) (atom y) (eq x y)) (and (not (atom x)) (not (atom y)) (equal (car x) (car y)) (equal (cdr x) (cdr y)))))
于是在这些函数的基础上, 可以定义:
null[x] = atom[x] ∧ eq[x;NIL]cadr[x] = car[cdr[x]]
等等的缩写和助记方式.
并且对于定义成 List 的 S-expression, 下面的这样的公式有很多的实用之处:
[比如对 List 列表进行操作的一些函数]
append[x;y] = [null[x] → y; T → cons[car[x]; append[cdr[x];y]]]将两个 List 连接在一起.
(defun append (x y) (if (null x) y (cons (car x) (append (cdr x) y))))
among[x;y] = ¬null[y] ∧ [equal[x;car[y]] ∨ among[x;cdr[y]]]检测一个元素
x是否在y中:(defun among(x y) (if (not (null y)) (among x (cdr y)) NIL))
[以及对所谓的键值对进行操作的函数, 以及, 这里所谓的键值对不是其他程序中的 Hash Table (哈希表), 更像是一个储存了
(k, v)配对的一个列表.]pair[x;y] = [null[x] ∧ null[y] → NIL; ¬atom[x] ∧ ¬atom[y] → cons[list[car[x];car[y]]; pair[x;y]]; pair[cdr[x]; cdr[y]]]将两个列表两个元素两两配对在一起:
[通过这样的方式可以将
keyList 和valueList 组合成一个键值对列表](defun pair (x y) (if (and (null x) (null y)) NIL (if (and (not (atom x)) (not (atom y))) (cons (list (car x) (car y)) (pair (cdr x) (cdr y))) NIL)))
将两个列表进行配对.
assoc[x;y] = [eq[caar[y]; x] → cadar[y]; T → assoc[x;cdr[y]]]将
((u1, v1), (u2, v2), ...)这样的(key, value)键值对的列表, 通过assoc来得到对应的值.[注: 论文里面的括号没有配对, 不知道是不是 typo]
(defun assoc (x y) (if (eq (caar y) x) (cadar y) (assoc x (cdr y))))
sublis[x;y]替换在键值对中首先定义一个辅助函数:
sub2[x;y] = [null[x] → z; eq[caar[x]; z] → cadar[x]; T → sub2[cdr[x]; z]]然后就可以定义
sublis函数:sublis[x; y] = [atom[y] → sub2[x; y]; T → cons[sublis[x; car[y]]; sublis[x; cdr[y]]]][该函数的功能为将键值对列表里面的元素用来替换
y中出现的对象, 有点类似于 Mathematica 中的 Replace 的操作. 尽管我觉得这个代码和演示的例子, 有没有一种可能有点错误呢? ][因为不太能看懂对方的例子, 所以自己按照自己的理解写了一个: ]
(defun sublis (x y) (let ((sub2 (lambda (x y) (cond ((null x) y) ((eq (caar x) y) (cadar x)) (t (funcall sub2 (cdr x) y)))))) (if (atom y) (funcall sub2 x y) (cons (sublis x (car y)) (sublis x (cdr y))))))
[实际上这一步实现和函数计算的一个作用域的操作. 尽管目前还没有解决作用域的嵌套问题的样子. ]
- Representation of S-Functions by S-Expressions
使用 S-Expressions 来表示 S-Functions.
在前面定义的一堆的 S-Functions 都是在 M-Expression 的记号下进行定义的, 那么能否将这些符号使用 S-Functions 来表示呢?
[显然是可以的, 只要规定好对应的一个映射规则]
变换规则如下 (其中用 \(\mathcal{E}\) 来表示一个 M-expression, 用 \(\mathcal{E}^{*}\) 来表示对应的 S-expression):
- 如果用 \(\mathcal{E}\) 表示 M-expression,
那么用 \(\mathcal{E}^{*}\) 为 \((QUOTE, \mathcal{E})\).
[注: 论文中的原文是这样的: If \(\mathcal{E}\) is an S-expression \(\mathcal{E}^{*}\) is \((QUOTE, \mathcal{E})\). 但是我有点怀疑这个可能有笔误, 应该是 \(\mathcal{E}\) 为一个 M-expression, 因为 \(\mathcal{E}\) 应该是一个表示 S-Functions 的一个东西, 对应的应该是 M-expression.]
- 变量名和函数名称通过小写的字母来和相应的大写字母对应, 即 \(\mathrm{car}^{} ↔ \mathrm{CAR}, \mathrm{subst}^{} ↔ \mathrm{SUBST}\).
- 将 \(f[e_1, \cdots, e_n]\) 使用 \(f^{}, e_1^{}, \cdots, e_n^{*}\) 来表示.
- 将条件判断对应的表示方式 \(\{[p_1 → e_1; \cdots; p_n → e_n]\}^{}\) 记做 \((\mathrm{LAMBDA}, (p_1^{}, e_1^{}), \cdots, (p_n^{}, e_n^{*})))\).
- \(\{λ[[x_1; \cdots; x_n]; \mathcal{E}]\}^{}\) 为 \((\mathrm{LAMBDA}, (x_1^{}, \cdots, x_n^{}), \mathcal{E}^{})\)
- \(\{\mathrm{label}[a; \mathcal{E}]\}^{}\) 为 \((\mathrm{LABEL}, a^{}, \mathcal{E}^{*})\)
于是在如上的变换对应规则下, 任何一个 M-expression 都可以被对应到 S-expression 上.
- 如果用 \(\mathcal{E}\) 表示 M-expression,
那么用 \(\mathcal{E}^{*}\) 为 \((QUOTE, \mathcal{E})\).
- The Universal S-Function apply
定义一个 S-function apply, 其参数之一 \(f\) 为一个表达 S-function \(f'\) 的 S-expression; 另外一个参数 \(\mathrm{arg}\) 为一个有着 \((\mathrm{arg}_1, \cdots, \mathrm{arg}_n)\) 形式的列表, 其中 \(\mathrm{arg}_i\) 为任意的 S-expression.
于是 \(\mathrm{apply}[f;args]\) 即为 \(f'[ \mathrm{arg}_1; \cdots; \mathrm{arg}_n ]\).
\(\mathrm{apply}\) 函数可以被定义为 \(\mathrm{apply}[f; args] = \mathrm{eval}[\mathrm{cons}[f; \mathrm{appq}[\mathrm{args}]]; NIL]\). 其中所用到的两个函数定义如下:
\[\mathrm{appq} = [\mathrm{null}[m] → NIL; T → \mathrm{cons}[\mathrm{list}[\mathrm{QUOTE}; \mathrm{car}[m]]; \mathrm{appq}[\mathrm{cdr}[m]]]]\]
以及
\[\mathrm{eval}[e; a] = \left[\begin{matrix} \mathrm{atom}[e] & → & \mathrm{assoc}[e;a];\\ \mathrm{atom}[\mathrm{car}[e]] & → & \left[\begin{matrix} \mathrm{eq}[\mathrm{car}[e]; \mathrm{QUOTE}] & → & \mathrm{cadr}[e];\\ \mathrm{eq}[\mathrm{car}[e]; \mathrm{ATOM}] & → & \mathrm{atom}[\mathrm{eval}[\mathrm{cadr}[e]; a]];\\ \mathrm{eq}[\mathrm{car}[e]; \mathrm{EQ}] & → & [\mathrm{eval}[\mathrm{cadr}[e]; a] = \mathrm{eval}[\mathrm{caddr}[e];a]];\\ \mathrm{eq}[\mathrm{car}[e]; \mathrm{COND}] & → & \mathrm{evcon}[\mathrm{cdr}[e]; a];\\ \mathrm{eq}[\mathrm{car}[e]; \mathrm{CDR}] & → & \mathrm{cdr}[\mathrm{eval}[\mathrm{cadr}[e]; a]];\\ \mathrm{eq}[\mathrm{car}[e]; \mathrm{CONS}] & → & \mathrm{cons} \left[\begin{matrix} \mathrm{eval}[\mathrm{cadr}[e];a];\\ \mathrm{eval}[\mathrm{caddr}[e];a] \end{matrix}\right];\\ T & → & \mathrm{eval} \left[\begin{matrix} \mathrm{cons}[\mathrm{assoc}[\mathrm{cal}[e]; a];\\ \mathrm{evlis}[\mathrm{cdr}[e];a]];a \end{matrix}\right] \end{matrix}\right];\\ \mathrm{eq}[\mathrm{caar}[e]; \mathrm{LABEL}] & → & \mathrm{eval}\left[\begin{matrix} \mathrm{cons}[\mathrm{caddr}[e]; \mathrm{cdr}[e]];\\ \mathrm{cons}[\mathrm{list}[\mathrm{cadar}[e]; \mathrm{car}[e]]; a] \end{matrix}\right];\\ \mathrm{eq}[\mathrm{caar}[e]; \mathrm{LAMBDA}] & → & \mathrm{eval} \left[\begin{matrix} \mathrm{caddar}[e];\\ \mathrm{append}[\mathrm{pair}[\mathrm{cadar}[e]; \mathrm{evlis}[\mathrm{cdr}[e]; a];a]] \end{matrix}\right] \end{matrix}\right]\]
[注: 不得不说, LISP 是一门该死的 括号 语言, 不过要是用图灵机什么的, 或者是 Ruby 来写, 我怀疑也得这么麻烦, 毕竟是一堆的条件判断. 详细的介绍在之后再慢慢地写吧. ]
以及还有:
\[\mathrm{evcon}[c;a] = [\mathrm{eval}[\mathrm{caar}[c];a] → \mathrm{eval}[cadar[c]; a]; T → \mathrm{evcon}[\mathrm{cdr}[c]; a]]\]
和
\[\mathrm{evlis}[m;a] = [\mathrm{null}[m] → NIL; T → \mathrm{cons}[\mathrm{eval}[\mathrm{car}[m]; a]; \mathrm{evlis}[\mathrm{cdr}[m]; a]]]\]
[我下面会尝试找一些例子来帮助解释, 不过实际上先看看具体对应的代码, 可能会更加方便理解. 实际上上面就已经实现了一个 LISP 解释器了, 使用的是
apply和eval的两个函数. 如果看过那本 巫师书 的话, 估计会对这个非常熟悉. ][比如在 Emacs Lisp 中有这样的表示:]
(max 1 2 3 4 5 6 8) ; => 8 (let ((lst '(1 2 3 4 5 6 8))) (max lst)) ; => wrong-type-argument (let ((lst '(1 2 3 4 5 6 8))) (apply #'max lst)) ; => 8 equal to (max 1 2 3 4 5 6 8)
[即
apply将lst中的元素作为一列参数传给函数, 而不是只是作为一个参数. ](let ((lst '(1 2 3 4 5 6 8))) (eval (cons 'max lst))) ; => 8 equal to (eval (max ...))
[而
eval将一个 S-expression 来作为输入进行计算.]那么在
eval[e; a]中的a的是什么呢? 实际上可以模模糊糊地认为它就是一个用来查找符号值的一个空间. 在其中符号名字和符号值以键值对的形式进行储存. 按编译原理来说, 这应该算是运行时环境?那么来点更加具体的解释吧:
apply将 \(\mathrm{apply}[f; \mathrm{arg}]\) 变成 S-expression \((f, \mathrm{arg}_1, \cdots, \mathrm{arg}_n)\), 然后交由eval来计算 S-expression 的值.eval的两个参数分别是 S-expression 和键值对表 (是否可以叫做命名空间? 其中以键值对的形式将符号和其值进行对应)- 对
eval进行求值的时候:- 若 S-expression 是一个单元符号, 即
(eval variable env), 则会在env键值对中查找variable名字对应的值. - 若 S-expression 的第一个符号是一个单元符号, 即
(eval (f args) env), 则会对f进行判断, 若f是:quote, 则将剩下的部分作为一个 atomic symbol, 如(quote atomic-symbol)或者(quote (a1 a2 a3)).[注: 在常见的 Lisp 实现中, 往往会有一些对
quote的一些缩写, 比如 ='(a1 a2 a3)=, ='a= 这样的缩写之类的. ]cdr,cons,atom,eq这样的都是基本一样的, 就是把剩下的部分先计算一下对应的值是什么, 然后在计算完后, 将计算后的值作为输入放到对应的 S-function 中进行判断.举个例子,
(eq (+ 1 2) (+ 2 2)), 会先计算(+ 1 2)和(+ 2 2)的值, 其值分别为3和4, 然后就会计算eq[3; 4]的值. 其他的结果都差不多.cond, 使用evcon来进行进行条件判断.evcon的逻辑类似如下:(let ((cond-s-exp '(cond ((eq 1 2) 3) (t 2)))) (cl-labels ((evcons (condition-test) (if (null condition-test) NIL (if (eval (caar condition-test)) (eval (cadar condition-test)) (evcons (cdr condition-test)))))) (evcons (cdr cond-s-exp))))
- 若 S-expression 的第一个符号是一个列表, 并且列表的开头为:
label, 类似于((labels fib (x) (if (< x 2) x (+ (fib (- x 1)) (fib (- x 2)))))) 5)的形式.label的做法将函数的名字和函数的内容推到键值对里面, 推到键值对中的形式为(函数名字 label对应的S-expression).lambda, 类似与((lambda (x) (+ 1 x)) 2)的形式.将 lambda 表达式中的变量列表
(x)和 S-expression 之后的变量2进行配对, 然后将配对的键值对加入到env中. 然后将新的env交给eval来进行计算. 计算的对象为 lambda 表达式的 body.
label和lambda的操作非常类似, 但是有一些细微的区别.
- 若 S-expression 是一个单元符号, 即
- Functions with Functions as Arguments
[而在这里, 还有一个一开始接触 LISP 让我感到更加震撼的概念: “过程也是数据” 的概念, 尽管在其他语言中也不是不能做到类似的操作, 但是在 LISP 里面, 如果想要把代码写好写美的话, 貌似还是非常需要这样的操作的. ]
举一个例子, 一个经常会出现在 LISP 或者类似函数式编程教学中的
map函数:\[\mathrm{maplist}[x; f] = [\mathrm{null}[x] → NIL; T → \mathrm{cons}[f[x]; \mathrm{maplist}[cdr[x]; f]]]\]
一个例子便是将一个列表里面的值变成一个键值对:
(let ((count 0) (lst '(2 3 1 2 5 3 2 1 2 5))) (mapcar (lambda (elem) (list (setq count (+ 1 count)) elem)) lst))
以及还有另外一种非常漂亮的函数 (不过用了 Common Lisp 里面的
cl-mapcar函数):(let ((table '((1 2 3) (4 5 6) (7 8 9)))) (apply #'cl-mapcar #'list table))
这是函数的函数, 一种高阶函数.
[突然感觉这句话有一种很中二的感觉: これは、これは、関数の関数、ハイレベル上位の関数です。]
- A Class of Symbolic Expressions
- The LISP Programming System
LISP 在 IBM 704 机上干了 (或者是将要干) 的事情:
- 一个将 LISP 程序编译成机器码的编译器
[尽管这个可能听起来挺离谱的, 但是这可是非常正经的一个东西, 这个貌似可以被叫做 bootstrap (自举) 的概念. 比如 Emacs 的
native-comp, 就是用 Emacs Lisp 来编译 Emacs Lisp 的东西.] - 一个能够检测一组形式逻辑表达式的证明程序
[这个我真的非常感兴趣, 等我之后有时间了之后就去试试了解这些东西.]
- 形式化求导和积分的程序
[这个我也很感兴趣]
- 实现各种用于 predicate calculus 中的证明算法
- 用于工程上的符号积分
- 用于建议帮助系统 Advice Taker System.
[注: 虽然但是, LISP 应当能做的事情不只有这些, 但是遗憾的是, 缺少像 Python 一样把新用户骗过来的广为人知的框架. 明明我觉得 LISP 的语法绝对应该比 Python 之类的要简洁的说… ]
[注: 里面有一段话让我比较在意:]
In addition to the facilities for describing S-functions, there are facilities for using S-functions in programs written as sequences of statements along the lines of FORTRAN (4) or ALGOL (5). These features will not be described in this article.
[我倒是很想知道如何进行交互协作呢. ]
- Representation of S-Expressions by List Structure
通常来说使用的是 Linked List:

[抄的是我 数据结构 中的配图]
使用这样的数据结构的好处如下:
- 可以轻松储存变长的数据 (S-expression 的长度并不是固定的,
可以和 C 语言等其他语言的参数传入进行类比).
[尽管我并不是很想关心符号具体应该在内存中该如何储存, 但是鉴于之后可能需要和底层打交道, 还是再补充一下吧, 以一个列表
(aname averylongvar)为例. ]
[解释: 假设一个寄存器只能存放
4字节, 也就是 4 个字母的数据, 那么对于超出长度的符号名字, 就会需要用一个列表来储存. ] - 可以释放没有用的寄存器
- 在多个表达式中的相同的子表达式只需要在同一个储存地方进行储存
一个例子, 对于
((A . B) . (A . B))这样的结构, 可以有两种不同的储存方式:
那么在基础的 List 结构之上, 可以定义有如下的更多的结构:
- Association Lists (later called Property Lists)
Property List, 在之后被写作 p-list, 可以用来描述一些属性. 比如用属性名
pname来描述其对应的值.(let ((plist '(:pname (* 2 x) :differentiate x))) (plist-get plist :pname))
Free-Storage List
在计算机中, 任何时候仅有一部分是从内存中读取用于储存 S-expression. 剩下的部分则会作为一个 free-storage list 进行储存. 使用一个特殊的寄存器
FREE来指向这个 list 开始的位置. 每次从外部 list 中读取一个单词的之后, 则将FREE指向下一个位置.使用者在编程的时候不必关心向该 list 中进行返回值 [释放内存]. 释放寄存器的过程可以被简单地描述为: 将程序所用到的 list 结构的地址储存在一组固定的基寄存器集合中.
[个人的感觉有点像是
malloc对使用的堆的一个管理的感觉. ]随着列表结构的分支进行, 于是可能需要引入任意多数量的
FREE寄存器来处理这个问题. 通过在一个 base 寄存器上的car和cdr指令, 这些寄存器最终可以被访问到.[注: 个人理解如下图所示, 假如有一个树状的数据结构:]

当所有程序中都没有使用对应的数据的时候, 认为这段数据是没用的数据, 所以将这个数据删除掉.
[哦哦, 怪不得说 LISP 是引入自动垃圾回收的语言, 不过目前还是不太理解这个内存释放的一个机制. 可能以后有机会实现一次之后才能有结果吧. ]
如果程序中的所有内存都用完了的话, 那么就会触发回收机制 (reclamation 或者 garbage collection).
[注: 这里作者有一个还挺有趣的吐槽]
We already called this process “garbage collection”, but I guess I chickened out of using it in the paper or else the Research Laboratory of Electronics grammar ladies wouldn't let me.
[最终吐槽: 果然, 一流的论文着重思想, 三流的论文着重规范和排版. 我的论文啥也没有. 🥲]
具体的回收机制如下:
- 根据 base 指针指向的列表, 找到所有空闲指针, 然后将它们标记为负. 如果在历遍空闲指针的时候, 发现某处的符号已经是负号时, 就认为该寄存器已经历遍过了.
- 在历遍完所有的寄存器后, 程序将会历遍储存 list 结构的内存空间,
然后将所有的在前一步没有被标记的负号的寄存器放入 free-storage 列表,
并且使其符号再次为正.
[注: 我觉得这块我翻译得很烂, 有点不太看的懂在说什么. ]
因为这样的回收过程是完全自动化的, 所以对于一个程序员来说, 他/她/它并不需要时时刻刻都手动管理着计算机的内存.
[那么, 古尔丹, 代价是什么呢? ]
这种便利就会牺牲部分的执行时间, 在回收的时候, 因为要历遍一堆的寄存器, 所以会花费一段时间进行操作.
[这个部分我感觉还是很有趣的, 尽管不知道现在更加先进的回收机制是什么, 但是等我有时间之后, 在重新实现我自己的 LISP 的时候, 一定要将这个复现试试. ]
- 可以轻松储存变长的数据 (S-expression 的长度并不是固定的,
可以和 C 语言等其他语言的参数传入进行类比).
- Elementary S-Functions in the Computer
现在我们应当描述在计算机中该如何实现
atom,eq,car,cdr以及cons.[但是这部分想必除了
cons需要稍微展开一点介绍, 其他的都可以忽略吧. ]cons[x;y]的构造如下, 将xy扔到 free-storage 列表中的第一个元素中, (按照 SICP 中的说法, 就是分别放在高位和低位). - Representation of S-Functions by Programs
在编译
car,cdr,cons和cond(只需编译p和e) 的时候, 这样的操作还是非常轻松的. 但是在递归定义的函数面前, 编译可能会需要一些小注记.总体上, 递归定义的函数将其自身作为子过程来进行计算. 举一个例子,
subst[x; y; z]的程序将其自身作为一个子程序来计算car[z]和cdr[z]. 而一个被调用的subst程序在运行的同时, 之前调用它的subst的参数也应该被保留.[类似 C 的那种推栈的形式来传递参数. ]
但是如果传入的参数有相同的部分, 那么这样的参数便不必重复传递, 而是可以用相同的寄存器来处理. 这样的操作便可以通过
SAVE和UNSAVE两个进程在一个公共的下推列表上进行管理:SAVE进程在递归函数调用开始的时候被执行, 其将传入的参数连续地保存一组寄存器 (public push-down list) 中. 通过一个index来记录当前的 push-down list 已经使用了多少的寄存器. 该index放在 push-down list 的第一个未使用的地方.[感觉可能需要一些图才能够比较好地理解这个概念. 等我之后有时间一定要重新读一遍这篇论文. ]
[目前个人的理解如下: ]
digraph { rankdir = LR; node [shape=record]; subgraph cluster_SAVE { style = dashed; free [label = "<count> size = 5|idx = 1|idx = 2|idx = 3|idx = 4|idx = 5"]; input [label = "SAVE", shape = plain]; free:count -> input [dir = back]; } }
UNSAVE进程在递归函数体调用结束的时候被执行, 其将使用的空间释放掉成为空闲的空间.
- Status of the LISP Programming System
在 IBM 704 机中实现了一个前文中描述的
APPLY函数, 于是在这个函数的基础上, 便有了一个能够计算 S-expression 表达式的程序 – 其作为一个 LISP 解释器来进行.APPLY程序可以被嵌入一个 LISP 程序系统中:- 程序员可以通过 S-expression 定义任意数量的 S-function,
这些函数可以相互调用或者通过调用特定的通过机器语言编写的 S-function.
[这里应该是指预编译的 S-function]
- 定义的函数的值可能被计算
- S-expression 可以被读取或者打印出来 (直接或者通过磁带)
- 包括一些错误处理, 诊断信息, 以及 trace (函数跟踪) 功能
- 程序员可以选择特定的 S-functions 将其编译成机器语言并将其放入核心内存 (core memory). 编译后的程序运行的效率相比解释型的程序效率更高.
- 一个 “program feature”: 可以让程序包含 ALGOL 风格的
go to操作. - 在该系统中进行浮点数操作是可能的, 尽管效率不高
- 有程序员的手册.
- 程序员可以通过 S-expression 定义任意数量的 S-function,
这些函数可以相互调用或者通过调用特定的通过机器语言编写的 S-function.
- 一个将 LISP 程序编译成机器码的编译器
[感觉这篇论文基本上把如何实现一个 Lisp 解释器, 并且如何实现一个 Lisp 机的各种细节都大概地介绍了一遍了.]
- Another Formalism for Functions of Symbolic Expressions
实际上有不只一种方式来实现上述的符号表示系统. 还有一种系统包含: 三个基本的函数, 条件判断语句, 以及递归定义的函数. 只是在表达 S-expression 上有不同的表现, 我们将这些差异称为 linear LISP.
L-expression 如下定义:
- 接受有限长度的字母列表
- 任意由接受字母组成的字符串, 包含空字符串 \(Λ\)
其中有三个对于 string 的函数:
first[x]为字符串 \(x\) 的第一个字母, 若 \(x = Λ\) 时, 则为未定义的 undefined.rest[x]为除去字符串 \(x\) 第一个字母后剩下的部分combine[x; y]将两个字符串按照xy的先后顺序合并在一起
其中有三种条件判断函数:
char[x]判断 \(x\) 是否为单个字母null[x]判断 \(x\) 是否为空字符串x = y, 判断是否两个字符串相等
对于这样的 linear LISP 系统, 其好处在于没有特殊符号, 比如
(,), =,=,.之类的, 这些特殊符号在 linear LISP 系统中便不再是特殊的. 并且所有的表达式都能够被线性地书写.缺点则是: 提取子表达式的过程比较繁琐, 并且在 linear LISP 中并不容易书写一些在 LISP 中的基本函数. 尽管在数学上, linear LISP 应该包含了 LISP. 在 linear LISP 中描述比较方便, 但是在 LISP 中表示计算机过程更加快速.
[这一段我不是很理解欸… ]
- Flowcharts and Recursion
通常形式的计算机程序和递归函数都拥有通用的计算能力 (universal computationally), 所以如何将两者的关系显现出来就会是一个比较有意思的事情了. 本文之后的内容将要注重于如何将递归函数变成计算机程序.
计算过程中, 机器的状态通过一组变量的值 (使用一个矢量 \(ξ\)) 来进行表现. 假设一个程序块拥有一个入口和一个出口. 认为其关联函数 (associate function) 为 \(f\), 即 \(ξ' = f(ξ)\).
[即在执行完该程序块之后, 机器的状态向量 \(ξ\) 从 \(ξ\) 变为 \(ξ'\). 可以类比一下图灵机的状态转移方式. ]
假设有一种决策块代码 decision elements \(π\), 其会选择接下来该进入 (执行) 那一块代码块. 但是, 仍然让程序只有一个入口和出口.

在上面的程序框图中, 可以用如下的形式来进行描述:
\[\begin{matrix} r[ξ] & = & [π_1 1[ξ] → S[f_1[ξ]]; T → S[f_2[ξ]]]\\ S[ξ] & = & [π_2 1 [ξ] → r[ξ]; T → t[f_3[ξ]]] \\ t[ξ] & = & [π_3 1[ξ] → f_4; π_3 2[ξ] → r[ξ]; T → t[f_3[ξ]]] \end{matrix}\]
[注: 这里应该将 \(π_i k [ξ]\) 写成 \(π_i[k, ξ]\) 感觉才对. ]
之所以将所有的程序块都用一个入口和出口进行包裹, 其好处在于这样就能够方便地将其写入一个递归定义的函数中去.
对于一个有 n 个分支的条件跳转:

\[φ[ξ] = [p_1[ξ] → φ_1[f_1[ξ]]; \cdots; p_n[ξ] → φ_n[f_n[ξ]]]\]
不过为什么要在一个讲如何使用编辑器的安利文里面塞这些? 大概只能说 Emacs 不只是一个编辑器吧.
假设你并没有看上面的那段被折叠起来的文字,
不论是懒得看, 抑或是看完了之后虽然知道了 LISP 大概可能是啥,
但是还是不太懂为啥要在一个将编辑器的安利文章中塞这种奇怪的东西,
那么请听我狡辩. 用简单的话语来解释一下 Emacs Lisp 吧.
The Basic Data and Command
构成 Emacs Lisp 的基本的元素 (非全部):
atom类似于最小零售单元的感觉可以用
(atom ...)来判断一个元素是否是单元符号.(atom 1) ; => t (atom '(1 2 3)) ; => nil
list类似于最小零售单元的组合的感觉
说实话, 大部分清况下, 区别是否是 atomic symbols 的一个非常离谱的方法就是看它是不是一个被括号包裹起来的东西.
构成 Emacs Lisp 的一个概念: 过程即数据. 在 Emacs Lisp 中, 直观地来看就是其过程的命令都以 S-expression 的 List 的结构来表现的:
(+ 1 2) ; 1 + 2
当然, 你可能会说: “我就想要设置一下字体大小, 设置一下其他的功能什么之类的, 写什么程序啊, 是不是太麻烦了呢? ” 虽然可能会有一点不太直观, 但是为了尽可能地简单起见, 我接下来用到的代码会尽量保持在一个: “Let there be some light. ” 这样难度的语句水平.
当然, 也不是不能不写代码
如果你比较喜欢 VSCode 的那种用鼠标点点点的设置方式的话, 实际上也不是不行.
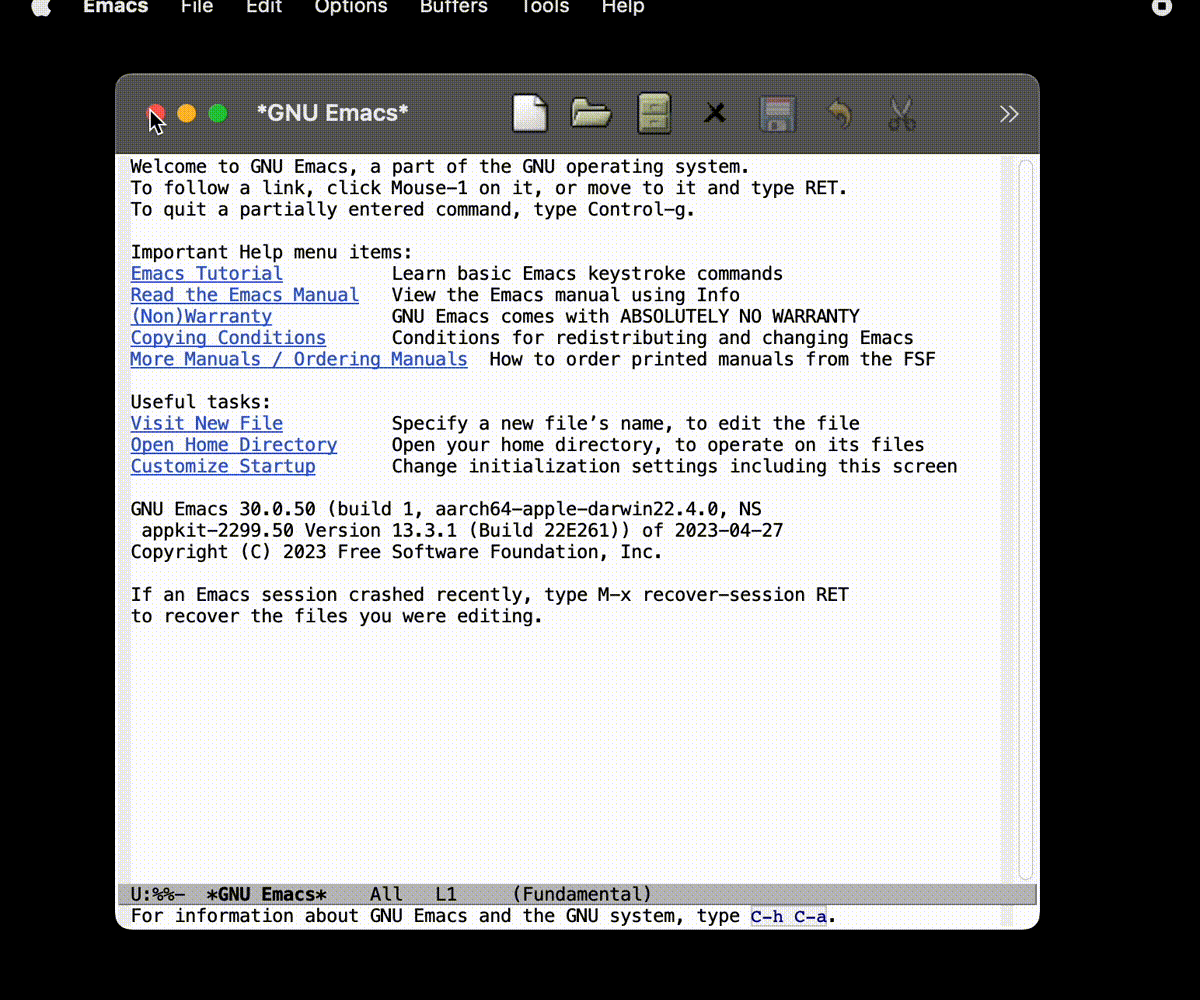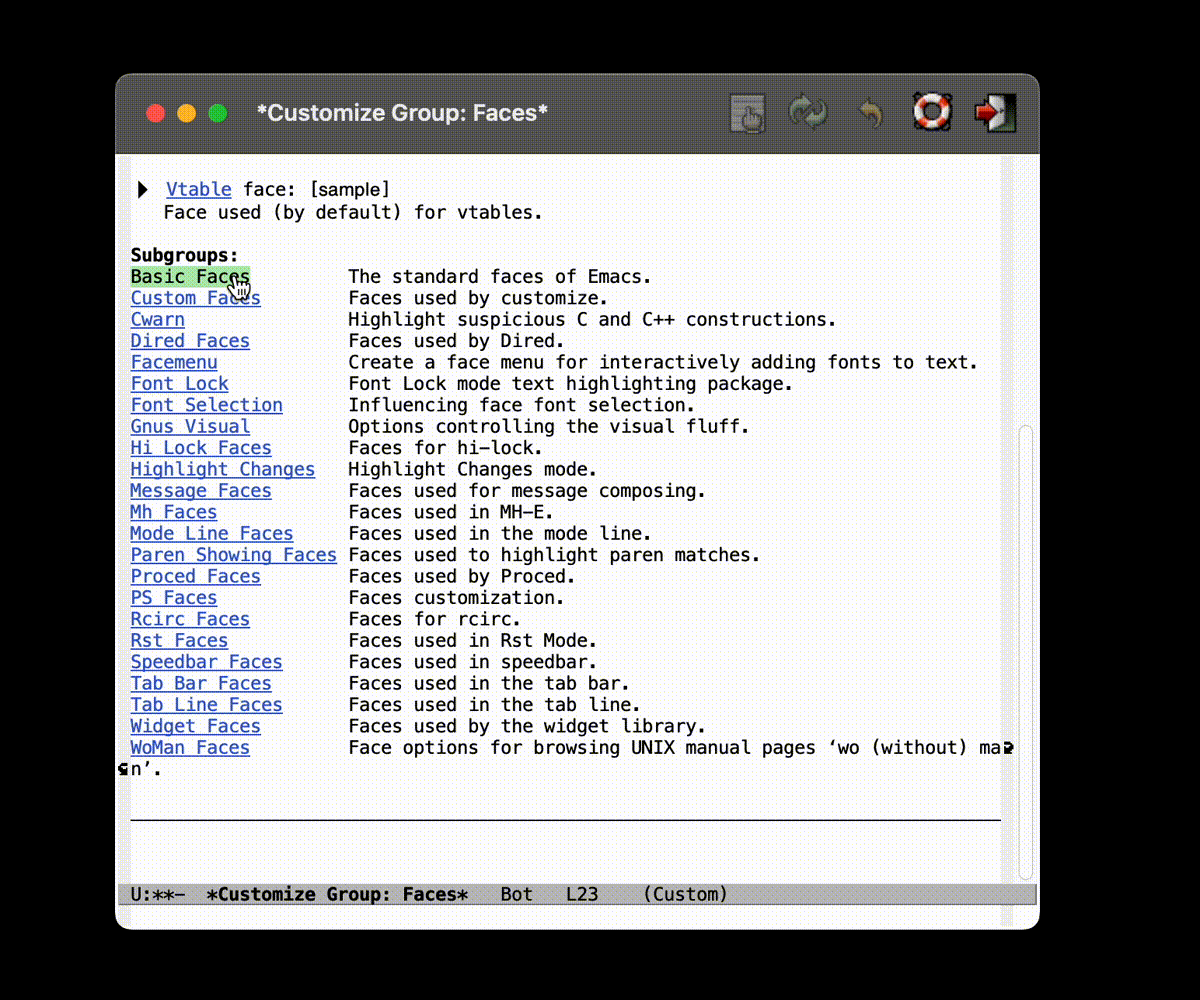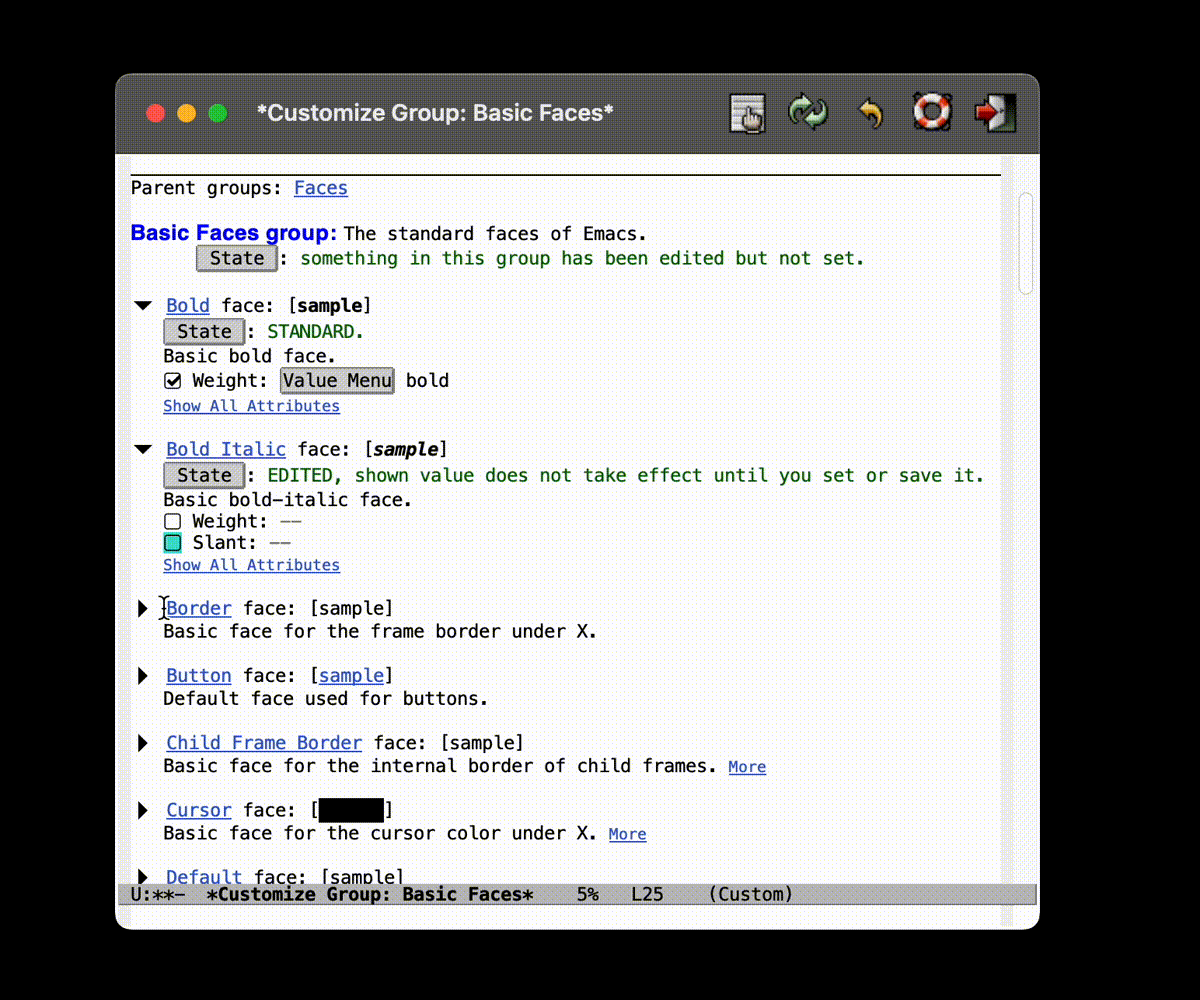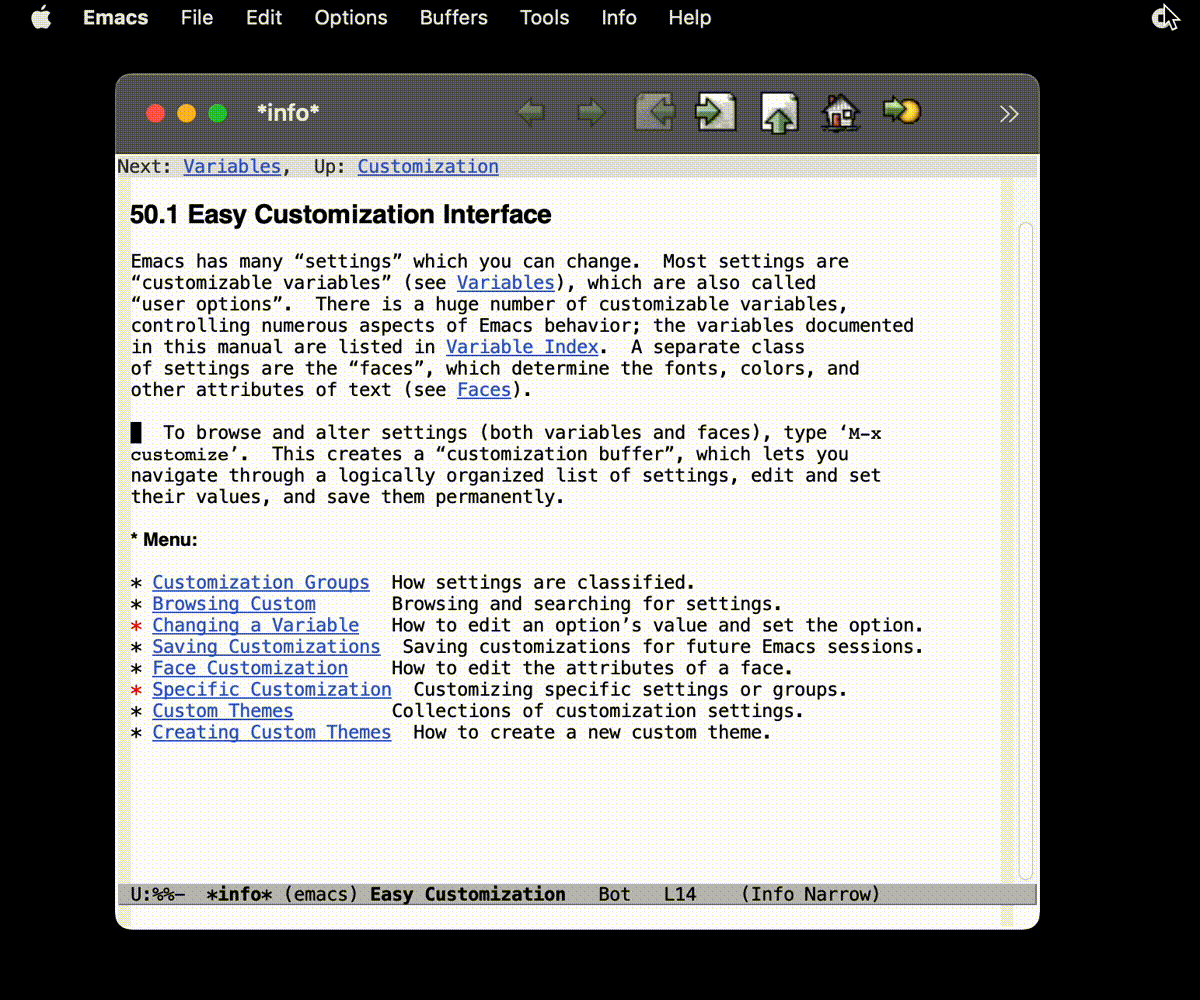
(注: 使用菜单栏 Emacs-Settings 打开 Custom 的界面, 我不知道为什么录屏没录进去. )
不过这个方法唯一的缺点是可能大部分用 Emacs 的人并不用, 看起来就会缺少教程. (实际上并不是, 因为 Emacs 的代码大多数是自解释的, 并且好的代码里面会有很多的注释和文档自动生成, 这一点我觉得比我使用 VSCode 的体验会好一点. )
不过因为我平时并不使用 Custom 自定义, 所以很遗憾, 我没法提供更加详细的介绍.
可以考虑参考 官方的 Easy Custom, 不过我也没看过就是了.
比如你可以在 ~/.emacs.d/init.el 中写入以下的内容,
然后重启你的 Emacs:
(tool-bar-mode -1)
于是你会发现, 你的 Emacs 现在看起来更加得干净了:
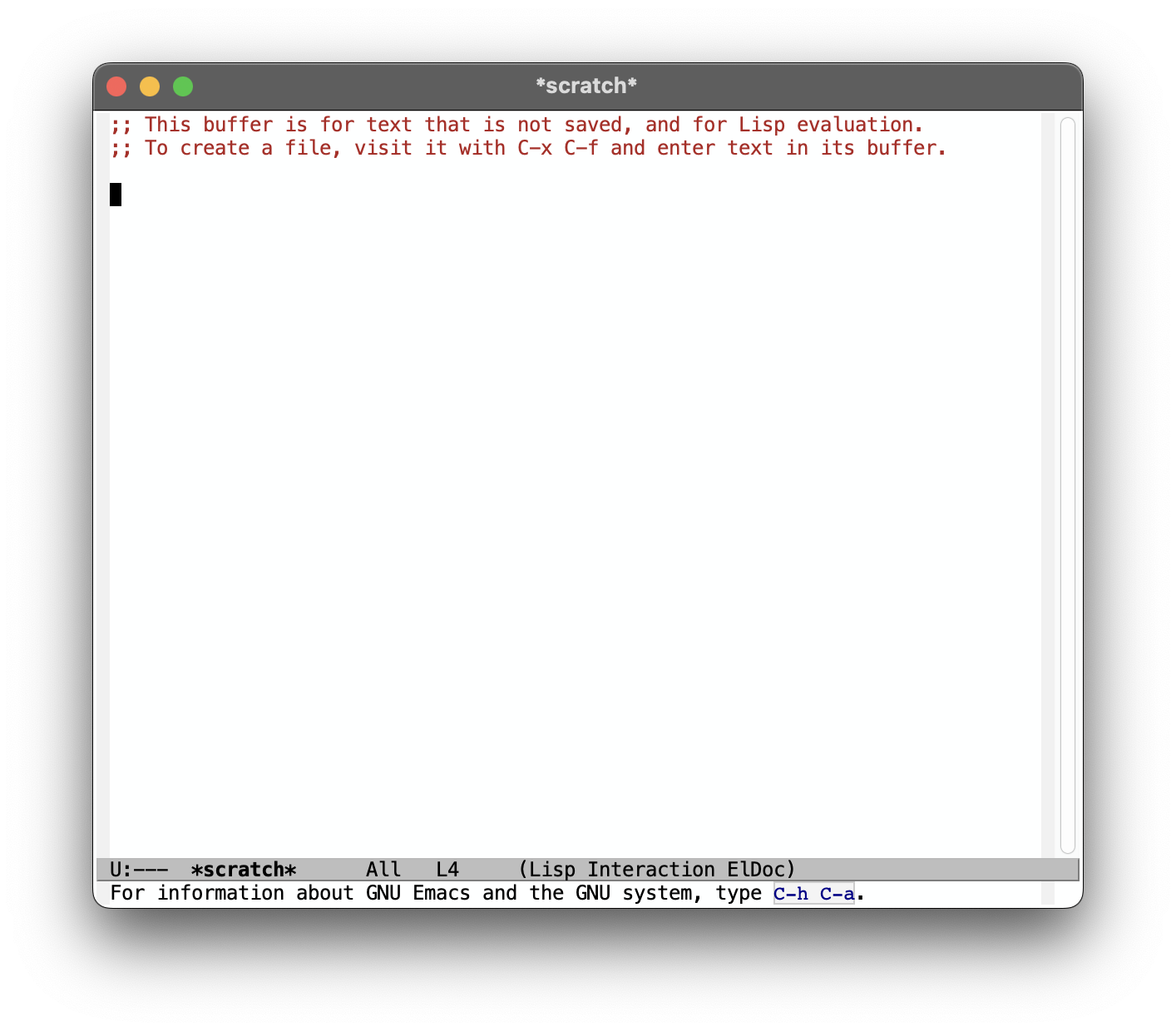
那么这段代码的作用应该就非常显然了: 让 tool-bar 消失.
那么让我们回忆一下 Lisp 的一个语法:
显然, tool-bar-mode 应该是一个函数,
而 -1 应该就是我们传入的参数,
应该代表的含义为 “假”, “关闭”.
(可以尝试用 1 或者其他的值来试试看, 如果愿意的话. )
除了试试, 也可以看看文档是怎么说的:
使用 M-x describe-functions, 可以描述对应的函数.
不过不妨让我们接触一些新的快捷键吧, 按下 C-h f:
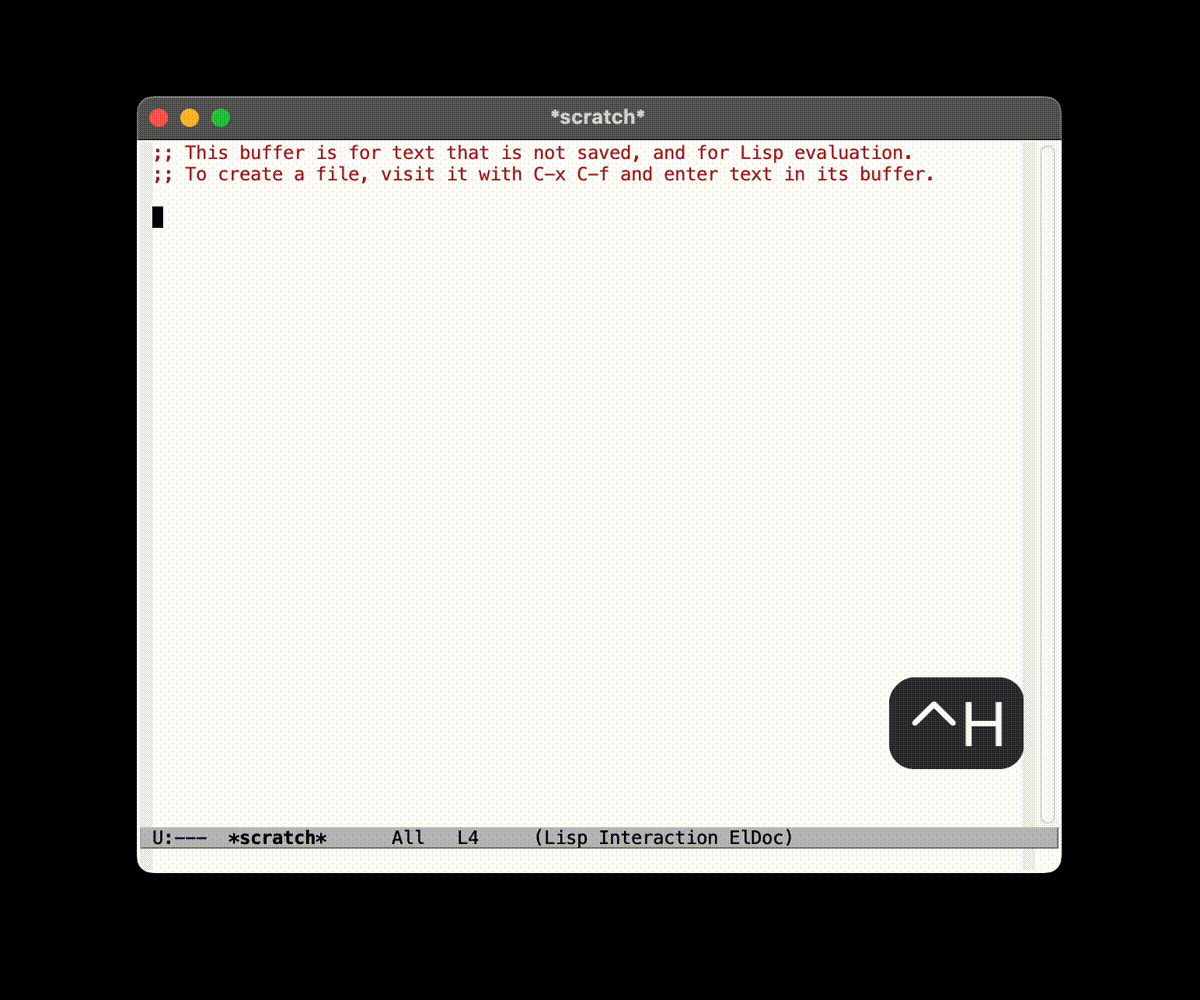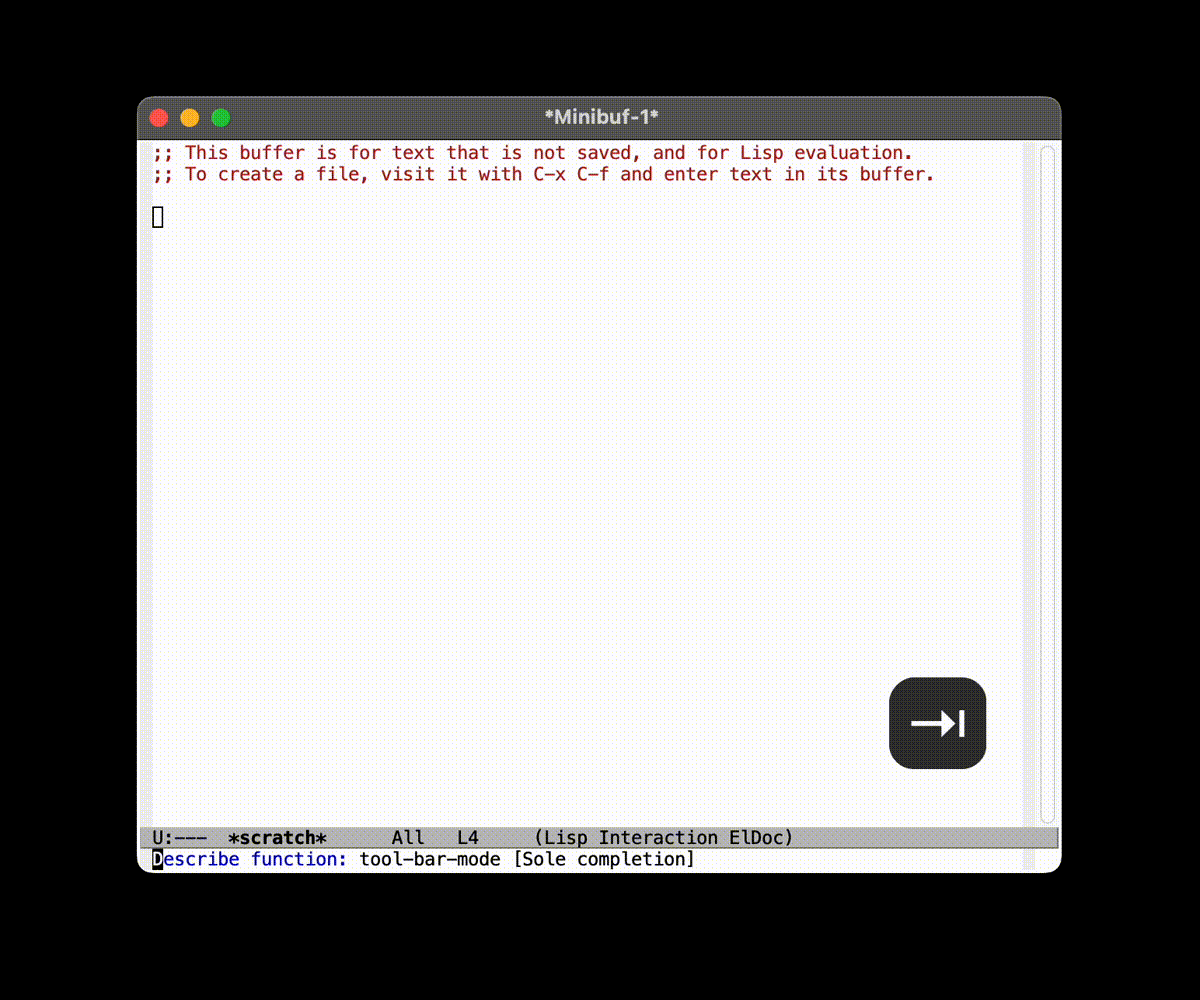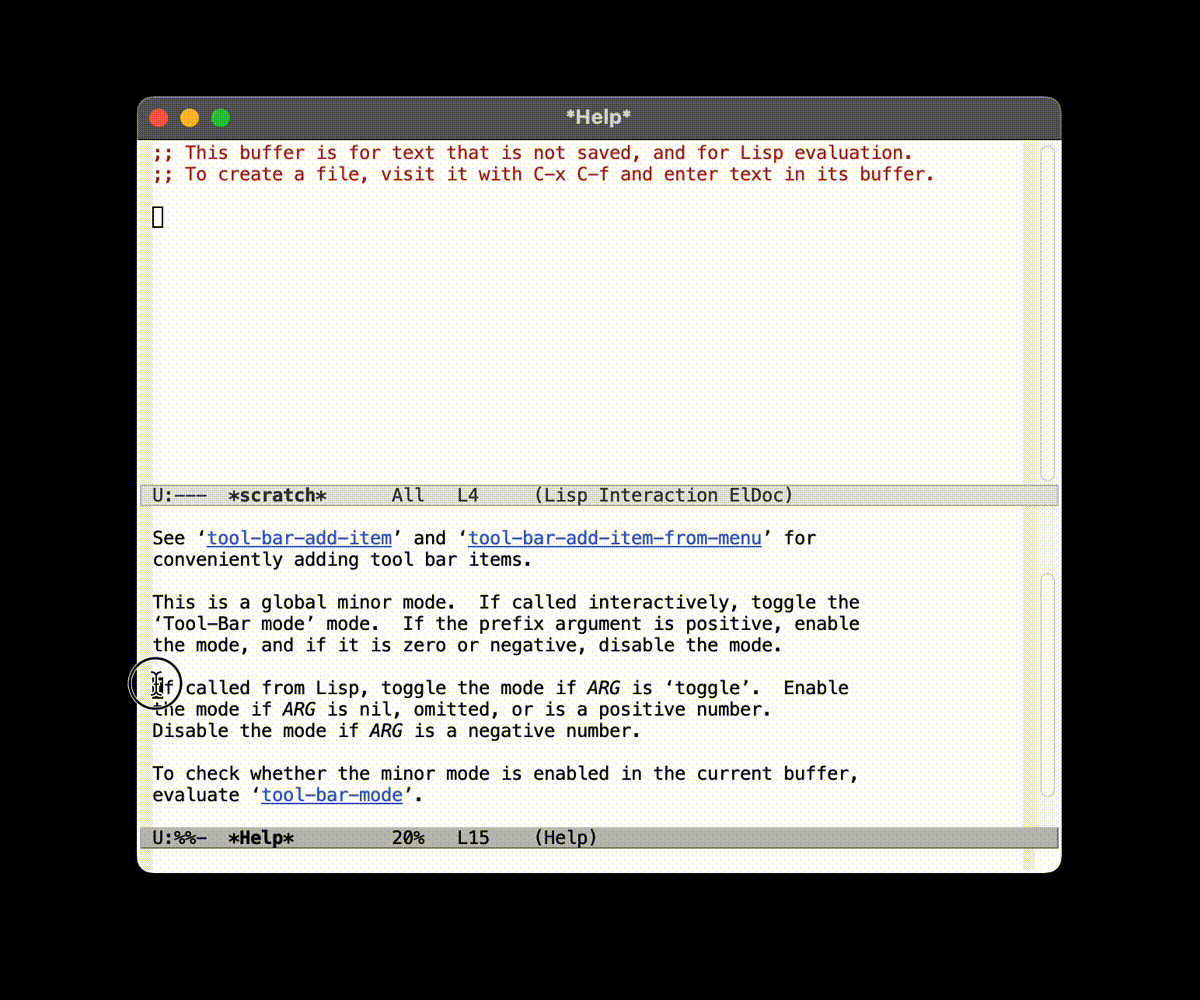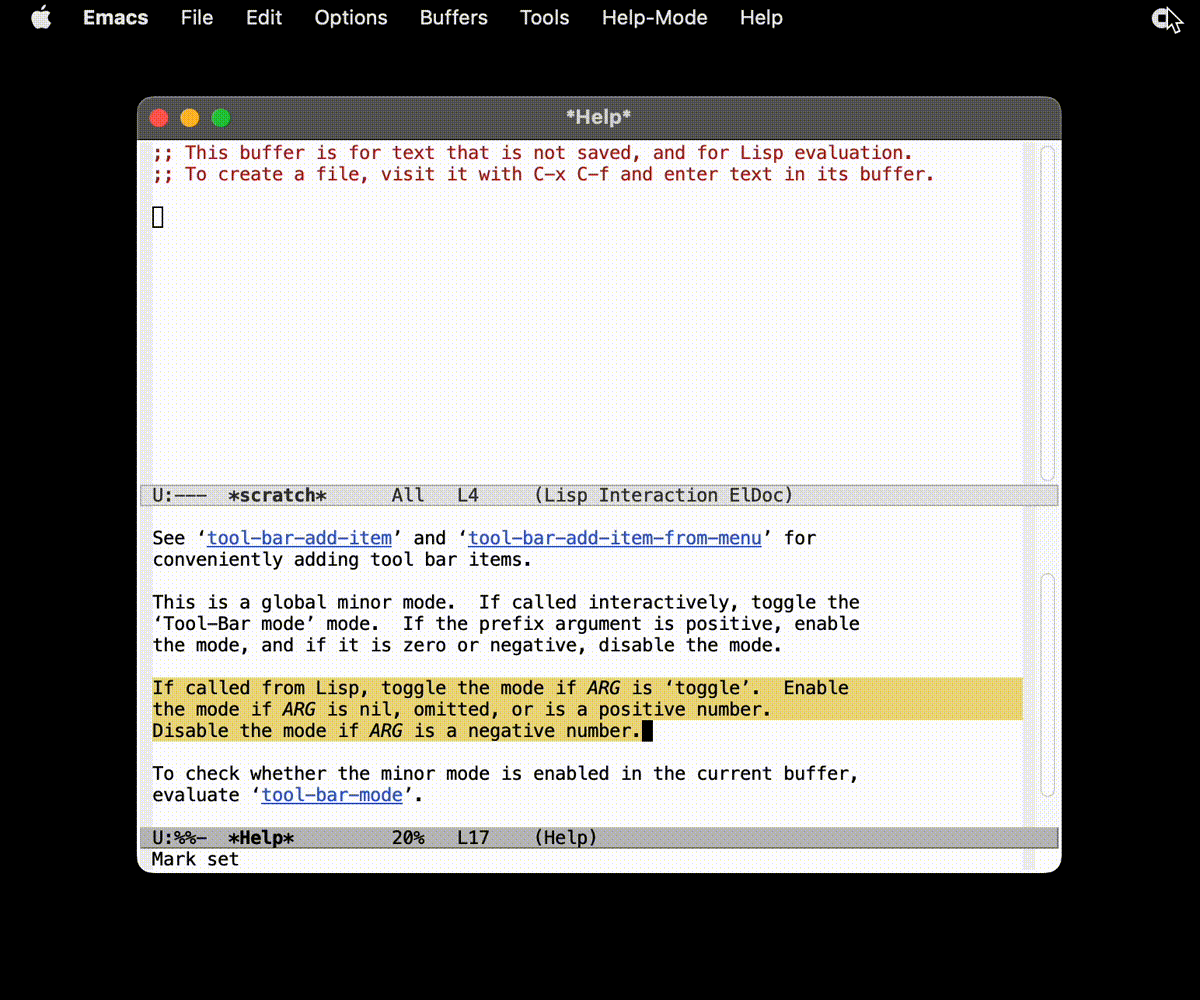
其中 C-h 系列的快捷键和一组帮助性质的命令进行了绑定,
我常用的帮助有:
C-h fdescribe-function在了解函数的作用和传入参数的时候比较方便C-h vdescribe-variable在修改变量的时候比较方便C-h kdescribe-key描述接下来按的键, 对于按键绑定比较有帮助C-h mdescribe-mode描述当前模式, 对于了解当前模式和 hook 比较友好
稍微复杂一点的代码:
;;; Non-nil means make a backup of a file the first time it is saved.
(setq make-backup-files nil)
;;; Control use of version numbers for backup files.
(setq version-control t
delete-old-versions t
kept-new-versions 2
kept-old-versions 2)
来一点点的解释, 如果你还猜不出来上面的代码的作用的话
(setq [SYM VAL] ...)函数将符号SYM和值VAL进行绑定, 显然, 正如函数的名字所示, SET-Quantity (我瞎掰的), 很好理解.- 第一条代码将
make-backup-files这个变量的值设置为nil, 该变量的作用将 Backup Files 的功能给关闭了.(之所以关闭这个, 是因为它太麻烦了, 会在文件附近生成一个带
~标志的备份文件. 尽管很多时候备份文件帮了我很大的忙, 但是这样的备份着实有点恼人. )(注: 实际上还是保留了
auto-save-default的功能, 你会看到#你的文件名字#的临时文件作为自动保存的文件. 在文件被自动保存的时候, Mini-buffer 中会显示相应的信息. 并且可以使用M-x recover-this-file来还原文件. ) - 第二条代码修改了关于
version-control的一组变量. 在 Emacs Lisp 里面的setq可以修改一列的变量, 只要这列变量满足[SYM VAL]的组合进行排列. 这样就可以很方便地设置变量, 同时也能够对设置的变量进行分组, 可以让代码更好读一点.关于 Version Control 的功能, 可以给代码引入一些最基本的版本控制功能. 不过后来看看, 感觉还是不如使用 Magit 更加好用.
能不能稍微更加复杂一点?
当然, 不妨来点条件判断语句:
;;; Test if I'm using macOS
(defvar *macos?* (eq system-type 'darwin))
;;; If I am using macOS...
(when *macos?*
(setq dired-use-ls-dired t
insert-directory-program "gls"
dired-listing-switches "-aBhl --group-directories-first"))
可是这么简单易懂的代码, 相信英语绝对比我更好的你一定读的懂吧
哪怕你用的不是 该死的 macOS, 其实也没有什么关系.
(defvar SYMBOL &optional INITVALUE DOCSTRING)定义SYMBOL为一个变量, 其值为INITVALUE. 这里用*macos?*来表示是否为 macOS.(注: 理论上来说, 取什么名字是你的喜好, 但是至少别乱取就行.)
eq为判断两个值是否相等的函数, 其中 ='darwin= 为一个符号, 倘若直接输入darwin的话, 系统则会在环境中去查找是否有一个叫做darwin的符号, 然后用该符号对应的值来作为比较的对象.显然, ='= 是一个语法糖, 其和
(quote darwin)是等价的. 其作用就是将符号按照字面值 (输入的形式) 传入而不被拿去计算.(when COND &rest BODY)是一个条件判断代码, 即如果COND的值为真, 则执行BODY中的所有的语句.(注:
&rest关键词表示之后的所有的东西都会作为一个 list 传入BODY这个变量名中. 比如(defun add-func (&rest val) (reduce #'+ val)). )- 当然, 更加常见的应该是
(if COND THEN ELSE ...)这样的东西, 但是和when不同的是, 如果在if语句中想要在真分支中依次执行多个函数, 那可能需要将这些函数用(progn (code) (code) ...)这样的形式来处理.不过一般来说, 用到的不会那么多.
接下来, 请使用悲催的 macOS 用户看看:
- 在 macOS 上, 因为
ls命令并没有--dired的 flag. 所以在 Emacs 中使用 Dired 打开文件目录会出现一个报错.尽管你可以忽略就行了
如果你现在还没有学过命令行, 那么请看看我之前学习计算机的时候做的笔记中关于 LINUX 的内容 Untitled (2).
好的, 打住, 最简单的代码到此为之. 总结一下就是, 在 Emacs Lisp 中:
atomic-symbol一般没在括号里面的是 atomic-symbol- ='sym=, ='(a b c)= 使用引号开头的是被 Quote 起来的元素, 可以将输入作为字面值传入
(func arg1 arg2 ...)长这样的可能是一个函数调用(setq sym val)将val的值赋给sym(if COND THEN ELSE)或者(when COND &rest BODY)可以进行条件判断
在之后, 我会尽量只用上面的东西, 虽然感觉应该没有啥不在上面的模版里了吧….
Copy and Paste is ALL YOU NEED TO KNOW?
显然全部代码都自己写就有点夸张了. 所以你为何不可做一个调包达人呢?
放心, 和 Python 不一样, 调着调着你就会发现自己竟然不知道为啥突然开始写程序了.
不过为了调包, 我们不妨再了解一些关于 Emacs Lisp 的函数?
害, 前面还说不会有新的东西了… 诈骗!
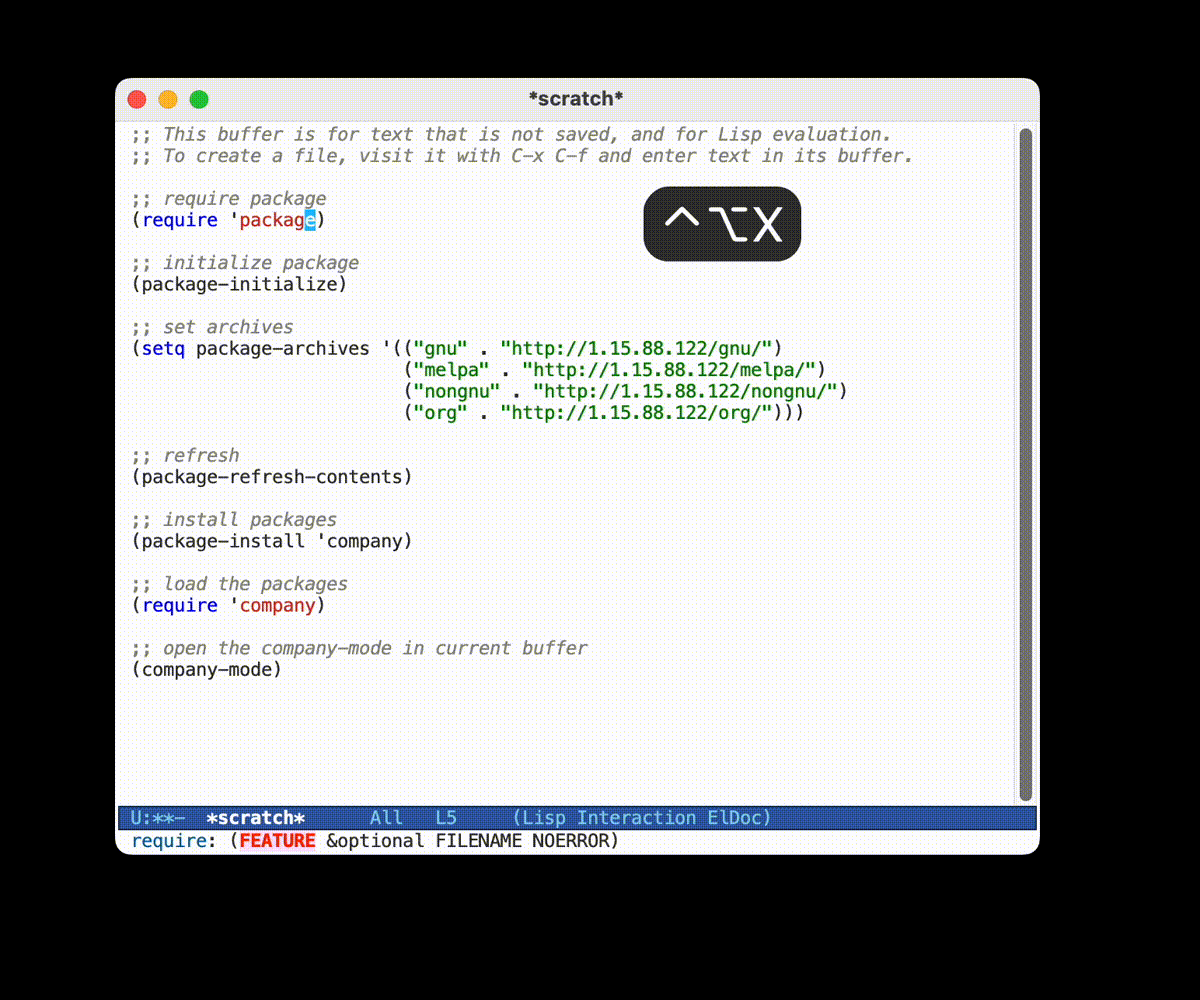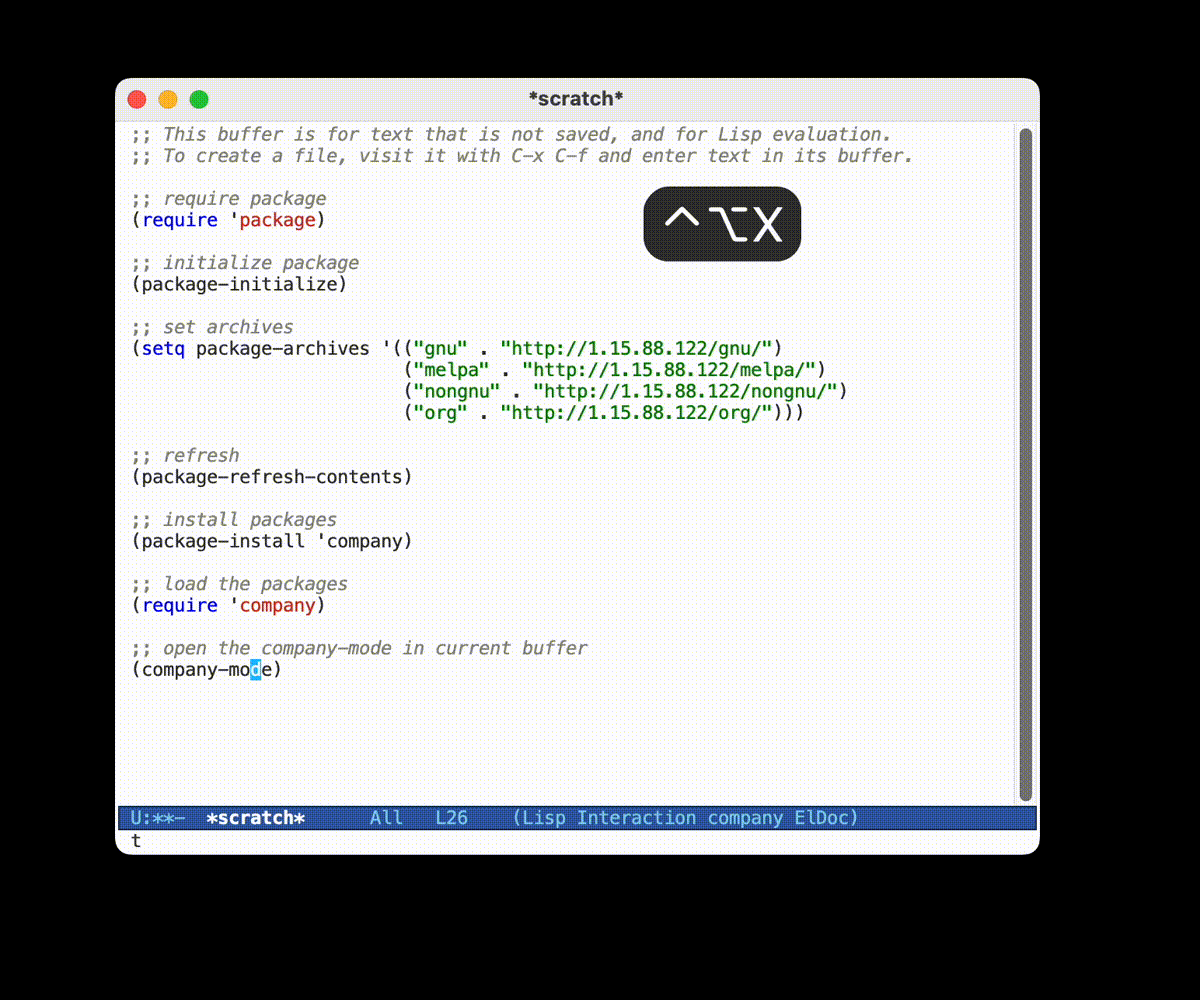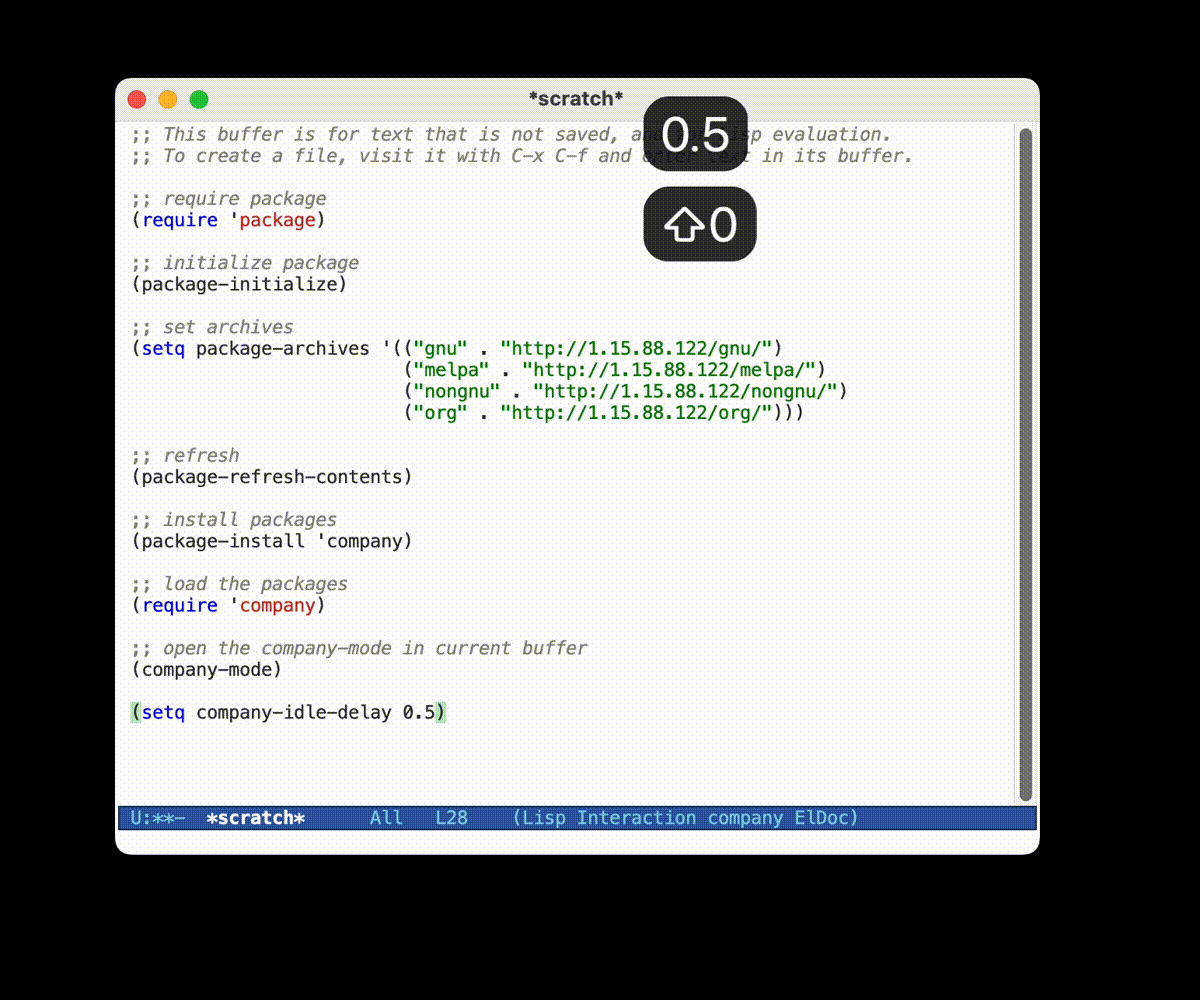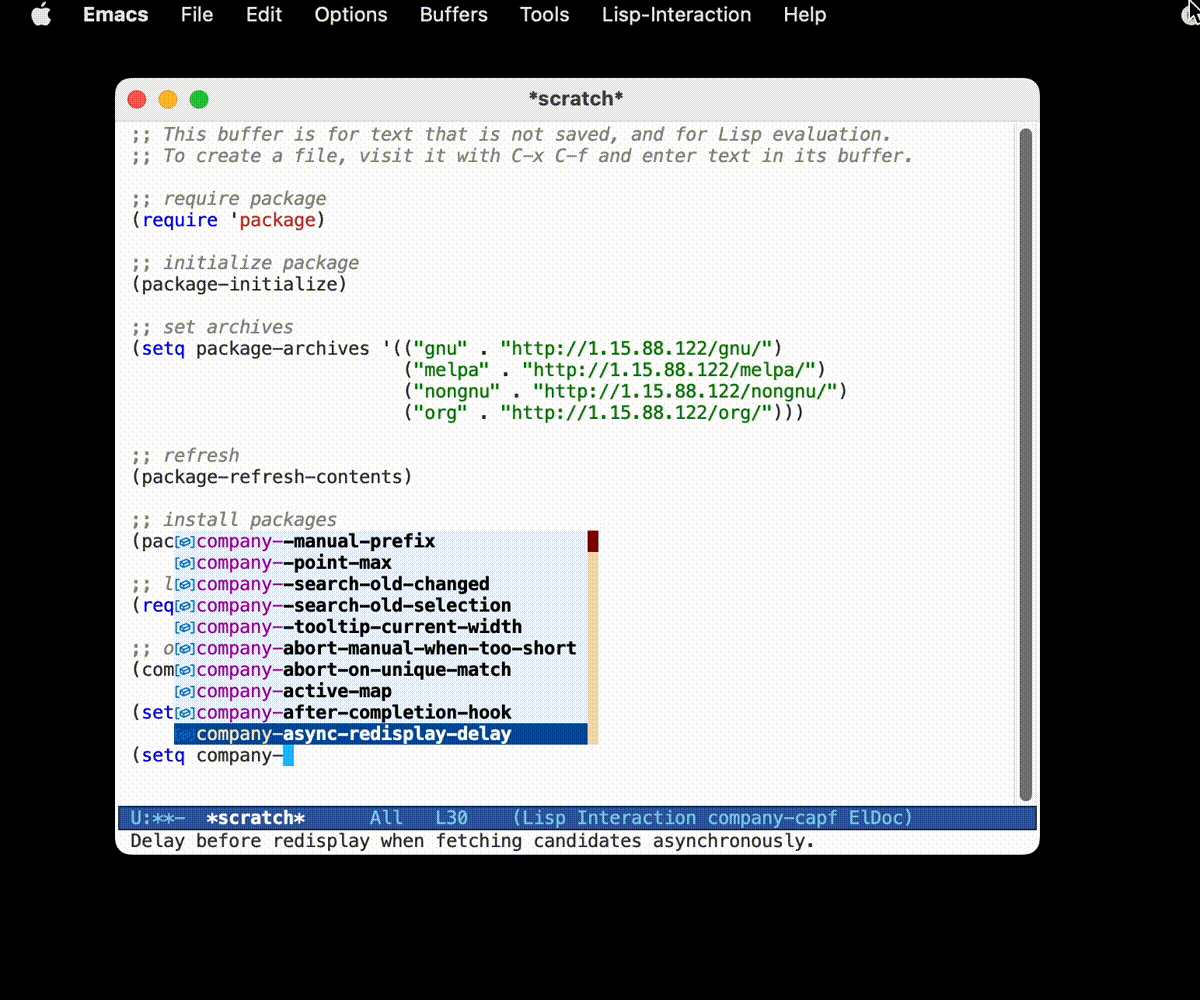
首先, 我们要配置国内的镜像, 在 Emacs 的 init.el 文件中加入:
;;; use package.el
(require 'package)
(package-initialize)
(setq package-archives '(("gnu" . "http://1.15.88.122/gnu/")
("melpa" . "http://1.15.88.122/melpa/")
("nongnu" . "http://1.15.88.122/nongnu/")
("org" . "http://1.15.88.122/org/")))
(package-refresh-contents)
让我来一条条解释
- 前三条
(require 'package)将会载入一个叫做package的模块.关于模块的一二事
啊, 我懒得写了, 不如直接看看 我的配置文件 中的 一块代码 吧:
;;; init-python.el --- Python -*- lexical-binding: t -*- ;;; Commentary: ;;; Code: ;;; Mode hook (add-hook 'python-mode-hook 'eglot-ensure) (add-to-list 'auto-mode-alist '("\\.py$" . python-mode)) (add-to-list 'interpreter-mode-alist '("python" . python-mode)) (provide 'init-python) ;;; init-python.el ends here
一点简单的解释:
(provide 'init-python)将这个代码作为名为init-python的模块, 于是在init.el中, 便可以用(require 'init-python)的形式来导入.- 不过为了能够让 Emacs 去找到这个代码文件,
还需要在
require之前设置要导入文件的位置:(add-to-list 'load-path dir-path-to-init-python)不过
package.el是 Emacs 自带的, 所以不需要做这个load-path的拓展操作.
(package-initialize)将会初始化package模块, 将会载入 Emacs 默认自带的一些 package.(setq ...)配置国内的镜像地址. 这里我使用的是 Emacs-China 的镜像. 类似的还有 清华的镜像 (实际上用的上游还是 emacs-china 的镜像).其中
gnu,melpa等标签为一个仓库和地址的对应的 alist.(package-refresh-contents)下载并更新 ELPA 包的说明信息. 这些信息在你使用M-x package-install的时候就会被调用.
那么现在我们来安装一些让生活更加轻松的包吧 (以 company 为例):
对操作的注释
- 使用
package-install函数安装一个叫做company的包, 因为 Emacs 29+ 貌似是自带 company 的, 所以这里显示已经安装了. - 通过
(require 'company)将安装的包载入到 Emacs 中 - 通过
(company-mode)在当前 Buffer 打开company-mode(当然, 如果你想要一个全局打开的话, 可以使用
global-company-mode命令. )
当然, 并不是所有的包都能够通过 MELPA 来下载, 一些新的包, 或者一些没有提交到 MELPA 上的包, 可能还需要手动地载入 Emacs.
这里以 xcode-theme 这个不在 MELPA 上的主题包为例, 演示如何将远程的包下载到本地并将其载入到 Emacs 中.
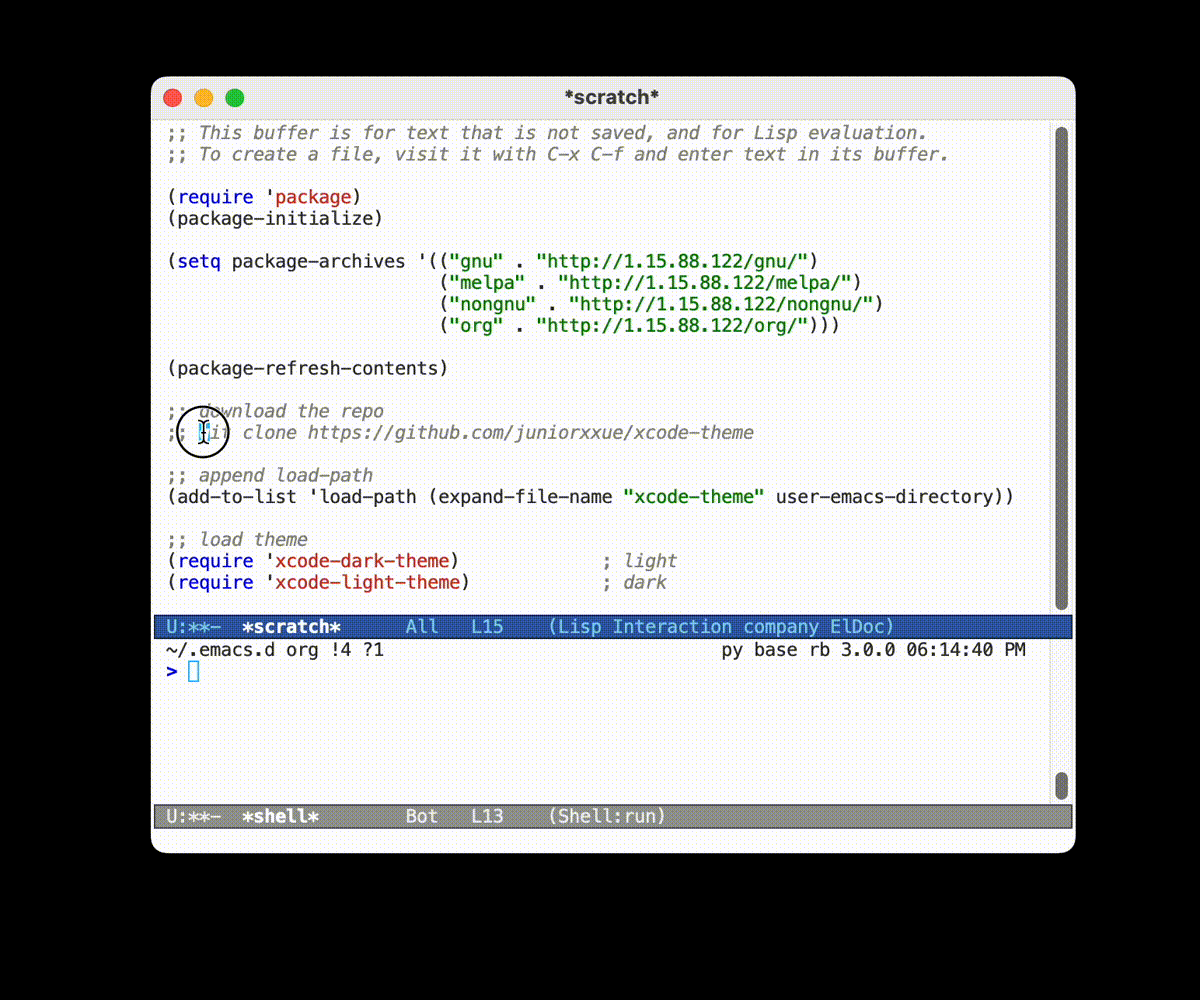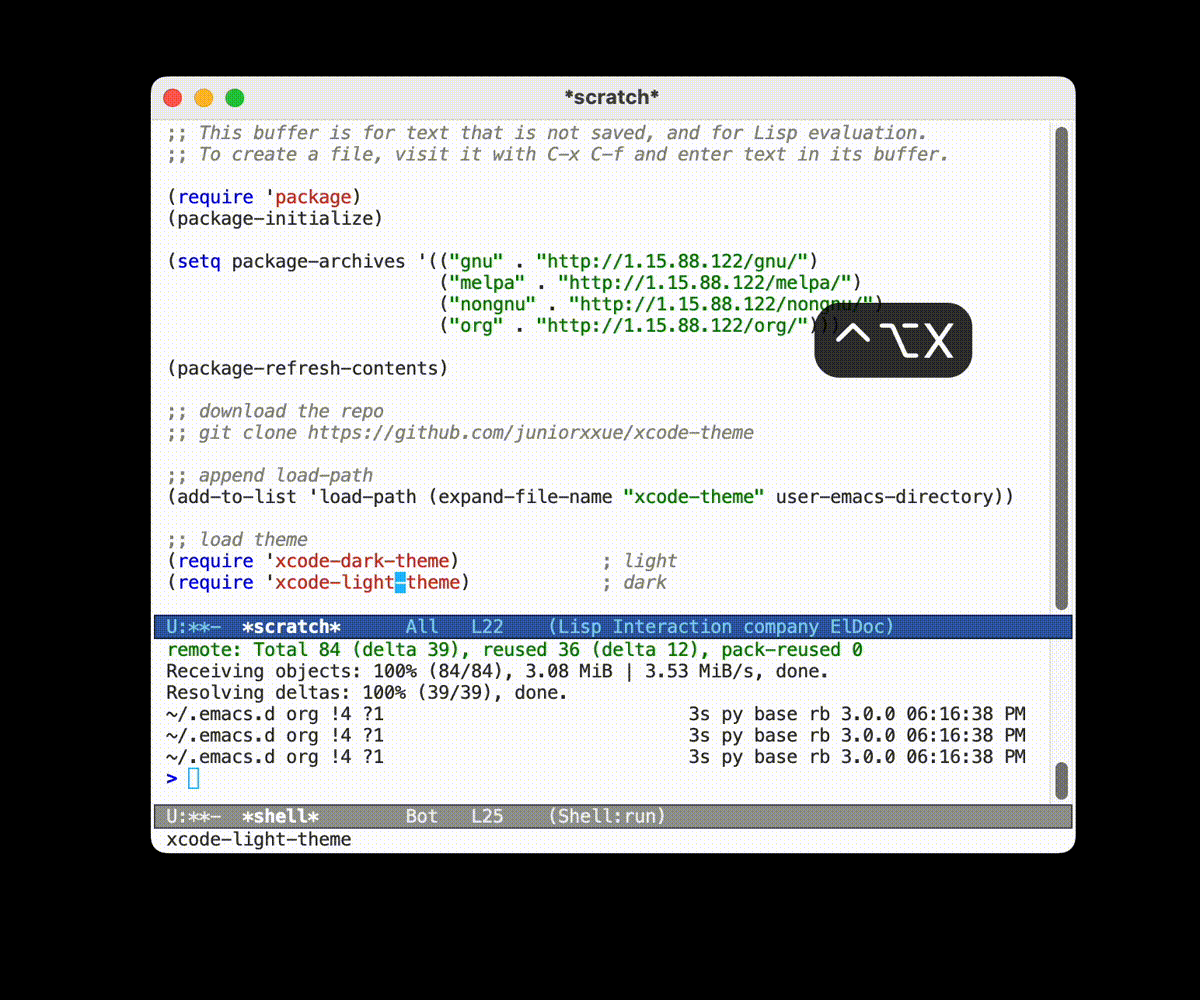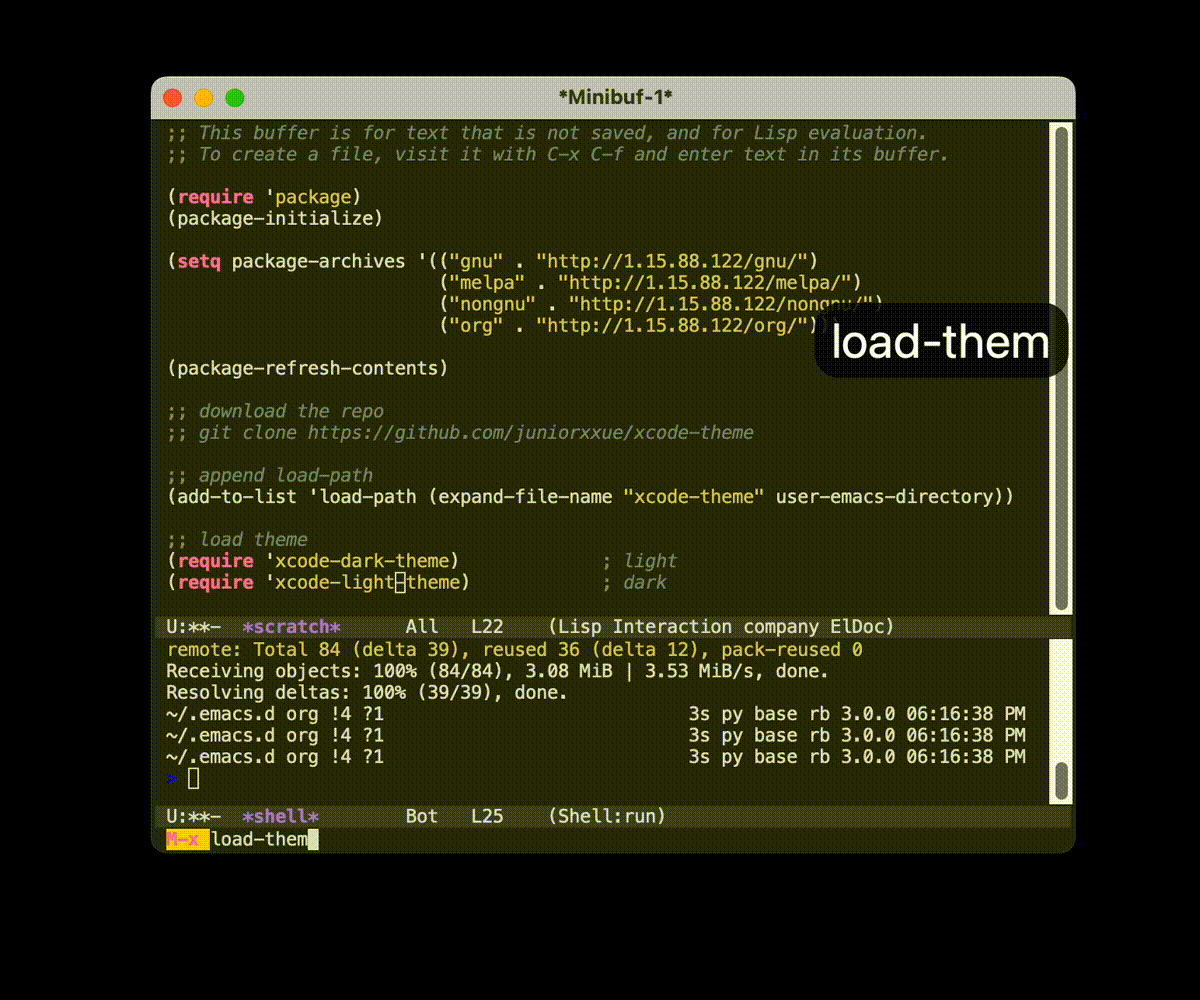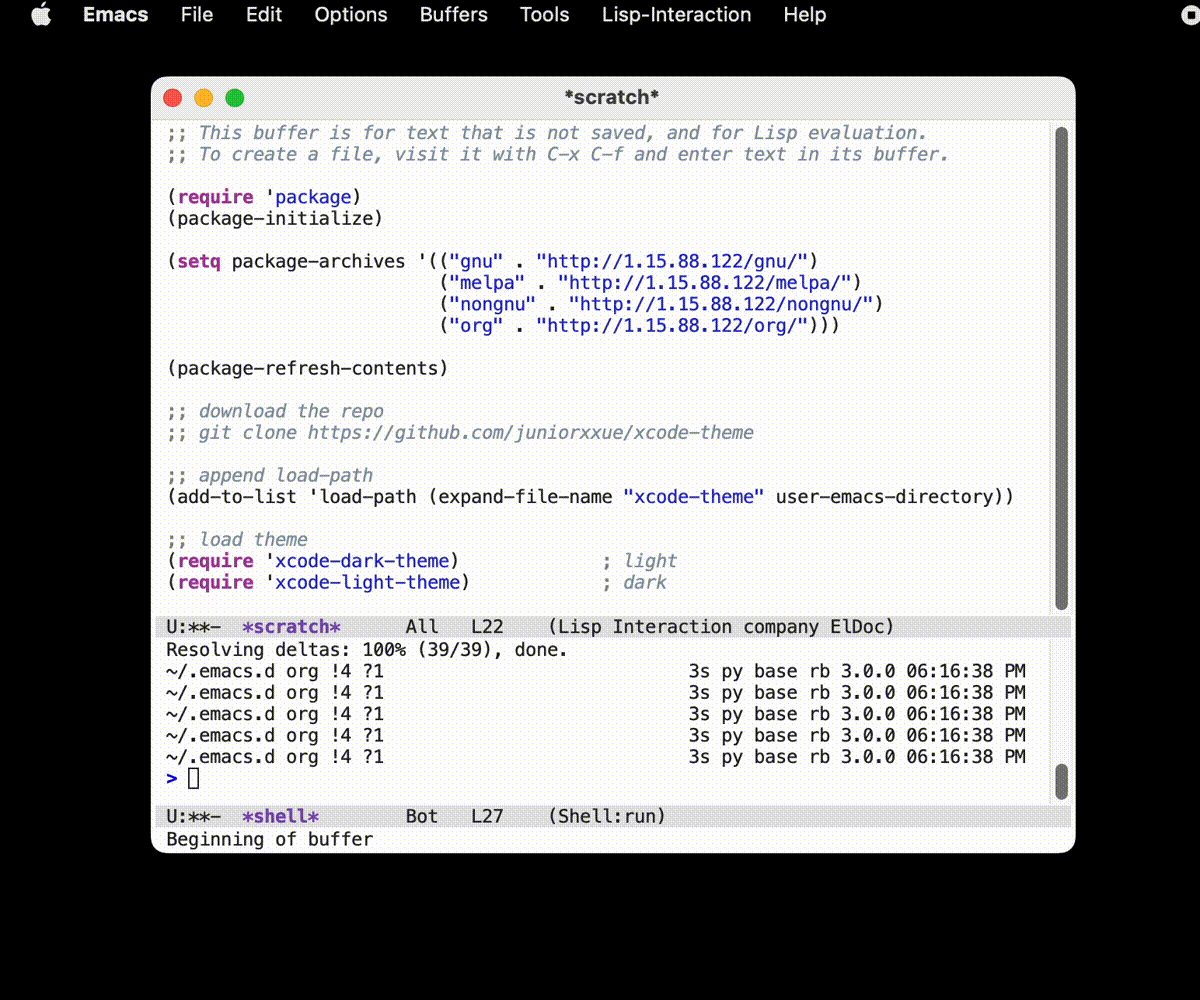
不详细的介绍
在很久很久以前, 世界上还没有 MELPA, 在广袤的互联网大地上, 一群程序猿从一块 FTP 大陆迁移到另一块 FTP 大陆上, 自由的代码通过被拷贝的形式从一只程序猿手中传递到另外一只, 这些程序猿将这些代码绑在自己的 Emacs 棒子上, 于是最后形成了巨大而又强力的武器.
不过还好, 最后这样的武器不是核武器. 人们相信自由的代码可以让世界变得更好.摘自: 《故事瞎编》
- 如果没有 MELPA 的话, 实际上使用直接复制代码的方式也是极好的
- 首先去 仓库 里面可以看到如何使用的说明.
- 只需要将下载的代码的地址添加到
load-path中, 然后使用(require 'xcode-light-theme)即可调用对应的模块了 - 大部分的代码都是类似的操作的.
load-path是一个文件地址的列表, Emacs 会在这个列表里面列出来的文件地址里面查找要require的模块.
现在你已经有了一个人模狗样的一个界面了, 如果不喜欢这个界面的话, 可以换成别的, 但是理论上来说, 你已经会几乎所有的包安装的方式了:
- 使用 MELPA 进行安装:
(package-install 'package-name) - 使用直接下载代码安装的方式:
(add-to-list 'load-path ...)
关于还要用什么包来帮助工作, 还是在之后遇到实际问题的时候再详细介绍吧. 一个贴心的小提示: 有时候, 某些插件可能真的很好用, 但是如果你从来没用过, 或者懒得去学的话, 其实也没有必要去安装的.
毕竟, 本文只是一个非常简单的入门教程.
Use-package 能不能把这事情做得更加优雅一点? (Optional)
对于初学者, 实际上配置文件写得丑一点就丑一点呗, 乱一点就乱一点呗.
但是, 如果你也有: “啊, 我想要一个非常漂亮的配置文件代码. ” 的愿望的话, 那么我的建议是: 别跟着我学欸, 看看真的大佬是怎么做的啊… (bushi)
那么我的建议是: 可以试试看使用 use-package 来规范你的配置文件代码. 如果有兴趣的话, 可以点开下面看看:
Use-Package 个人向的介绍
Use-package, 实际上还是一个宏, 它会将其中的代码展开成对应的 Emacs Lisp 代码.
举一个例子, 以安装 company-mode 为例:
- 普通的代码:
(package-install 'company) (require 'company) (global-company-mode)
- 使用 use-package 重构:
(use-package company :config (global-company-mode))
是不是看起来更加简单一点了呢?
载入 use-package
在 Emacs 29 以后, use-package 随着 Emacs 自带了,
于是在 (package-refresh-contents) 之后,
可以直接 (require 'use-package) 来载入 use-package.
然后在之后的代码里面就能够使用 use-package 了.
如果你的版本比较低
(unless (package-installed-p 'use-package)
(package-install 'use-package))
(require 'use-package)
use-package 和它的一些按键绑定 :bind
以一个 mini-buffer 插件 ivy 为例,
这里会介绍如何使用 use-package 的 :bind 关键词.
正如其名, :bind 关键词是用来 “绑定” 按键和函数的.
比如我们想要一个 C-s 按键来搜索:
(use-package ivy
:bind ("C-s" . swiper-thing-at-point)
:config (ivy-mode 1))
(use-package counsel
:bind (("M-x" . counsel-M-x)
("M-y" . counsel-yank-pop)
("C-M-z" . counsel-fzf)
("C-x C-b" . counsel-ibuffer)
("C-M-f" . counsel-ag)
("M-u" . counsel-unicode-char))
:config (counsel-mode 1))
上面的代码和下面的代码大致是等效的:
(require 'ivy)
(global-set-key (kbd "C-s") 'swiper-thing-at-point)
(ivy-mode 1)
(require 'counsel)
(global-set-key (kbd "M-x") 'counsel-M-x)
;;; ...
(counsel-mode 1)
显然, 使用 use-package 来绑定按键更加简单和轻松.
use-package 和 :init 与 :config
经常会看见别人的配置文件中, 使用 use-package 的代码里面会有 :init 和 :config,
那么这两个有什么区别呢?
这里是文档所写的:
:init Code to run before PACKAGE-NAME has been loaded.
:config Code to run after PACKAGE-NAME has been loaded. Note that
if loading is deferred for any reason, this code does not
execute until the lazy load has occurred.
但是看了网上的注释之后, 感觉更加迷糊了, 总而言之, 貌似无脑使用 :config 就好了 (吗?)
使用 use-package 不会将包立刻载入 Emacs 的内存中,
而是在用到的时候才载入. 在载入之后, 会执行 :config 关键词后的代码;
而 :init 关键词中的代码, 则类似于在 use-package 函数执行的时候,
立刻执行的代码. (在包载入前执行).
尽管目前还没遇到这么复杂的问题, 之前都是直接复制代码的 (雾).
use-package 和 :hook
假如想要在开启了某模式 (比如开启了一个 major mode) 后,
跟着开启其他的 minor mode, 可以使用 hook 来进行操作.
以 company-mode 为例, 如果想要其在程序模式 (prog-mode) 下自动打开. 在使用 use-package 的时候就应当以如下的形式来进行:
(use-package company
:hook (prog-mode))
和如下的形式等价:
(add-hook 'prog-mode-hook company-mode)
或者可以写成如下形式:
(use-package company
:hook ((prog-mode . company-mode)))
一个更加详细的解释:
- 在 Emacs 里面, 可以使用 hook 来进行类似于事件的绑定
- 一个 hook 类似于一个函数列表, 在对应的事件发生的时候, 就会执行这个函数列表里面的函数.
- 一个
add-hook的函数, 类似于将一个函数放到对应的 hook 里面. - 而 use-package 中的
:hook关键词可以将 mode 对应的 hook 和函数进行绑定.对于
:hook (prog-mode)的形式, 相当于是将prog-mode-hook和company-mode进行绑定. 而:hook ((prog-mode . company-mode))类似.当然, 你也可以来一点自定义的函数:
(use-package company :hook ((prog-mode . company-mode) (company-mode . (lambda () (message "Company Mode is Working Background. ")))))
use-package 和 :load-path
简单地来说 use-package 用的还是 MELPA, 但是并不局限于 MELPA.
如果想要让 use-package 来使用本地下载的包,
便可以使用 :load-path 关键词来进行.
比如:
(let ((xcode-theme-path (expand-file-name "xcode-theme" user-emacs-directory)))
(use-package xcode-theme
:load-path xcode-theme-path
:config
(require 'xcode-light-theme)
(require 'xcode-dark-theme)))
或者:
(use-package xcode-theme
:load-path "~/.emacs.d/xcode-theme")
(注: 不是很清楚是否在任何机器上, 后者都能够成立, 所以还是比较推荐前者. )
那么, Org-Mode
嗯, 作为一个 正经的 的物理系学生.
显然, Emacs 还是应该服务一下日常的生活和使用吧.
假设到了这里你应该会的东西
为了防止之后我写出了一些奇怪的超出当前已经知道的知识的部分, 所以我在这里做一个小小的注记:
- 能读懂简单的 Emacs Lisp 代码 (指 List 和 Atom)
- 已经了解了简单的包安装 (不论是直接使用
package-install还是use-package)
Org-Mode 最简单的语法
如果你已经学过了 Markdown 语法的话, 上手 Org-Mode 应该是非常轻松的. 但是哪怕一点也没有学过的话, 上手也是非常轻松的.
在 Org-Mode 中, 有下面的一些组成的元素:
- 标题 (形式上为以若干个
*开头, 使用不少于一个空格分隔标题内容的东西)一些例子
* 一级标题 ** 二级标题 *** 三级标题 ... - 标记符号 (这里只是一些最基本的)
标记码 效果 注释 *粗体*粗体 被一对 *包围/斜体/斜体 被一对 /包围_下划线_下划线 被一对 _包围=代码=,~代码~代码,代码被一对 =或者~包围[[链接]],[[链接名字][链接地址]]链接 (注: 点不了的, 小傻瓜) 可以用 C-c C-l来快速插入和编辑, 并且链接可以用来插入文件和图片之类的东西 - 列表 (一般使用
+来作为无序列表,1.的形式作为有序列表)一些例子
* 列表 ** 无序列表 + 项 + 项 ** 有序列表 1. 一 2. 二 - 表格 (因为之后要说, 所以暂时不太展开介绍)
一些超级简单的介绍
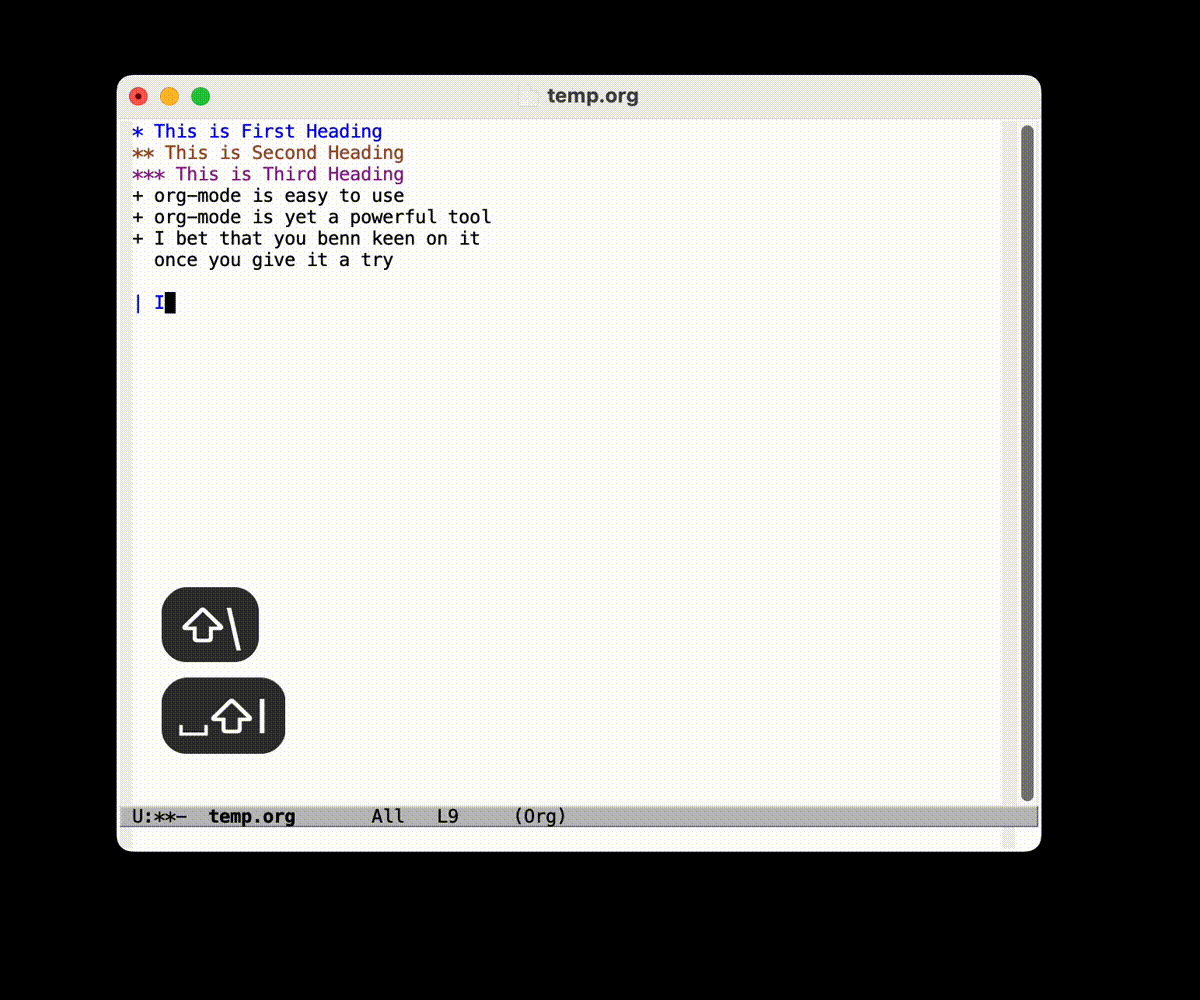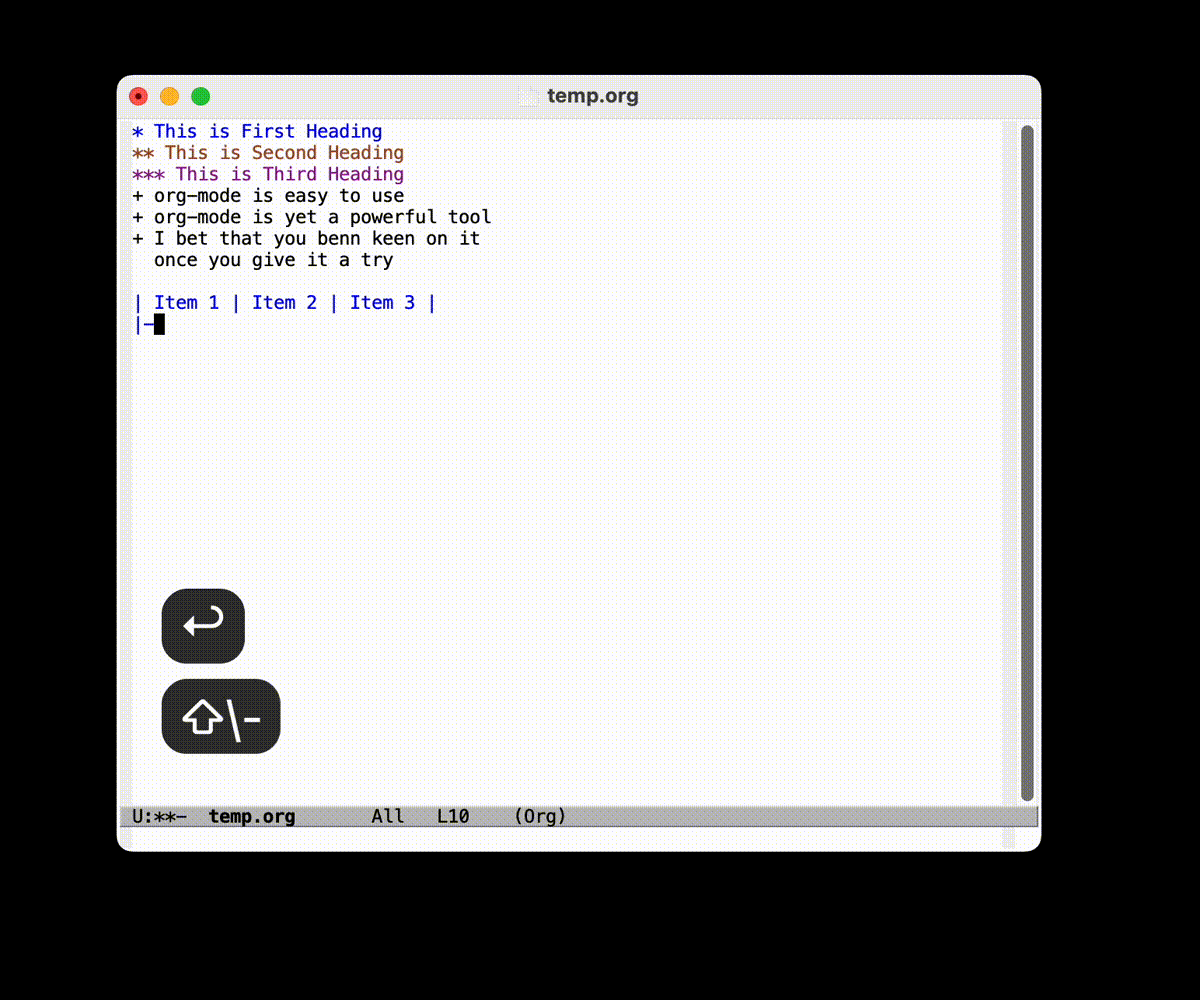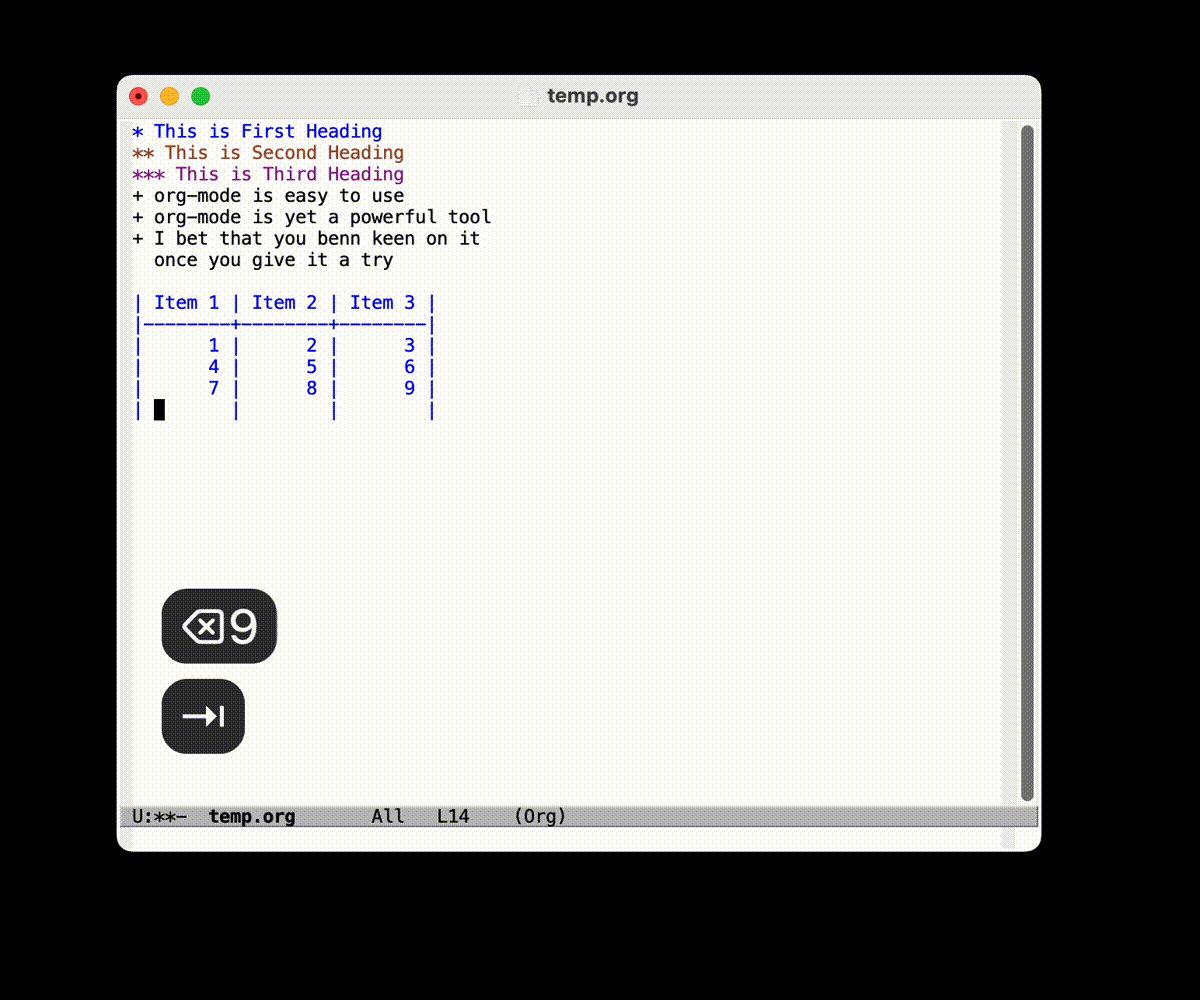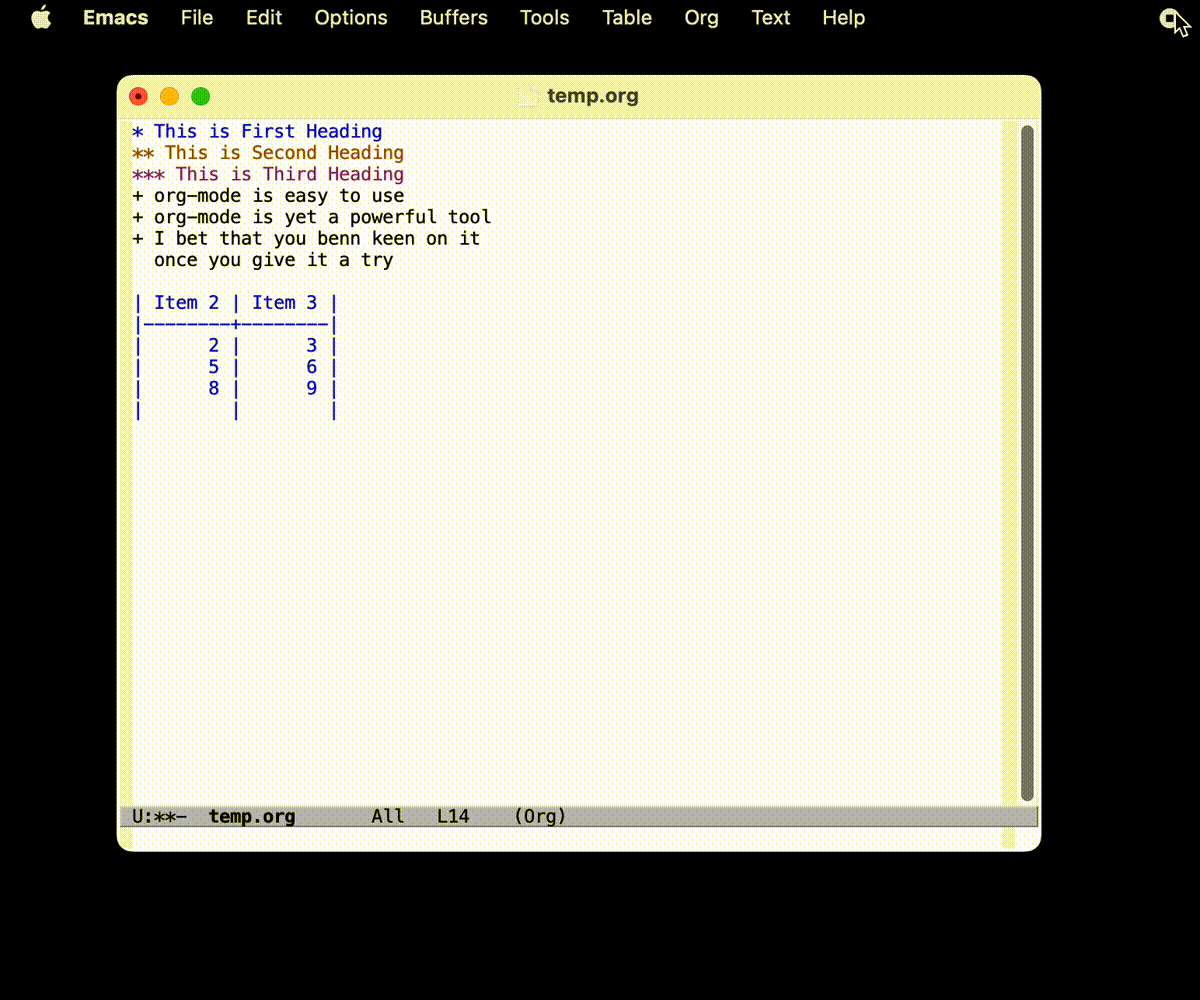
- 通过
TAB键可以补全, 跳转, 规整表格 - 通过
|来分隔每一列 - 通过
|--|--|的形式加入中间横向分割线 M-x org-table-delete-column可以删除列
- 通过
- 块 (一般可以用 =C-c C-,= 来辅助插入)
比如代码块 (
C-c C-, s):#+begin_src emacs-lisp (+ 1 2) #+end_src一些注释
虽然你可能会觉得这样写起来感觉挺麻烦的, 但是实际上体验超级棒的:
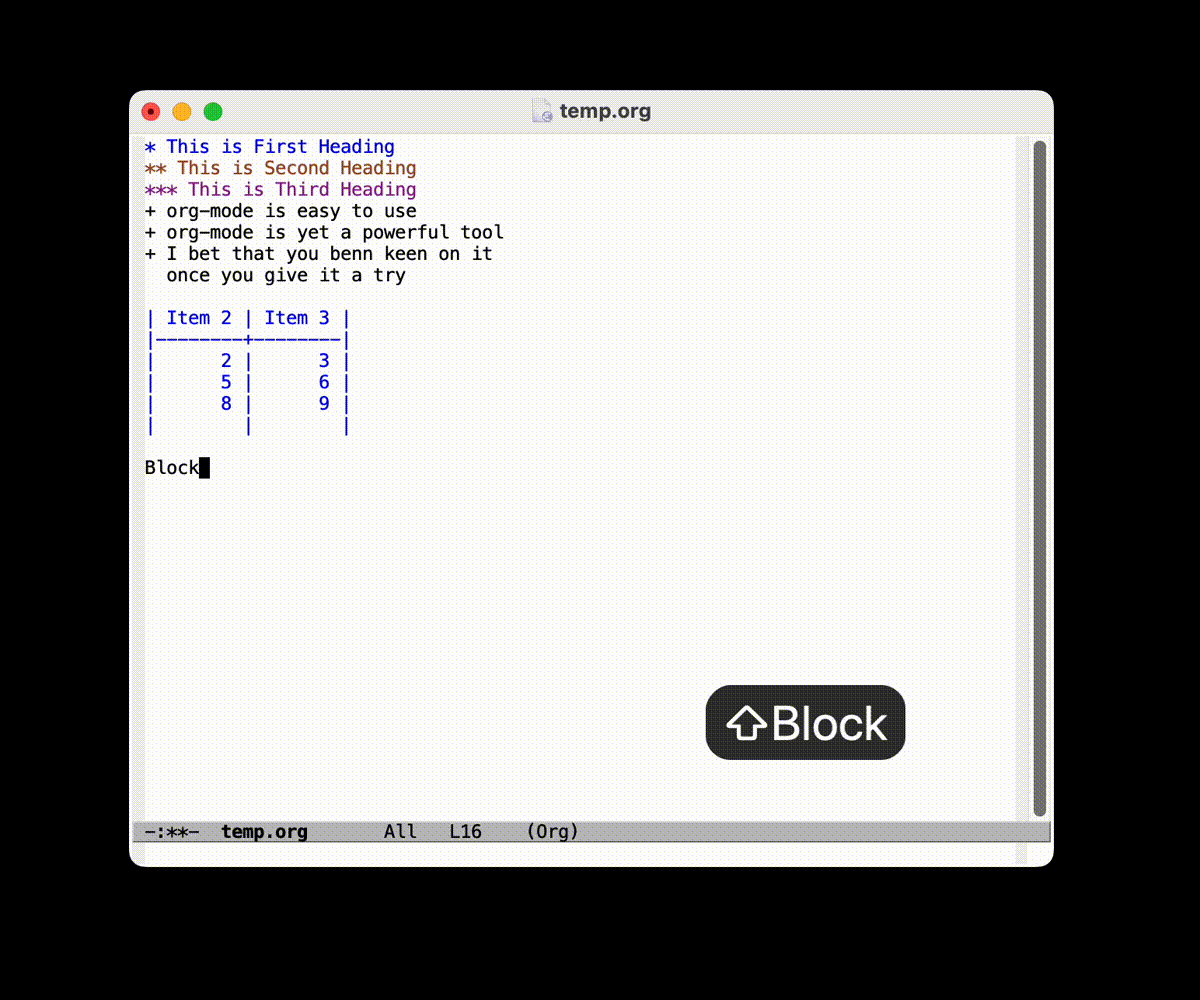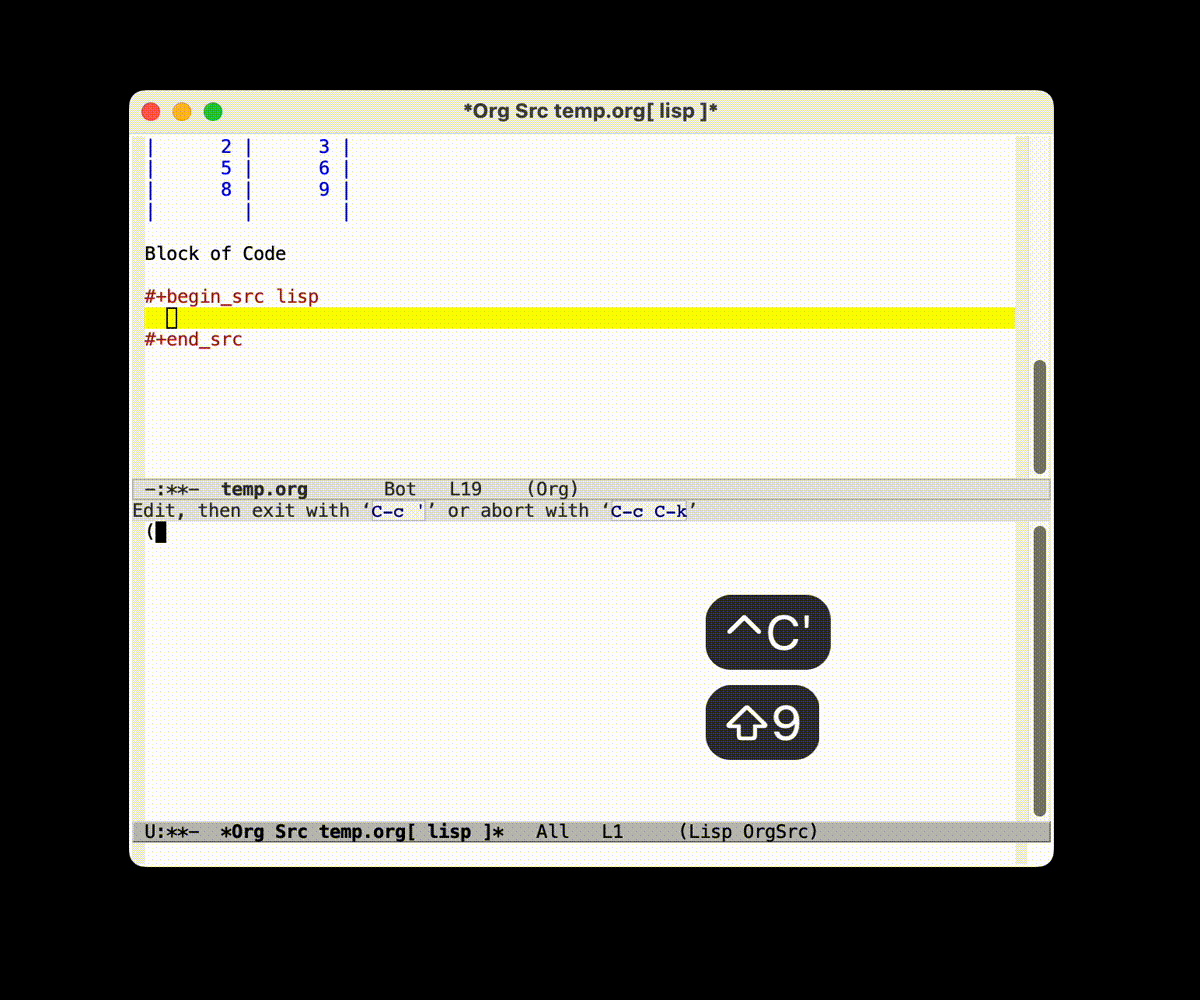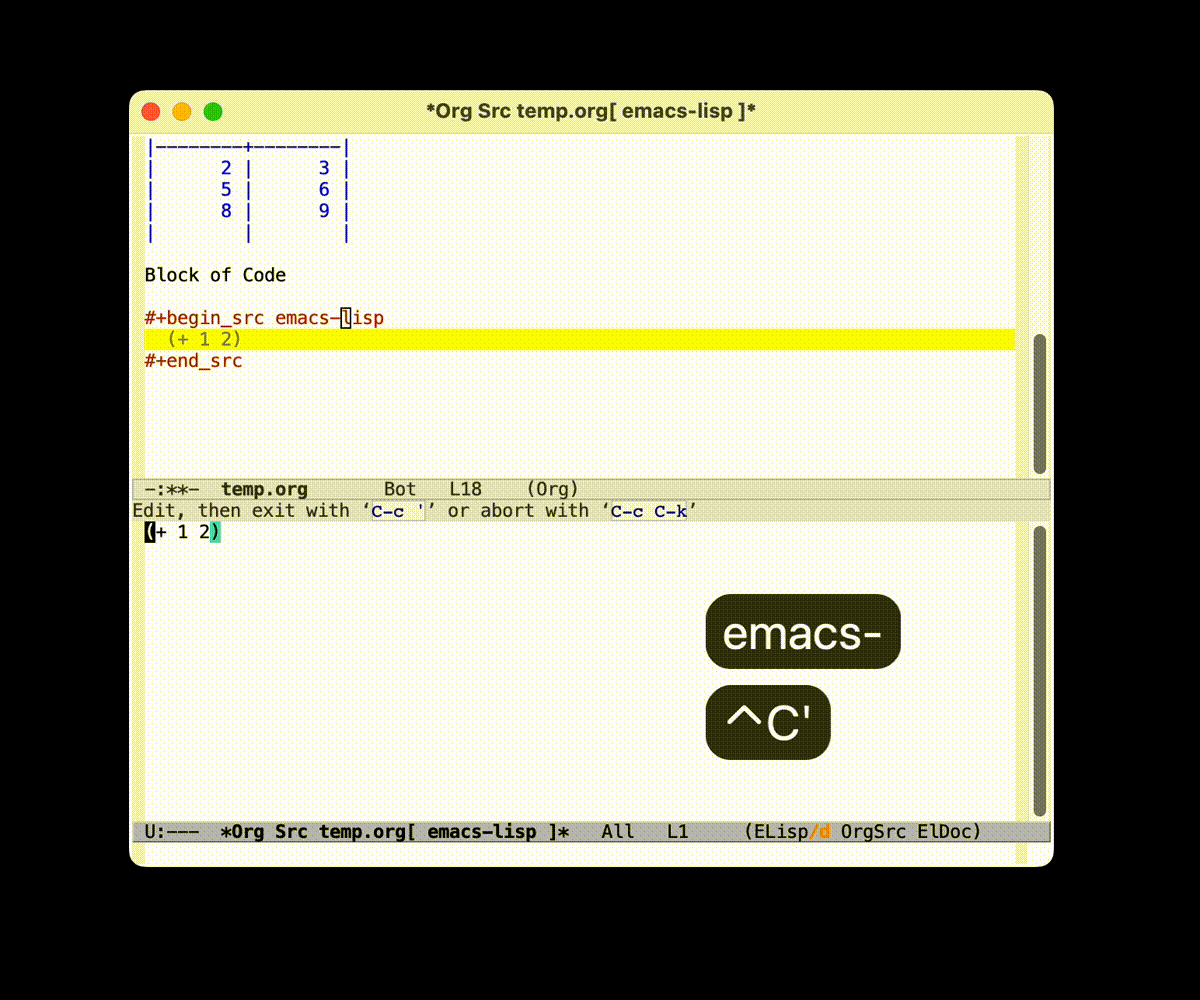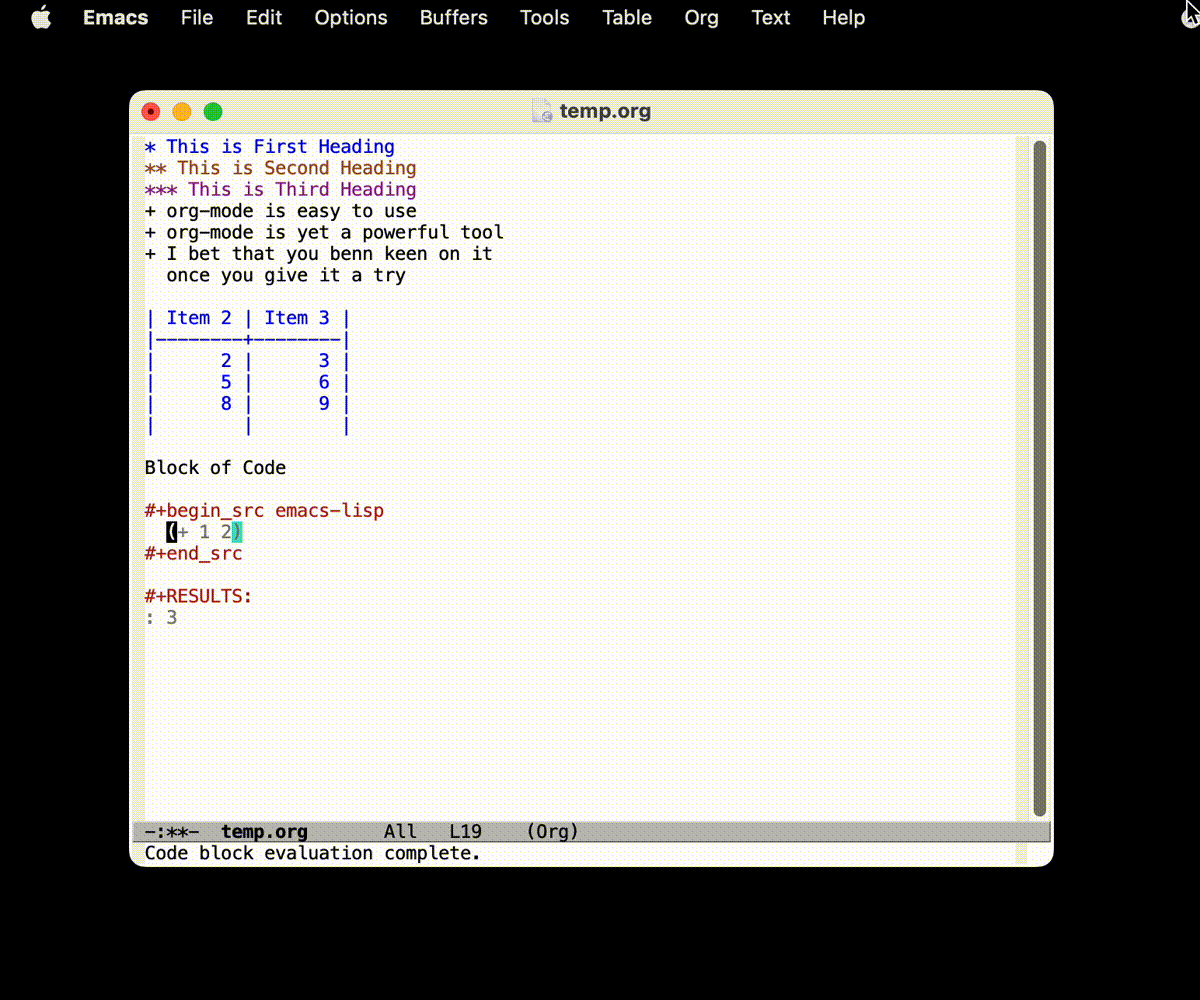
- 使用 =C-c C-,= 系列的快捷键可以快速插入块结构
- 将光标移动到块结构上, 使用 =C-c '= 快捷键可以单独编辑, 单独编辑完后使用 =C-c '= 可以保存并退出
- 将光标移动到块结构上, 使用
C-c C-c快捷键可以直接运行块代码
- 数学公式 (通过
C-c C-x C-l来渲染当前节中的所有的数学公式, 不过需要提前安装 LaTeX 的包, 毕竟是用 LaTeX 进行渲染的. )比如
\(\alpha\),\[\Sum\]之类的.一些注释
一个比较 Trick 的事情是这样的: 数学公式在 Emacs 确实能够很好地显示, 但是不一定能很好地显示 (因为不同的平台的特性不同).
所以我选择不截图以免因为图片太丑劝退一些最小的配置可能如下:
(setq ;; LaTeX equation preview scale (1.8 is my personal settings) org-format-latex-options (plist-put org-format-latex-options :scale 1.8) ;; use svg for preview, which is sharper than png (but little slower) org-preview-latex-default-process 'dvisvgm ;; use xelatex as LaTeX compiler org-latex-compiler "xelatex" ;; Replace sequence with pretty symbols, ;; for example: \alpha -> ɑ org-pretty-entities t ;; if you don't want org-mode to deal with subscript and superscripts ;; org-pretty-entities-include-sub-superscripts nil )
不过如果要在 Org-mode 里面绘制非常漂亮的图片, 并且可以非常轻松地编辑公式, 可能还需要一些小小的操作:
(package-install 'auctex) ; LaTeX support (package-install 'cdlatex) ; For faster LaTeX input ;;; Note: if you are using use-package, ;;; you should use the code: ;;; (use-package tex) ;;; and then ;;; (use-package cdlatex)
其中:
- auctex 用于给 Emacs 提供一个更好的 LaTeX 体验
- cdlatex 用于在 Org-Mode 里面可以通过按下简单的按键组合就能够轻松插入 LaTeX 的体验:
- 按下
`后再按下其他按键可以对应输入相应的 LaTeX 符号, 比如` a即会输入 \(α\) 对应的\alpha.如果不知道要按什么的话, 可以多等待 (默认是 1.5s), 会弹出一个帮助窗口来提示接下来的按键.
如果想要插入
`的话, 通过C-q `就可以了… (虽然麻烦了点, 不过不会有人真的这么背, 要一直输入这个符号吧… 若是写代码, 在代码块里面 =C-c '= 不香么? 再不济还能自己改按键就是了. ) - 在 LaTeX 数学公式中, 按下 ='= 可以插入修饰符. 同样, 会在等待一段时间后弹出提示窗口.
- 更多的我也很少用了就是. 比如:
- 在数学公式内通过
fr,lr(等快捷绑定配合TAB插入内容 TAB键在公式内快速跳转C-c {插入数学环境
- 在数学公式内通过
- 按下
到了这一步, 基本上你就可以像是写 Markdown 一样来写 Org-Mode 文档了.
唯一的区别可能就是体验会好一些
Org-Babel 在文档中运行程序 - Property 的初识
尽管是物理系的, 但是平时估计还是程序写得比较多, 毕竟我是一个籍希望于未来能够通过计算机解放大部分计算过程的懒人嘛.
本节作用:
- 介绍如何在 Org-Mode 里面运行程序 (以 Graphviz 为例)
- 如何使用简单的 Property 来修改文档的表现
Graphviz 绘制 (不只) 流程图
在做笔记的时候, 可能会需要使用流程图来进行记录, graphviz 就是一种用来帮助干这种事情的程序.
简单地一个 安装 之后, 在 Org-Mode 中插入以下代码:
#+begin_src dot :file path/to/save/file
digraph finite_state_machine {
rankdir=LR;
node [shape = point]; qi qa;
node [shape = circle];
qi -> 1;
1 -> 2 [label = "h"];
2 -> 3 [label = "a"];
3 -> 2 [label = "h"];
3 -> 4 [label = "!"];
4 -> qa;
}
#+end_src
然后使用 C-c C-c 快捷键就能够运行并输出图片:
#+RESULTS: [[file:path/to/save/file]]
对应的图片显示如下 (通过 C-c C-x C-v 来显示图片):

如何自动显示图片?
使用 org-babel-after-execute-hook 来进行处理:
(add-hook 'org-babel-after-execute-hook #'org-redisplay-inline-images)
;;; Note: if you are using use-package
;; (use-package org-mode
;; :hook ((org-babel-after-execute . org-redisplay-inline-images)))
注: 在我这里 C-c C-x C-v 是绑定着 org-toggle-inline-images 的函数,
其功能为切换图片是否显示的状态.
org-redisplay-inline-images 是重新显示图片. 两个还是有点不一样的.
那么让我来简单介绍一下 Graphviz 的使用方法
- 无向图
graph和有向图digraphdigraph { 有向图 | graph { 无向图 A -> B; | A -- B; } | }
显然, 和数据结构类似, 图包含的对象有: 节点, 边, 和图, 故在标记属性的时候, 大部分情况下就只需要标记这三个元素的属性.
- 一个节点可以直接用显示的内容来表示:
A, =”显示 de 内容”; 也可以使用 =label来标记其显示的内容:n1 [label = "显示 de 内容"]. - 一般来说, 通过入边数量和出边数量来判断节点的前后层级顺序,
通过 graph 属性
rankdir来确定一个图的前后顺序该如何排布, 比如LR(left-to-right),TB(top-to-bottom, 默认值). - 可以给边赋标记
A -> B [label = "This is A Label"] - 简单地来说, 就是这么多, 通常无脑进行排版也是能看的, 但是有时候可能会想要更加精细的控制的话, 就需要一些更加复杂的操作了 (可以自行查看 官网 的文档, 或者 GraphViz Pocket Reference 以及 Graphviz (dot) examples)
那么故事的主线是这样的, 如果我们想要改变这个最终输出的图片在 Org 文档中显示的大小, 那么该怎么办?
(比如说, 生成的图片太大了之类的)
首先, 我们先将 org-mode 默认的以图片本来大小显示的选项关闭:
;;; When non-nil, use the actual width of images when inlining them.
;;;
;;; When set to nil, try to get width from an #+ATTR.* keyword
;;; and fall back on the original width if none is found.
(setq org-image-actual-width nil)
然后在前面的代码里面, 添加一个小小的属性选项:
#+attr_org: :width 500px #+RESULTS: [[file:path/to/save/file]]
(上面按 500px 宽度来显示图片, 嘛, 既然都在 org-mode 里了,
那么怎么显示就由不得图片了. )
这个就是属性标记了 (property). (目前这种的) 其形式类似于如下:
#+key: value. 比如说, 我们还能够给前面的绘制图像的代码命名:
#+name: Hahahaha-finite-state-machine
#+begin_src dot :file path/to/save/file
digraph finite_state_machine {
rankdir=LR;
node [shape = point]; qi qa;
node [shape = circle];
qi -> 1;
1 -> 2 [label = "h"];
2 -> 3 [label = "a"];
3 -> 2 [label = "h"];
3 -> 4 [label = "!"];
4 -> qa;
}
#+end_src
命名后的代码块, 就可以在文档中被作为链接来进行引用了,
比如 [[nameref:Hahahaha-finite-state-machine][Label]]
(当然, 我认为通过 C-c C-l 插入, 不仅有补全提示,
还有自动帮助, 各种意义上都非常简单…)
实际上, 属性标记在使用代码块输出文件的时候就已经有体现了:
#+begin_src dot :file path/to/save/file
其中 :file path/to/save/file 就是一个键值对,
描述了 :file 也就是输出的文件应该保存在哪里.
稍微更加漂亮一些的 Graphviz
来看看在 Simple Regexp for Parser 里面我整的这个正则表达式和自动机的对应, 显然, 里面的代码不可能真的全部都手动写 Graphviz 来实现, 这样太蠢了.
虽然大部分确实是手动生成的, 因为我是笨蛋. 不过就算我是笨蛋, 我也是用代码生成部分, 然后进行修改的笨蛋.
一个朴素的想法是: 为什么不写代码来自动化生成呢? 欸, 好想法, Python 的 graphviz 包就是用来干这个的 (尽管我想不明白, 很多的教程就是将这个包作为 graphviz 的替代来教的…)
但是何必为了画个图然后学一个新的表示呢? (哪怕你会 Python, 也会 Graphviz, 但是使用 graphviz 包仍然要学它的函数和封装, 这太怪了. )
有了 Org-mode, 你可以直接用 Python 程序化地输出一段 graphviz 代码, 然后直接调用 graphviz 来绘制这个代码. 不信? 让我们来举个例子:
以 计科导的图灵机 from, read, write, move, to 为例:
一个图灵机代码的例子
q0, +, +, R, q0 q0, =, =, R, qa q0, 1, e, R, q1 q0, E, E, L, qa q1, 1, 1, R, q1 q1, +, +, R, q1 q1, =, =, R, q1 q1, B, 1, L, q2 q2, 1, 1, L, q2 q2, +, +, L, q2 q2, =, =, L, q2 q2, e, 1, R, q0
Note: 其名字我取为 turing-machine-code-example.
#+name: turing-machine-code-example #+begin_example
用 Python 的代码来处理就是:
for line in map(lambda x: map(lambda keyword: keyword.strip(), x.split(",")),
filter(None, code.split("\n"))):
from_state, read_char, write_char, move, to_state = line
print("\"{}\" -> \"{}\" [label = \"{}, {}, {}\"];"
.format(from_state, to_state, read_char, write_char, move))
"q0" -> "q0" [label = "+, +, R"]; "q0" -> "qa" [label = "=, =, R"]; "q0" -> "q1" [label = "1, e, R"]; "q0" -> "qa" [label = "E, E, L"]; "q1" -> "q1" [label = "1, 1, R"]; "q1" -> "q1" [label = "+, +, R"]; "q1" -> "q1" [label = "=, =, R"]; "q1" -> "q2" [label = "B, 1, L"]; "q2" -> "q2" [label = "1, 1, L"]; "q2" -> "q2" [label = "+, +, L"]; "q2" -> "q2" [label = "=, =, L"]; "q2" -> "q0" [label = "e, 1, R"];
代码块属性如下:
#+name: turing-machine-code-example-python #+begin_src python :var code = turing-machine-code-example :results output
可以发现, :var 关键词将后面的变量进行了赋值,
将 turing-machine-code-example 的内容赋给了变量 code.
但是很明显, 这并不是一个合理的 Graphviz 代码,
但是既然有了前面的 Python 代码的例子, 现在也只需要照猫画虎地做就好了.
digraph {
rankdir = LR;
layout = fdp; sep = 2;
node [shape = circle];
$graph
}

其属性为:
#+name: turing-machine-code-example-dot #+begin_src dot :var graph = turing-machine-code-example-python :file path/to/export
(注: 虽然有点丑, 说实话, 但是我也没啥想要修改的想法…)
但是如果你发现了一个比较尴尬的事情: 这样写属性列表, 未免有点太长了吧.
嘿嘿, 谁说没办法解决的?
Org-mode 中, 你还能够将 property list 分开来写:
#+name: turing-machine-code-example-dot #+header: :file path/to/export #+header: :var graph = turing-machine-code-example-python #+begin_src dot
这样是不是就看起来更加得整洁了呢?
但是比如说, 如果你有一个属性, 在每个代码块里面都要写, 每个代码块都写的话, 就会看起来很麻烦, 那么要怎么办呢?
嘿, 还是有可以解决的办法: 也就是你可以在每一节里面, 通过
** section :PROPERTIES: :header-args: :var data = turing-machine-example :END:
这样的形式来指定共同的属性.
那么你是否会说, 难道就这? 非也, 我们还能够干一些更加好玩的事情: 比如将名字作为函数来使用: 比如我们还有如下新的图灵机代码
太长了折叠掉了先
q0, 1, 1, R, q0 q0, 0, 0, R, q0 q0, +, +, L, q1 q0, i, i, L, q1 q0, z, z, L, q1 q1, 1, i, R, q2 q1, 0, z, R, q3 q1, B, B, R, q3 q2, +, +, R, q2 q2, 1, 1, R, q2 q2, 0, 0, R, q2 q2, i, i, R, q2 q2, z, z, R, q2 q2, =, =, L, q4 q2, I, I, L, q4 q2, Z, Z, L, q4 q3, +, +, R, q3 q3, 1, 1, R, q3 q3, 0, 0, R, q3 q3, i, i, R, q3 q3, z, z, R, q3 q3, =, =, L, q5 q3, I, I, L, q5 q3, Z, Z, L, q5 q4, 1, I, R, q6 q4, 0, Z, R, q7 q4, +, +, R, q7 q5, 1, I, R, q7 q5, 0, Z, R, q8 q5, +, +, R, q8 q6, I, I, R, q6 q6, Z, Z, R, q6 q6, =, =, R, q9 q7, I, I, R, q7 q7, Z, Z, R, q7 q7, =, =, R, q10 q8, I, I, R, q8 q8, Z, Z, R, q8 q8, =, =, R, q11 q9, 1, 0, R, q12 q9, 0, 0, R, q13 q9, B, 0, L, q16 q9, *, 1, R, q16 q10, 1, 1, R, q14 q10, 0, 1, R, q15 q10, B, 1, L, q17 q10, *, 0, R, q16 q11, 1, 0, R, q14 q11, 0, 0, R, q15 q11, B, 0, L, q17 q11, *, 1, R, q17 q12, 1, 1, R, q12 q12, 0, 1, R, q13 q12, B, 1, L, q16 q13, 0, 0, R, q13 q13, 1, 0, R, q12 q13, B, 0, L, q16 q14, 1, 1, R, q14 q14, 0, 1, R, q15 q14, B, 1, L, q17 q15, 0, 0, R, q15 q15, 1, 0, R, q14 q15, B, 0, L, q17 q16, 0, 0, L, q16 q16, 1, 1, L, q16 q16, =, =, R, q30 q17, 0, 0, L, q17 q17, 1, 1, L, q17 q17, =, =, L, q18 q17, *, *, L, q17 q18, +, +, L, q18 q18, I, I, L, q18 q18, Z, Z, L, q18 q18, i, i, L, q18 q18, z, z, L, q18 q18, 1, 1, L, q19 q18, 0, 0, L, q19 q18, B, B, R, q20 q19, +, +, L, q19 q19, i, i, L, q19 q19, z, z, L, q19 q19, I, I, L, q19 q19, Z, Z, L, q19 q19, 0, 0, L, q19 q19, 1, 1, L, q19 q19, B, B, R, q0 q20, I, 1, R, q20 q20, Z, 0, R, q20 q20, i, 1, R, q20 q20, z, 0, R, q20 q20, +, +, R, q20 q20, =, =, R, q21 q21, 1, 1, R, q22 q21, 0, #, R, q23 q21, #, #, R, q23 q21, *, 1, R, q22 q22, 1, 1, L, q34 q22, 0, 0, L, q34 q22, B, B, L, q34 q23, 0, #, R, q23 q23, 1, #, L, q24 q23, B, B, L, q31 q24, #, #, L, q24 q24, =, =, R, q25 q24, 0, 0, R, q25 q24, 1, 1, R, q25 q25, #, 1, R, q26 q26, #, #, R, q26 q26, 1, #, L, q24 q26, 0, #, L, q27 q26, B, B, L, q29 q27, #, #, L, q27 q27, =, =, R, q28 q27, 1, 1, R, q28 q27, 0, 0, R, q28 q28, #, 0, R, q26 q29, #, B, L, q29 q29, 1, 1, L, q29 q29, 0, 0, L, q29 q29, =, =, R, q34 q30, 1, *, R, q14 q30, 0, *, R, q15 q31, #, B, L, q31 q31, =, =, R, q32 q32, B, 0, R, q33 q33, B, B, L, q34 q34, 0, 0, R, q35 q34, 1, 1, R, q35 q34, B, #, R, q35 q35, 0, 0, R, q36 q35, 1, 1, R, q36 q35, B, #, R, q36 q36, 0, 0, R, q37 q36, 1, 1, R, q37 q36, B, #, R, q37 q37, 0, 0, R, q38 q37, 1, 1, R, q38 q37, B, #, R, q38 q38, 0, 0, R, q39 q38, 1, 1, R, q39 q38, B, #, R, q39 q39, 0, 0, L, q39 q39, 1, 1, L, q39 q39, B, B, L, q39 q39, =, =, R, qa q39, #, #, L, q40 q40, #, #, L, q40 q40, 0, 0, L, q40 q40, 1, 1, L, q40 q40, =, =, R, q41 q41, 1, 0, R, q42 q41, 0, 0, R, q41 q41, #, 0, R, q43 q41, B, B, L, q39 q42, 0, 1, R, q41 q42, 1, 1, R, q42 q42, #, 1, R, q43 q42, B, B, L, q39 q43, B, B, L, q39 q43, #, #, L, q40
于是现在的绘制代码则变成了:
digraph {
rankdir = LR;
node [shape = circle];
$graph
}
其头属性如下:
#+name: another-turing-machine-code-example-dot #+header: :exports code #+header: :file ../_img/emacs/other-graphviz-turing-machine-example.svg #+header: :var graph = turing-machine-code-example-python(another-turing-machine-example)

这里用 turing-machine-code-example-python(another-turing-machine-example)
这样的形式来像函数一样地进行调用相应的代码块.
(虽然画出来的有点地狱绘图的感觉… )
Plot 和 Table
Org-Mode Export to …
在 Org-Mode 中写的程序可以被 “很轻松地” 导出到各种格式中去. 并且如果有耐心的话, 可以自定义各种各样的导出样式.
Org-Mode 可以让你文件按照各种形式导出, 只需要按下 C-c C-e 即可进行导出.
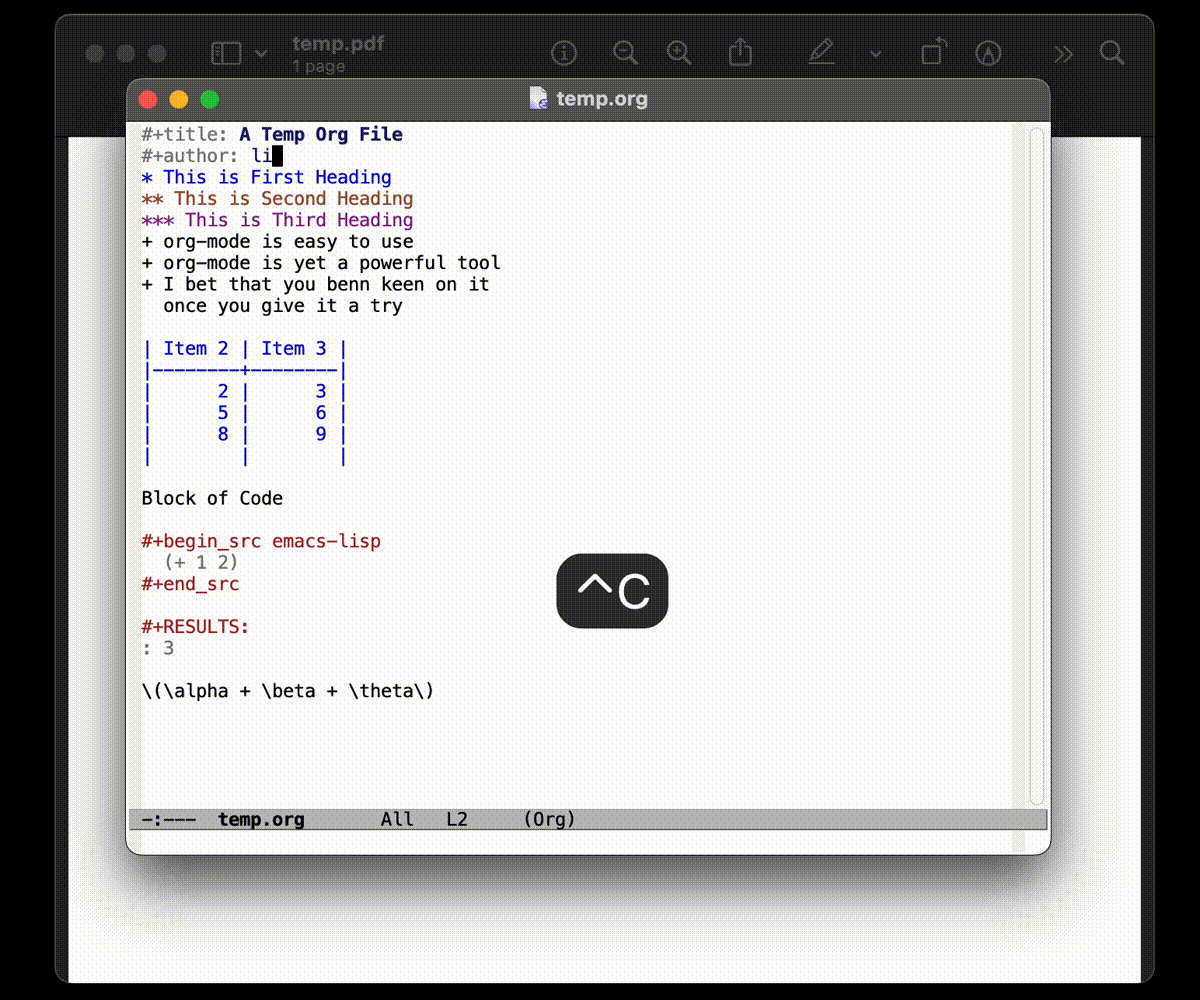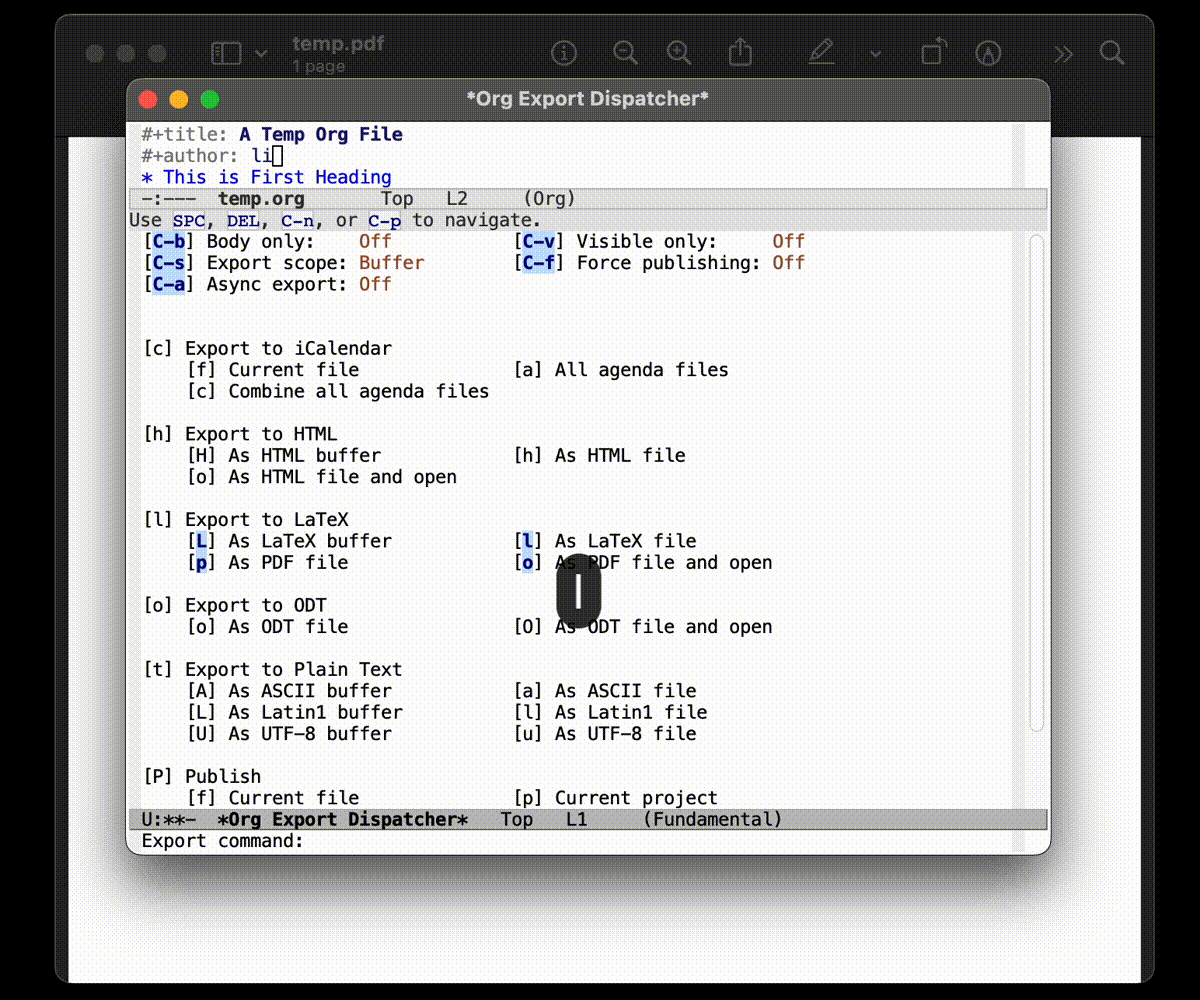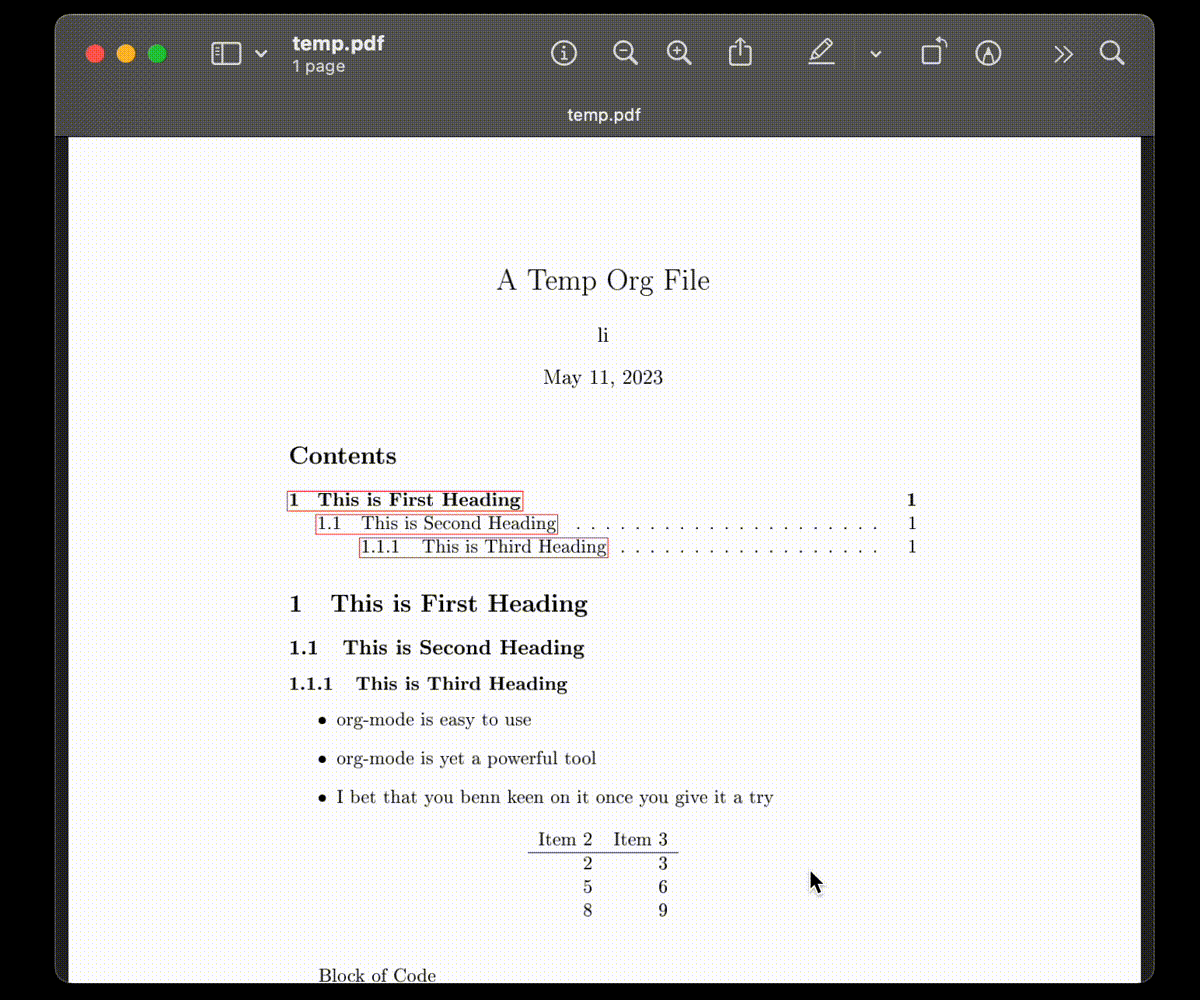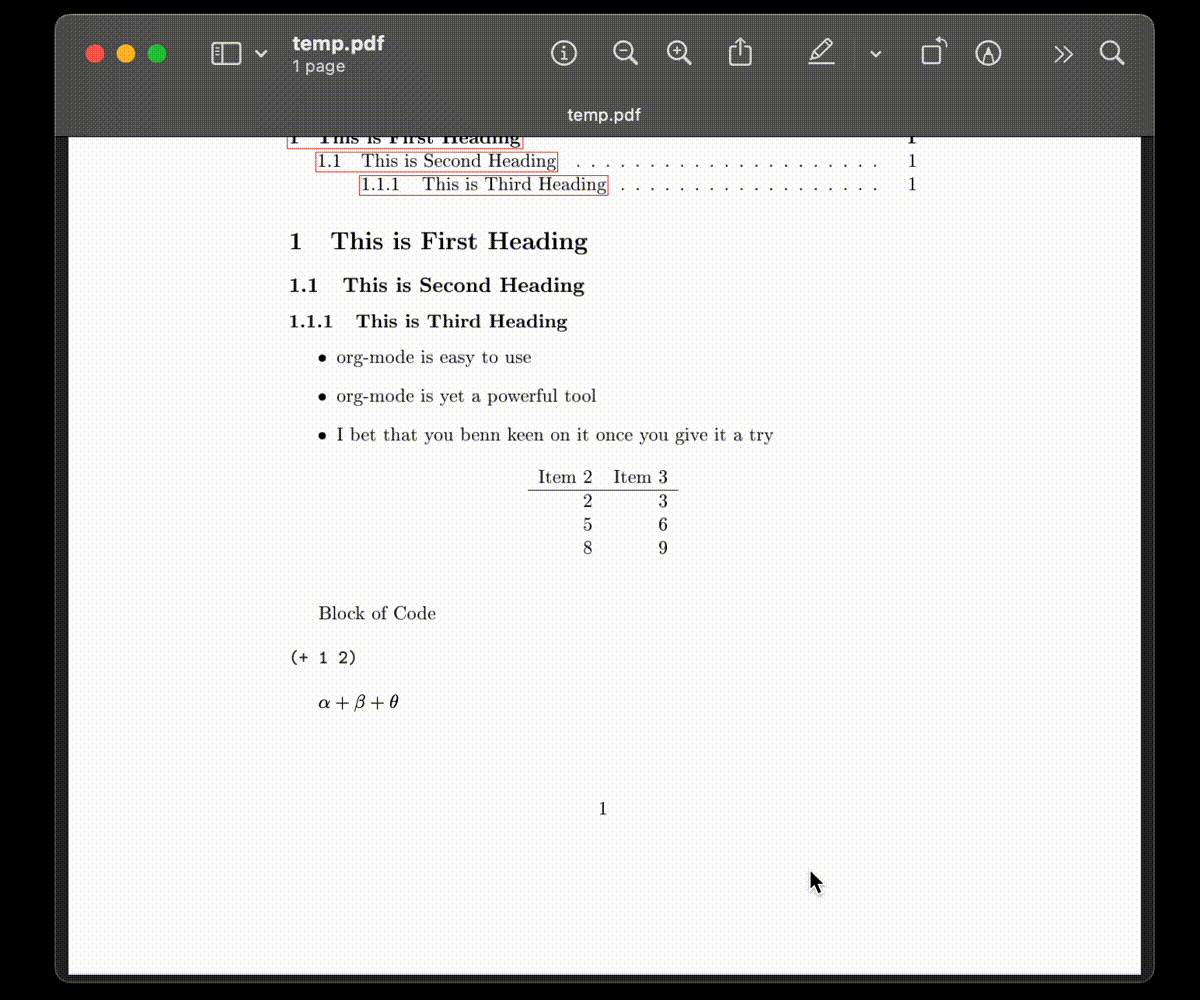
当然, 尽管 C-c C-e 可以通过直接调用对应的函数来实现,
但是你不觉得, 使用快捷键更加快吗? 并且还有提示和说明,
说得难听一点, 就是懒得移动鼠标, 只需要按几个按键就能够可视化操作的轻松的事情.
难道它不香吗?
那么如果想要让导出文件, 比如说导出的 LaTeX 文件 (毕竟这个更加常见吧) 更加好用的话 (因为如果你直接导出的话就会遇到一些问题, 因为有些关于 CJK 编码的问题.)
为了能够顺利地导出中文, 在 LaTeX 中我们应该如何呢? 答案是: 使用 ctex 包!
那么该如何在 Org-Mode 的导出里面, 加入对应的 ctex 包呢?
答案是: 使用 #+latex_header: \usepackage{ctex} 属性标签!
解释: #+latex_header: 的属性标签, 可以将之后的东西加到 Org-Mode 导出的 LaTeX 文件,
然后再通过对应的程序进行编译.
类似的还有 #+latex_compiler: 的属性标签, 可以指定使用的 LaTeX 编译器.
推荐使用 xelatex, 默认使用的 pdflatex 对中文的支持比较烂.
注: ox-org: Org-Mode 和 pandoc
那么如果你想要更加丰富的导出选项, 于是就可以使用 ox-org 包进行导出. 其使用的是 pandoc 作为后端进行变换的程序.
不过因为我平时使用的导出并没有很多的样式需求, 所以暂时没有那么多的经验… 等之后有时间再折腾.
顶多就是用用 org-pandoc-export-to-html5-pdf,
不过貌似常常会出问题, 所以还是很少用.
注: Org-Mode 和 HTML 导出
对于 HTML 的导出, 图片的导出可以使用 #+attr_html: :width ... 来进行导出.
不过平时大多是用默认的导出和 org-pandoc-export-to-html5 来导出的.
Back To Configuration File
那么, 现在让我们来重新看看我们的配置文件吧. 既然你已经了解了 Org-Tangle, 那么便可以试试用 Org-Tangle 来维护自己的配置了.
(当然, 如果你懒得改的话也没关系, 你迟早会受不了自己丑陋的代码回来重构的)
这里有一些我推荐比较好用的花里胡哨的包: (基础的包基本都装得差不多了嘛… )
- dashboard: 没什么别的用处, 就是能够在启动的时候显示一个可以自定义的欢迎窗口
- nyan-mode: 没什么别的用处, 就是能够在状态栏上显示一个彩虹猫猫作为进度条
- LSP: 不是
老色批- eglot: Emacs 29 以后自带的, 只需要通过
(require 'eglot)即可载入. (或者使用use-package也可以) - lsp-bridge: 目标是最快的 LSP 实现, 可以比 VSCode 快
- lsp-mode: 虽然慢了点, 但是力图在 Emacs 上实现所有 VSCode 的功能
- eglot: Emacs 29 以后自带的, 只需要通过
- Terminal (虽然使用自带的 eshell 或者 shell 和 term 也行)
- vterm: 功能最完整, 但是比较麻烦
- multi-vterm: 可以让 vterm 多开
- ebib: 文献管理
大概就这么多吧, 以后有时间就写具体的专题了. 目前的一个比较好奇和感兴趣的方向是文学编程和计算物理.
Further on?
如果你耐心地看完了这篇为了逃离期中考压力的废话文学的教程的话. 恭喜你, 现在可以去混迹论坛, 修修改改自己的配置, 然后专心用 Emacs 来写你的各种文件了.