TicTacToe AI
About
接下来几天, 我要进行一个 Blog 大产出 (注水),
回复 @sikesibian 对我近来博客没啥好活的质疑.
首先这一次关于是我最近做的 cl-webview 的一个简单的应用的例子, 配合之前看了一部分的 Common Lisp Modules 的 Part II 的一些简单知识. 灵感来源于跳蚤群里的一个学弟/妹的计算机科学导论大作业.
(就让学弟/妹们看看考完试的学长可以有多么浪吧)
(浪不了一点… 实验室里打工真快乐)
那么 CL Modules 的 Part II 哪里去了呢?
很遗憾, 答案是因为我发现书里面的模型其实已经非常老旧, 加上那段时间在忙着写 GURAFU 的代码 (主要是为了满足计算物理的论文), 原始的阅读笔记被改得乱七八糟, 估计之后重新阅读的时候可以考虑再写一个.
这部分我把它塞到了文章的后面.
(defpackage #:tictactoe
(:use :cl :cl-webview)
(:export #:run-tictactoe))
(in-package :tictactoe)
注: 我的代码应该写得还算注释清晰, 没有黑魔法的简单代码了, 欢迎入坑 Common Lisp.
TicTacToe
游戏是个简单的状态机
啊, 和正文有些无关, 折叠了
学过计算机科学导论的都应该对状态机非常熟悉了吧 (不熟悉的可以看: Make a Turing Machine Yourself, 虽然是图灵机而不是状态机; 关于为什么要学状态机, 除了体系结构以外, 在编译原理里也有应用: A Simple Regexp for Parser).
那么为什么会说游戏是个 “简单的” 状态机呢?
(以下参考: GDC Tunes of the Kingdom: Evolving Physics and Sounds for ‘The Legend of Zelda: Tears of the Kingdom’ (youtube),
在 b 站有人搬运和翻译, 可以搜索关键词: GDC 塞尔达 王国之泪)
在某个状态下, 由于用户做了某种事情而改变了状态: 比如你将炸弹花绑定到弓箭上, (有段时间没玩了, 考试嘛, 我记得会变红, 然后发出烟), 这里就有一个 “点燃”, “准备” 的状态切换; 同时, 在不同的状态下, 需要去做不同的相应: 比如你在死亡火山那边装备炸弹花… (强烈建议试试, 就是要小心会被偷袭 :p)
这里做的游戏都是一些简单的小游戏, 所以我们并不需要一个复杂的状态机机制. 对于一些比较简单的状态机, 人力还是可以 handle 的, 你大可以做一个 Excel, 然后把各种元素的相互关系做成一个相关矩阵, 然后进行人工跟踪.
但是复杂的状态机制呢? 一个想法就是写一个规则约束程序来进行辅助 (比如逻辑规约, 我的一个想法就是引入 ACL2 这样的推理引擎来辅助; 或者是 OPS5, LOOM 或者 Franz Knowledge Graph 这样的专家系统). 不过在上面塞尔达的例子里面, 开发者的做法是通过自己实现了一套物理模型 (物理规律) 以及声音渲染模型, 来处理不同情况下的事件以及声音渲染. (规则约束)
也许你会说, 那么最近很火的 LLM 的 AI 呢? 能否被应用到这种方面呢? 我觉得是可能的, 但是有一个问题: 站在玩家的角度, 我们并不需要知道游戏的背后究竟是什么, 哪怕这个游戏的背后是几百个印度抠脚老哥在跟你聊天也无所谓, 只要足够好玩; 而站在开发者角度, 我们需要的是一个可以快速实现原型, 快速开发修改迭代的工具/技术, 哪怕是我上面提到的专家系统, 逻辑规约系统, 看起来都已经非常自动化了, 但是实际上因为并没有对游戏开发流程进行优化 (不过我也并不知道是否真的有人/公司这么做), 这么看来其实还是很缺乏吸引力的. 毕竟手算 \(1 + 1\) 就行了的问题, 真的有必要引入一台计算机来帮忙吗?
叠甲: 并不是说技术并不重要, 比如渲染速度提高了, 玩家可以感知到, 这就是一种提升. 但是一味地追求开发技术的提升, 而让游戏的迭代和设计变得死板而难以修改, 就是一个比较大的缺憾了. (虽然我想说的是我目前也做不到这个事情, 只能说是以此为目标而已)
这里有一个我觉得完全是超帅的 demo: Tomorrow Corporation Tech Demo (youtube) (在 b 站上貌似没有人搬运). 我觉得绝对是一个正确可学习的方向:
- 我们需要有一个对状态机转移的跟踪, 不仅可以步进, 还要可以步退
我觉得最帅的就是这个部分, 以下是我对该方法的一个可能的实现的一个想法:
通过构造一个列表来记录已经历遍的状态, 就像是一个历史记录, 然后这样就可以去回溯这个历史记录, 同时也可以更改节点去切换, 进入一个新的状态节点.
不过这部分我的想法还不是很完善, 之后有空可以试试往这个方向做点小玩具.
- 动态调试和动态重载的功能 (Lisp… )
井字棋核心的落子与控制代码
(注: 在这里我会用 OOP 的方式来写代码, 不过需要注意的是, Common Lisp 是一个多范式的编程语言, 你完全可以用命令式的方法, 或者函数式的方式来修改这段代码, 只是我觉得用 OOP 的方式非常适合)
在井字棋这个情况下, 需要保持的信息/状态有: 棋盘信息, 当前控制者.
(defclass tictactoe ()
(;; 棋子的信息 (初始为空)
(chessboard :initform (make-array 9 :initial-element :empty))
;; 当前的控制者 (初始为 `:red' 红方)
(player :initform :red :reader player)
;; 游戏状态
(status :initform :play :reader status))
(:documentation "井字棋核心逻辑. "))
假如你不了解 Common Lisp
你可以参考一下我的 计算物理 (的附录) 了解一些简单的 Common Lisp 语法.
在这里, 使用了 (defclass direct-superclass direct-slots &rest options)
这个声明类的宏:
- 我们定义了一个叫作
tictactoe的类, 当我们要新建一个这个类的实例的时候, 我们只需要(make-instance 'tictactoe)即可. - 在这里
tictactoe类没有直接的父类, 我们可以认为是最根本的类, 接下来的各种操作相关的类都是其的子类 - 其中
chessboard,player,status为类的实例的变量, 每个实例都有相同名字的实例变量, 但是这些实例变量对应的值随着不同的实例而变化. - 在声明实例变量的时候
:initform表示初始缺省值;:reader会构造一个读值函数, 于是你可以通过(player tictactoe)来读取(slot-value tictactoe 'player).
等等, 假如上面的词汇对你来说有点陌生, 你可能需要了解一点 OOP
很遗憾, 我没法给出一个让我接受的描述… 毕竟我也没有对象.
还请自行查找关键词 “面向对象编程”. 这里是一个简单的说明, 以及对于 Common Lisp 的 OOP 的一个小小补充:
子类可以继承父类的方法, 也可以覆写父类的方法. 很常见吧. 比如鸟类都会飞, 鸡是鸟的子类, 所以鸡也有飞这个方法.
但是如果子类的方法是父类方法的修改呢? 比如对于鸡来说, 飞需要在父类飞的方法的基础上先起跳:
# Ruby Code Example
class Chicken < Bird
def fly
jump
super
end
end
在 Common Lisp (CLOS) 中, 你可以使用 :before 修饰词:
(defmethod fly ((obj bird))
(let-the-brid-fly-code obj))
(defmethod fly :before ((obj chicken))
(jump obj))
你可以将其理解为一种方法的组合. 类似的, 还有 :after,
:around 这样的修饰词来提供不同方式的组合方法.
比如 Python 中的 decorator:
def wrap_in_tag(fn):
print("<div>")
fn()
print("</div>")
@wrap_in_tag
def para(text):
print(text)
就可以用 CLOS 中的 :around 来实现:
(defmethod para (text stream)
(print text))
(defmethod para :around (text stream)
(declare (ignore text))
(print "<div>" stream)
(call-next-method)
(print "</div>" stream))
当然, 我更加喜欢的用法是这样的:
(defmethod para :around ((text upper-style) stream)
(call-next-method (string-upcase text) stream))
相当于对参数进行一个 wrap.
对于一个井字棋游戏, 最核心的基本操作应当为:
- 落子
drop-chess:具体的实现
(defmethod drop-chess ((game tictactoe) chess-id) (with-slots (chessboard player) game (when (eq (aref chessboard chess-id) :empty) ; `chess-id' 处为空 (setf (aref chessboard chess-id) player)))) ; 在 `chess-id' 处落子
- 交换控制方
swap-player:具体的实现
(defmethod swap-player ((game tictactoe)) (with-slots (player) game ;; 若当前为 `:red' 则交换为 `:blue' 反之亦然 (setf player (if (eq player :red) :blue :red))))
- 更新棋局状态
update-status:具体的实现
(defun %chessboard-status (chessboard) "根据 `chessboard' 得到可能的状态. " ;; `flet' 类似 `let', 前者绑定局部函数, 后者绑定局部变量 (flet ((line? (i j k) ;; 判断坐标上的点的 grid 是否相同, 若相同, 返回相同的值 (let ((value (reduce (lambda (a b) (if (eq a b) a nil)) (mapcar (lambda (idx) (aref chessboard idx)) (list i j k))))) (and (not (eq value :empty)) value)))) (let ((full? (= 9 ;; 对非空 grid 计数并求和, 判断是否和为 9 (全填满) (reduce #'+ (map 'list (lambda (grid) (if (eq grid :empty) 0 1)) chessboard)))) (line? (or ;; 横向相连 (line? 0 1 2) (line? 3 4 5) (line? 6 7 8) ;; 纵向相连 (line? 0 3 6) (line? 1 4 7) (line? 2 5 8) ;; 对角线相连 (line? 0 4 8) (line? 2 4 6)))) ;; 根据 `chessboard' 返回状态 (cond ((eq line? :red) :red-win) ((eq line? :blue) :blue-win) (full? :full) (t :play))))) (defmethod update-status ((game tictactoe)) (with-slots (chessboard status) game (setf status (%chessboard-status chessboard))))
- 清空棋盘
clear-board:具体的实现
(defmethod clear-board ((game tictactoe)) (with-slots (chessboard player status) game (loop for i below 9 do (setf (aref chessboard i) :empty)) ; 清空为 `:empty' (setf player (case status ; 交换控制方, 输者先攻 (:red-win :blue) (:blue-win :red) (otherwise player))) (setf status :play))) ; 重置 `status'
如上所示, 基本的基础操作已经完成了, 那么每次下子只需要:
(drop-chess game id)
(update-status game)
(swap-player game)
是不是有点太麻烦了?
所以通过 CLOS 的 :after, :around 的机制, 可以将这些方法组合在一起:
(defmethod drop-chess :around ((game tictactoe) chess-id)
(with-slots (status) game
(when (and (eq status :play) ; 状态为 :play 时才可落子
(call-next-method)) ; 可以落子 (落子结果非 nil)
(update-status game) ; 更新棋局状态
(swap-player game)))) ; 交换控制方
以文本的形式输出游戏状态 (假如你不想使用 cl-webview 来交互的话)
(defmethod print-object :after ((game tictactoe) stream)
(with-slots (chessboard player status) game
(format stream "~& PLAYER: ~A, STATUS: ~A" player status)
(loop for row below 3
do (format stream "~&| ")
do (loop for col below 3
do (format stream "~A | "
(case (aref chessboard (+ (* row 3) col))
(:empty " ")
(:red "X")
(:blue "O")))))))
效果如下:
(let ((game (make-instance 'tictactoe)))
(dotimes (i 50)
(drop-chess game (random 9)))
(print game))
#<TICTACTOE {70091FADE3}>
PLAYER: BLUE, STATUS: RED-WIN
| X | O | |
| X | O | |
| X | X | O |
cl-webview 的绘制以及事件的交互
(注: 这里先不管美观与否, 总之就是上了再说)
使用 cl-webview 绘制界面的操作和 HTML+CSS+JS 的那一套流程是完全相同的, (可以参考: How to Make a Website). 这里通过 mixin 的方式添加 webview 相关的功能:
(defclass webview-mixin ()
(;; 棋盘的尺寸
(size :initform 400
:initarg :size
:reader size)
;; 控制组件的高度
(control-height :initform 100
:initarg :control-height
:reader control-height)
;; webview 窗体
webview)
(:documentation "绘制到 webview 窗体上的相关模块. "))
在 webview-mixin 中, 主要的工作有两个: 绘制, 以及绑定交互的事件.
对于绘制, 这里将输出的 HTML 分为两个部分, 一个是 size * size 的棋盘,
另一个这是控制的按钮组件:
- 绘制棋盘
dump-chessboard:具体实现
(defconstant +table-control-string+ "<td style='width: ~dpx; height: ~dpx' id='~A' onclick='drop_chess(~d)'></td>" "用于输出 td. ") (defmethod dump-chessboard ((win webview-mixin) stream) (let* ((gridsize (floor (/ (size win) 3)))) (format stream "<table border='1'>") (loop for row below 3 do (format stream "<tr>") do (loop for col below 3 for chess-id = (+ (* row 3) col) do (format stream +table-control-string+ gridsize gridsize chess-id chess-id)) do (format stream "</tr>")) (format stream "</table>")))
- 绘制控制组件
dump-controls:具体实现
(defmethod dump-controls :around ((win webview-mixin) stream) (format stream "<div>") (call-next-method) (format stream "</div>")) (defmethod dump-controls ((win webview-mixin) stream) (format stream "<button onclick='clear_board()'>Clear Board</button>"))
- 最后得到 HTML 的输出
(defun html (tictactoe) "返回一个绘制井字棋 `tictactoe' 的 HTML. " (with-output-to-string (stream) (format stream "<body>") (dump-chessboard tictactoe stream) (dump-controls tictactoe stream) (format stream "</body>"))) (defmethod initialize-instance :after ((game webview-mixin) &key debug) (with-slots (size control-height webview) game ;; 初始化时绑定窗体大小以及 HTML (setf webview (make-webview :debug debug :width size :height (+ size control-height) :title "TicTacToe" :hints :fixed :html (html game))) ;; 绑定交互的事件的逻辑 (webview-bind (webview chess-id) "drop_chess" (drop-chess game chess-id)) (webview-bind (webview) "clear_board" (clear-board game))))
- 并且还要注意到, 当
drop-chess,clear-board这些tictactoe类的方法执行后, 对应的窗体也需要进行更新:drop-chess后, 将对应落子区域的格子的颜色进行更新:(defconstant +drop-control-string+ "document.getElementById('~d').style.background = '~(~A~)';" "落子的 JS 控制代码. ") ;; 在落子后将对应格子的颜色更新 (defmethod drop-chess :after ((game webview-mixin) chess-id) (with-slots (webview chessboard) game (let ((grid (aref chessboard chess-id))) (webview-eval webview (format nil +drop-control-string+ chess-id (case grid (:red "red") (:blue "blue")))))))
clear-board前, 将棋盘中的所有棋子都清空颜色:(defconstant +title-format-control+ "TicTacToe (~A)" "显示窗口的 title 的格式. ") (defmethod clear-board :before ((game webview-mixin)) (with-slots (webview player) game (dotimes (i 9) (webview-eval webview (format nil +drop-control-string+ i "white")) (webview-set-title webview (format nil +title-format-control+ player)))))
update-status后, 如果游戏结束, 则将title设置为显示棋局状态:(defmethod update-status :after ((game webview-mixin)) (with-slots (status webview) game (unless (eq status :play) (webview-set-title webview (format nil +title-format-control+ status)))))
swap-player后, 如果游戏仍在进行, 则将title设置为当前玩家:(defmethod swap-player :after ((game webview-mixin)) (with-slots (status player webview) game (when (eq status :play) (webview-set-title webview (format nil +title-format-control+ player)))))
于是就完成了一个井字棋游戏的类:
(defclass tictactoe-webview (tictactoe webview-mixin) ()
(:documentation "井字棋游戏"))
一个简单的测试 (代码)
(let ((game (make-instance 'tictactoe-webview)))
(def-dispatch-callback random-drop (webview)
(unless (eq (status game) :play)
(clear-board game))
(drop-chess game (random 9)))
(dotimes (i 100)
(webview-dispatch-fn (slot-value game 'webview) 'random-drop)
(sleep 0.05)))
(效果确实有点子丑了… )
AI?
终于到了比较有意思的地方了:
(defclass ai-player-mixin ()
((ai-player :initform :blue :initarg :ai))
(:documentation "AI mixin for tictactoe class. "))
这里考虑的是一个没有历史发展记忆, 仅考虑当前棋局进行决策的 AI. 在每次交换落子控制方的时候, 就会进行思考并落子.
(defgeneric ai-choose-drop (tictactoe)
(:documentation "返回 AI 决定的落子位置. "))
(defmethod swap-player :after ((game ai-player-mixin))
(with-slots (player ai-player status) game
(when (and (eq player ai-player) ; 轮到 AI
(eq status :play)) ; 游戏还能继续玩
(let ((drop (ai-choose-drop game)))
(drop-chess game drop)))))
(defmethod clear-board :after ((game ai-player-mixin))
(with-slots (player ai-player status) game
(when (and (eq player ai-player) ; 轮到 AI
(eq status :play)) ; 游戏还能继续玩
(let ((drop (ai-choose-drop game)))
(drop-chess game drop)))))
等等, defgeneric 是什么? 为什么不用 defmethod?
在前面的代码里面, 我有意忽略了 defgeneric 的使用, 而只使用 defmethod.
尽管实际上并不会有什么问题.
Montain Gorilla Algorithm
这是一个著名的算法, 中文直译是山地黑猩猩算法. 令人惊讶的是, 尽管这个算法名字听上去非常的好笑, 但是它确实非常好笑, 因为是我瞎编的.
什么 AI 不 AI 的, 随机就完事了:
(defclass montain-gorilla-mixin (ai-player-mixin) ()
(:documentation "随机落子的 AI. "))
(defclass tictactoe-gorilla (tictactoe-webview montain-gorilla-mixin) ())
(defmethod ai-choose-drop ((game montain-gorilla-mixin))
(with-slots (chessboard) game
(let ((remain (loop for i below 9
if (eq (aref chessboard i) :empty)
collect i)))
;; 在剩余的空格子中随便挑出一个落子
(nth (random (length remain)) remain))))
Minimax Algorithm
那么说正经的, 如何实现一个有用一点的 AI 呢? 一个方法就是使用 Minimax 算法:
(以下来源于 Algorithm in Nutshell Figure 7-15, 简单的来说, Minimax 算法就是一种最大深度有限的深度优先搜索算法, 搜索的目标是使得己方分数最大, 敌方分数最小. 所以其实需要配合打分表, 或者说打分规则进行使用. )
解说略, 直接是代码, 因为我累了. 重点还是放在后面那个东西上吧.
(defun %empty-grids (chessboard)
"找到 `chessboard' 中所有空格子. "
(loop for i below 9 if (eq (aref chessboard i) :empty) collect i))
(defun %get-score (status ai-player)
"对当前棋局进行打分. "
(cond ((or (and (eq ai-player :red)
(eq status :red-win))
(and (eq ai-player :blue)
(eq status :blue-win)))
1) ; 若 AI 获胜, score = 1
((or (and (eq ai-player :red)
(eq status :blue-win))
(and (eq ai-player :blue)
(eq status :red-win)))
-1) ; 若非 AI 获胜, score = -1
(t ; 平局, score = 0
0)))
(defun %minimax (chessboard player ai-player &optional (depth 3))
"返回一个最适合的落点点位, 以及其对应的打分.
Return (values score choose). "
(let ((status (%chessboard-status chessboard)))
(if (or (zerop depth)
(not (eq status :play)))
(%get-score status ai-player)
(let ((best (if (eq player ai-player)
most-negative-fixnum ; 最大化边界
most-positive-fixnum)) ; 最小化边界
(choose -1) ; 选择的点位
score)
(dolist (next (%empty-grids chessboard))
(let ((chessboard (alexandria:copy-array chessboard)))
(setf (aref chessboard next) player) ; 落子
(setf score (%minimax chessboard ; 计算落子后 `chessboard' 对应的分数
(if (eq player :red) :blue :red)
ai-player (1- depth))))
(cond ((and (eq player ai-player)
(> score best)) ; 最大化己方得分
(setf best score
choose next))
((and (not (eq player ai-player))
(< score best)) ; 最小化敌方得分
(setf best score
choose next))))
(values best choose)))))
(defclass minimax-mixin (ai-player-mixin) ()
(:documentation "Minimax AI"))
(defmethod ai-choose-drop ((game ai-player-mixin))
(with-slots (chessboard player ai-player) game
(multiple-value-bind (score choose)
(%minimax chessboard player ai-player 4)
(declare (ignore score))
choose)))
(defclass tictactoe-minimax (tictactoe-webview minimax-mixin) ())
(注: 感觉有点子弱? 可能是打分算法不够好. )
下面有请山地黑猩猩与 Minimax 选手进行一场友好的较量…
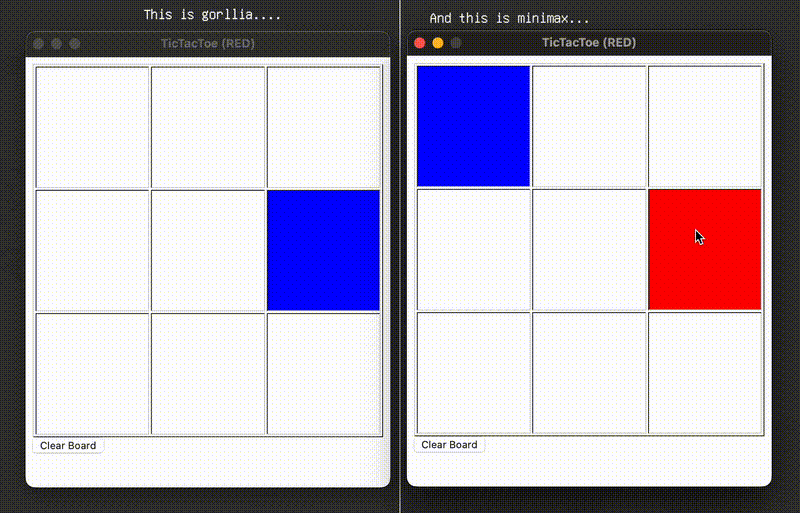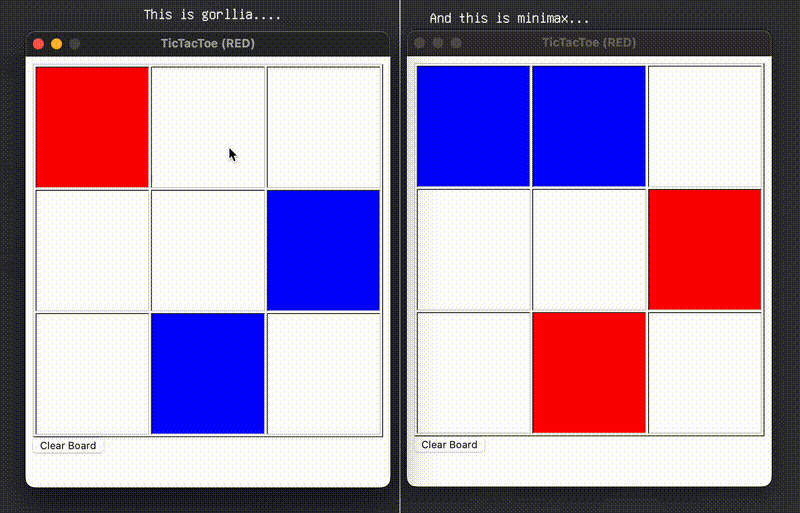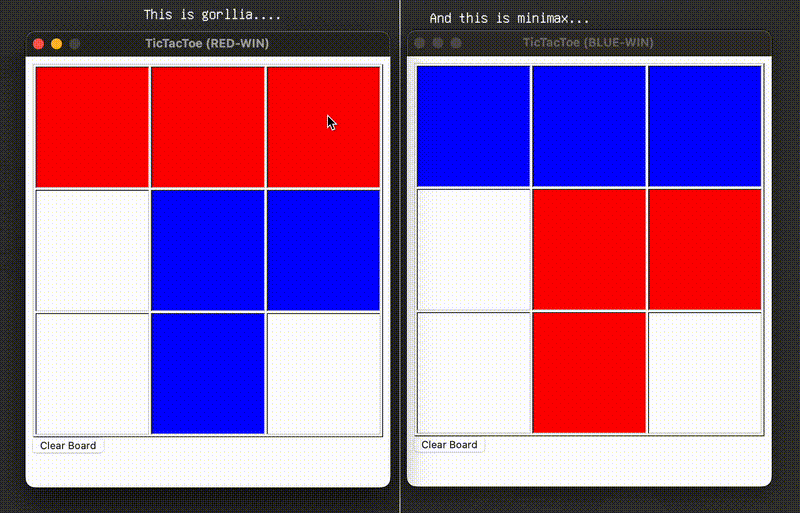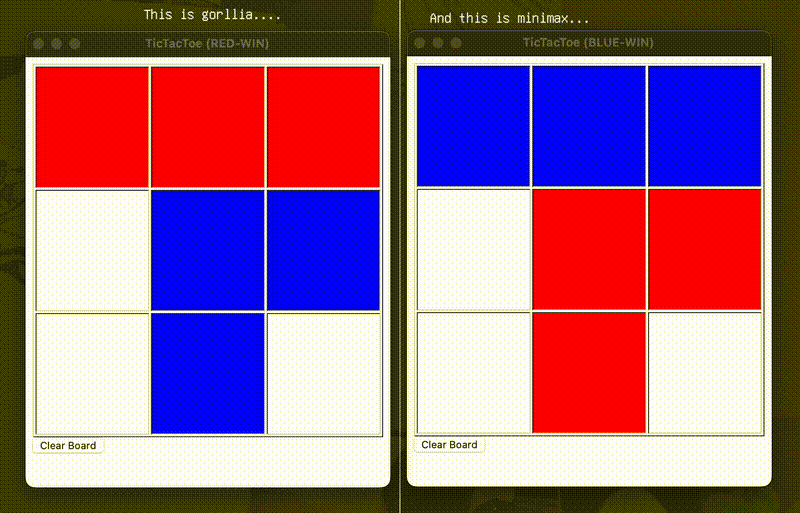
真是场酣畅淋漓的鏖战啊… (狗头)
Neural Network
其实如果你仔细看上面的打分算法 (%get-score), 就会发现这个打分算法是非常朴素的,
并且如果你再仔细观察 Minimax 的方法, 就会发现, 其实 Minimax 是对所有可能的落点
都进行了一个通过深度优先搜索的一个打分过程.
说白了, 所有的过程都是在对棋局进行一个打分. 并选择分高的下.
如果是同分呢?
理论上对于同分的情况, 应该是随机进行选择的 (山地黑猩猩算法). 但是我上面的代码没有写就是了. 因为懒.
对于上面的 Minimax 算法, 一个比较抽象的描述就是构造了一个打分函数 \(f(\mathrm{chessboard}, i), i = 0, 1, \cdots, 8\), 使得其的值为在格点 \(i\) 上下子的分数 (概率). 而每次选择落点时通过比较概率 (分数) 对落点位置进行选择.
那么机器学习不就很适合干这种工作吗? (也就是找出原函数 \(f(\mathrm{chessboard}, i)\))
(以下参考: AI Trainable Tic Tac Toe, 因为这也差不多是我第一次写机器学习的代码, 所以不能保证代码的正确性. )
于是构造一个 9-64-64-9 的三层的神经网络, 其中两个隐藏层使用 ReLU 作为激活函数,
输出层使用 Softmax 为激活函数. (参考原仓库 constructModel 的代码).
于是思路如下:
- 在每一局比赛结束的时候进行学习.
- 去学习胜利的一方的下棋方法, (当平局时, 随机挑选一方进行学习), 于是就要要求对下棋过程有一个历史记录.
历史记录
简单来说就是通过栈的 push 和 pop 实现一个简单的历史记录功能.
略, 其实是为了添加一个历史记录功能
(defclass history-mixin ()
((history :initform ()))
(:documentation "历史记录"))
;; 往历史记录中添加记录: (落点 . 玩家)
(defmethod drop-chess :before ((game history-mixin) chess-id)
(with-slots (history) game
(push chess-id history)))
(defmethod undrop-chess ((game history-mixin) chess-id)
(with-slots (chessboard) game
(setf (aref chessboard chess-id) :empty)))
(defmethod undrop-chess :before ((game webview-mixin) chess-id)
(with-slots (webview) game
(webview-eval webview (format nil +drop-control-string+ chess-id "white"))))
;; 悔棋
(defmethod undo ((game history-mixin))
(with-slots (history) game
(when history ;; 有历史记录可以回退
;; 清空历史记录中的格点
(undrop-chess game (pop history))
;; 交换控制方
(swap-player game))))
(defclass tictactoe-undo (tictactoe history-mixin webview-mixin) ())
(defmethod dump-controls ((game tictactoe-undo) stream)
(declare (ignore game))
(format stream "<button onclick='clear_board()'>Clear Board</button>")
(format stream "<button onclick='undo()'>Undo</button>"))
(defmethod initialize-instance :after ((game tictactoe-undo) &key)
(with-slots (webview) game
(webview-bind (webview) "undo"
(undo game))))
神经网络的实现
在这里我们会手写一个神经网络.
那么为什么不调库呢?
对啊, 为什么呢?
cl-waffe2 是一个日本高中生写的 (只能说日本高中生拯救世界并不是动漫里才有的), 并且最牛皮的是老哥甚至都已经发了论文, 参加过不少会议了…
诶, 人和人之间的差异啊…
不过我没怎么用过, 并且对一般的神经网络也不是很熟悉, 所以这里还是手搓一个, 了解一下大概的思路吧…
而关于线性代数, 你可以使用 magicl 或者 lla 来进行实现. 不过这里我觉得并不必要, (主要是我线性代数部分忘得差不多了, 所以我会用我自己的 ryo 的库来写.)
为了和 Common Lisp 的默认方法进行区分, 我这里用 ryo:at 这样的形式来调用我的方法.
这里不得不提一下关于 Common Lisp 中类似于 C++ 或者 Ruby 中的 Namespace 的东西了. 在我们定义一个 package 的时候, 实际上我们定义了一个 Namespace.
(defpackage #:foo
(:use :cl)
(:export #:bar))
(in-package :foo)
然后在 foo 这个包中定义的各种方法, 都可以被 export 出来在其他的包中引用,
如: (foo:bar ...). 当然, 你也可以不 export 直接使用 (foo::bar ...)
的方式调用内部的名字.
这里会有一个需要注意的点: 为什么用 #:foo 和 #:bar? 这是为了防止和已有的名字发生冲突.
整体的思路如下:
- 把棋盘
chessboard看作是一个{-1, 0, 1}的 9 维矢量的输入 - 激活函数:
- sigmoid
(defun square (x) (* x x)) (defun sigmoid (x) (let ((expx (exp x))) (/ expx (1+ expx)))) (defun d-sigmoid (x) (let ((expx (exp x))) (/ expx (square (1+ expx)))))
- ReLU
(defun relu (x) (if (> x 0) x 0)) (defun d-relu (x) (if (> x 0) 1 0))
- sigmoid
- 定义一个
layer类型用做单层:(defclass layer () ((weights :accessor weights) (%out :accessor %out) ; 当前计算未过激活函数的输出 (%in :accessor %in) ; 当前计算的输入 (%rms :accessor %rms) ; 当前计算的误差 (inputs :initform 10 :initarg :inputs :reader inputs) (outputs :initform 64 :initarg :outputs :reader outputs) (active :initform #'sigmoid :initarg :active :reader active) (d-active :initform #'d-sigmoid :initarg :d-active :reader d-active) (learning-rate :initform 1e-3 :initarg :learning-rate :accessor learning-rate)) (:documentation "一层神经元"))
初始化时给 weights 设置初始的噪声
;; 初始噪声的强度通过 `:noise' 来进行控制 (defmethod initialize-instance :after ((layer layer) &key (noise 0.1d0)) (with-slots (weights inputs outputs) layer (setf weights (make-array (list (outputs layer) (inputs layer)) :initial-contents (ryo:collect-i* ((i (inputs layer)) (j (outputs layer))) (random noise))))))
其需要有如下的方法:
(defgeneric feedforward (layer input) (:documentation "计算前向传播")) (defgeneric feedbackward (layer err) (:documentation "反向传播误差并更新权重"))
feedforward的实现:\[\mathrm{out}_j = w_{ij} \mathrm{in}_i\]
(defmethod feedforward ((layer layer) input) (with-slots (%in %out outputs inputs weights active) layer (setf %in input) (setf %out (make-array outputs :initial-contents (ryo:collect-i* ((j outputs)) (ryo:sum-iter-i* ((i inputs)) (* (aref weights j i) (aref input i)))))) (map 'vector active %out)))
feedbackward通过反传 (backpropagation) 来实现: (参考 MLP | Wikipedia)一些简单的向量函数
(declaim (inline dot vec-sub num-mul)) (defun dot (vec1 vec2) (map 'vector #'* vec1 vec2)) (defun cross (vec1 vec2 &optional (scale 1d0)) (let ((n (length vec1)) (m (length vec2))) (make-array (list m n) :initial-contents (ryo:collect-i* ((i (length vec1)) (j (length vec2))) (* scale (aref vec1 i) (aref vec2 j)))))) (defun num-mul (num vec) (map 'vector (lambda (vi) (* vi num)) vec)) (defun vec-sub (vec1 vec2) (map 'vector #'- vec1 vec2))
向前一层传的误差:
\[ε_i' = w_{ij} ε_j\]
其中 \(ε_j\) 为当前层的误差.
\[Δ w_{ij} = - η \frac{∂ ε}{∂ v_j} y_i\]
其中 \(η\) 为学习率;
\[- \frac{∂ ε}{∂ v_j} = e_j φ'(v_j)\]
其中 \(e_j\) 为误差, \(φ'\) 为激活函数的导数;
;; 返回传递给上一级的误差 (defmethod feedbackward ((layer layer) err) (with-slots (inputs outputs weights) layer (make-array (list inputs) :initial-contents (ryo:collect-i* ((i inputs)) (ryo:sum-iter-i* ((j outputs)) (* (ryo:at weights i j) (ryo:at err j))))))) ;; 更新当前权值 (defmethod feedbackward :after ((layer layer) err) (with-slots (inputs outputs d-active %in %out weights learning-rate) layer (let* ((dedv (dot err (map 'vector d-active %out)))) ;; weights_ij = learning_rate * dedv_j * y_i (ryo:iter-i* ((i inputs) (j outputs)) (incf (ryo:at weights i j) (* learning-rate (ryo:at dedv j) (ryo:at %in i)))))))
train训练:(defun %train (layer input output) (let ((err (vec-sub output (feedforward layer input)))) (feedbackward layer err) (format t "~&ERROR: ~f" (reduce #'+ (map 'list #'square err))) (force-output))) (defun train (layer input-output* &key (learning-rate (learning-rate layer)) (repeat 1)) (setf (learning-rate layer) learning-rate) (dotimes (i repeat) (dolist (samples input-output*) (%train layer (car samples) (cdr samples)))))
一些注记
我比较怀疑这个东西是否真的靠谱. 不过没有一个很好的检验方法, 并且关键是它能动…- 将层与层之间连接起来形成网络
(defclass network () ((layers :accessor layers))) (defmethod (setf learning-rate) (lr (net network)) (with-slots (layers) net (loop for i below (length layers) for layer = (aref layers i) do (setf (learning-rate layer) lr)))) (defmethod feedforward ((net network) input) (with-slots (layers) net (loop for i below (length layers) for layer = (aref layers i) for output = (feedforward layer input) then (feedforward layer output) finally (return output)))) (defmethod feedbackward ((net network) err) (with-slots (layers) net (loop for i from (1- (length layers)) downto 0 for layer = (aref layers i) for back-err = (feedbackward layer err) then (feedbackward layer back-err) finally (return back-err))))
于是井字棋的 AI 如下:
首先构造一个网络:
(defun make-tictactoe-mlp ()
(let ((input-layer (make-instance 'layer :inputs 10
:outputs 64
:active #'relu
:d-active #'d-relu))
(hidden-layer (make-instance 'layer :inputs 64
:outputs 64
:active #'relu
:d-active #'d-relu))
(output-layer (make-instance 'layer :inputs 64
:outputs 9
:active #'sigmoid
:d-active #'d-sigmoid))
(net (make-instance 'network)))
(setf (layers net)
(make-array 3 :initial-contents (list input-layer
hidden-layer
output-layer)))
(setf (learning-rate net) 0.01) ; 学习率高一点...
net))
应该有更好的构造方法, 这里应该可以自己做一套 DSL 的, 不过略去, 因为我有点不太想写这个了…
(defclass mlp-mixin (ai-player-mixin history-mixin)
((model :initform (make-tictactoe-mlp) :reader model)))
(defun %mlp-input (chessboard)
"将 `chessboard' 变换为标准的 MLP 模型的输入"
(flet ((val (g)
(case g
(:red 1)
(:empty 0)
(:blue -1))))
(make-array 10 :initial-contents (cons 1d0 (map 'list #'val chessboard)))))
(defmethod ai-choose-drop ((game mlp-mixin))
(with-slots (model chessboard history) game
(let* ((output (feedforward model (%mlp-input chessboard)))
(p-patterns (reduce (lambda (p-patterns i)
(cond ((> (aref output i) (car p-patterns))
(list (aref output i) i))
((= (aref output i) (car p-patterns))
(push i (cdr p-patterns)))
(t p-patterns)))
(%empty-grids chessboard)
:initial-value '(-1 0))))
(nth (random (length (cdr p-patterns))) (cdr p-patterns)))))
(defclass tictactoe-mlp (tictactoe-webview mlp-mixin) ())
;; 从历史记录中学习胜者落子
(defmethod learn-from-history ((game mlp-mixin) learn-player)
(with-slots (model chessboard history) game
(flet ((get-output ()
(make-array 9 :initial-contents
(ryo:collect-i* ((i 9))
(if (eq (car history) i) 1 0)))))
(when (eq (player game) learn-player) ; 当前玩家为需要学习的玩家
(%train model (%mlp-input chessboard) (get-output)))
(when (undo game) ; 如果还有可学习的历史
(learn-from-history game learn-player)))))
(defmethod clear-board :before ((game mlp-mixin))
(with-slots (status ai-player) game
(case status
(:red-win (learn-from-history game :red))
(:blue-win (learn-from-history game :blue))
(:full (learn-from-history game (if (eq ai-player :red)
:blue :red))))))
还行, 玩了几把发现误差掉不下去, 不是很清楚哪里出了问题. 先就这样先吧… 有点厌烦这个过程了. 接下去会找一些比较严谨的模型, 并且重新写这些比较底层的代码的.
Common Lisp Modules
这里是我之前阅读 The Substrates of Intelligence, a Neural Network Primer | Common Lisp Modules: Artificial Intelligence in the Era of Neural Network and Chaos Theory 第二章做的笔记 (但是没读完):折叠
About
导出了之后感觉前一个标题好像有点太长了… 但是就这样吧, 毕竟最近的轻小说的标题也挺长的.
尽管貌似都会有一种说法, 认为 LISP 系的都是那种符号计算的专家系统, 都是那种: “开除几个专家, 性能就可以提升几倍的” 东西. 但是其实不是哦, 虽然我也挺好奇这玩意到底实现的是怎么样的神经网络.
(虽然我觉得这不太可能真的和现在的神经网络能够相提并论, 但是至少可以先看看, 作为一个历史读物估计也不错.)
(注: 在我读了部分的代码之后, 给我的感觉就是挺失望的, 里面覆盖的内容可能比较丰富, 但是现在看来也有点少, 并且总觉得里面的一些代码并不是很通用, 想要写一些能够具有迁移能力的代码的话, 还是有点困难的. 所以假如你是想要去了解如何写机器学习用的代码的话, 可以跳过这篇文章去看其他更加靠谱的文章. 这篇文章的作用更多是没用的历史介绍, 以及一个简单的实现. )
Background
这里有一些比较有意思的话, 为了防止我理解错了, 这里用原文截取一下:
Neural networks are systems of very simple processing elements that are massively interconnected. Long term memory or information content in neural networks is typically stored in the state of the interconnections, not the processing elements themselves.
这里的 “Long term memory” (长期记忆) 和 RNN 中的 LSTM (Long Short-Term Memory), 应该是 不一样 的… 啊, 十分抱歉. 看了定义之后才发现了不一样的问题了.
这里还有一个来自过去对未来的想象, 也是非常的有意思:
Neural systems exploit the inherent parallelism in many pattern-maching and recognition tasks. In the future they will be used to augment conventional computers, greatly speeding up pattern matching and cognitive tasks.
确实, 对于模式匹配 (pattern matching) 的问题上来说, 神经网络 (不过感觉此神经网络, 和现在说的应该不太一样… ) 确实比规则匹配上来说会方便很多.
在认知 (cognitive) 上的话, 我对这个不了解, 毕竟在实验物理里面, 对数据的模式匹配, 估计会比较有用.
这里有一个比较有意思的地方:
Neural systems are very fault tolerant; they can be partially destroyed and still function with some degradation of performance. This fault tolerence will someday make it possible to construct neural computers with millions of neurons with tens of millions of interconnections using three-dimensional integrated circuits.
看到这里大概就能够发现原文说的 Nerual system 是什么了: 感觉有一种 HAL 的感觉, 可以一块块拔掉核心板的感觉 (bushi).
不过这里应该是指旧的 Connection Machine.
这里有一个比较有意思的介绍: Connection Machine CM-1(1986) & CM-2 (1987) (Youtube). 给我的感觉大概就是 Connection Machine 有点像是现代的超算 + GPU + FPGA, 大概就是一个有超级多核 (每个核还可以去模拟非常多小核) 的计算机, 然后核与核之间的结果是可以被重新编程来处理的. 这里用现代的眼光来看, 这样的设计确实有很多的不足 (或者说, 也不是不能用别的方式来实现, 比如 CPU + GPU 相当于让 GPU 做了每个核的计算, CPU 在做搬运的工作?):
Connecting a separate communication wire between each pair of processors was impractical since a million processors would require $10^{12]$ wires.
从上面的参考资料里面可以看到一个非常恐怖的人力活, 哪怕是后来用 router (我猜应该是一个类似于网络通信一样的东西) 来减少连线数量, 仍然还是需要非常多的接线操作等等. 大概里面的瓶颈可能是核与核之间大数据量的传输, 不过感觉之后可以用 MPI 来试试看.
大概这就是为什么一开始, 或者到了现在人们回过头去看这个的操作会觉得以前的 Connection Machine 这么不好的原因吧.
一些抱不平
在教材里面的 Connection Machine 可没有那么好看… 大概就是一张黑白照片, 然后一个研究人员 (大佬) 坐在一堆密密麻麻的线缆面前在接线. 啊, 虽然也很酷就是了, 但是如果大家看过 Connection Machine 的照骗的话:

(图片来源: The Connection Machines CM-1 and CM-2 | Tamiko Thiel)
是不是有一种 Magi 的感觉… 真帅啊.
虽然在 Connection Machine 上编程应该是一个非常痛苦的事情.
Very well written thesis. The machine, however, was extraordinarily difficult to program, resulting in Thinking Machine's quick death once they actually tried to compete commercially with Convex and Cray.
from Hacker News
但是我觉得这里的概念应当被借鉴和学习, (虽然前沿的计算我并不清楚用的是啥方法, 但是对于里面提到的这个 Cellular Automa 和物理之间的联系我还是比较好奇的).
嗯, 有时间有点想要翻译一下这篇文章.
Neural networks can be best used as components of large systems to handle pattern matching tasks. It is important to avoid the use of neural network technology in cases like algorythmic processing where conventional software solutions are easier to implement and offer better performance.
所以我觉得 Stephen Wolfram 的这种想法更应该被参考: Wolfram|Alpha as the Way to Bring Computational Knowledge Superpowers to ChatGPT.
虽然我不懂人工智能, 也不懂啥世界模型, 但是我认为, 现在期望 LLM 能够产生所谓的世界模型, 感觉可能有点难? 不过按照 AI 那么卷的现状, 估计也快了吧. 在神经网络上引入专家系统, 或者说在专家系统上加入神经网络作为外壳交互, 不知道会不会加速这个 “世界模型” 的得到, 假设专家系统就是一个小世界模型的话 (显然不是), 能否就这样通过自举来实现模型的生长呢? 嘛, 至少我觉得难说, 毕竟现在还了解专家系统的大佬应该不多了, LLM 这种应该是更可行的道路.
Model for Supervised Learning
啊, 这部分我觉得学过/旁听过模式识别的应该或多或少都认识一些? 总之就是非常的眼熟.
package definition and others
(defpackage #:cl-module/neural
(:use :cl :gurafu)
(:nicknames :neural)
(:import-from
:magicl
:from-list :from-array :reshape
:map! :norm :rand :zeros
:@ :dot
:.* :.+ :.- :./ :.^))
(in-package :cl-module/neural)
啊, 本来打算做一个绘图库的, 但是最后实在是太痛苦了, 各种绘图参数什么的, 实际上还是做了一个绘图库…
关于绘图库 GURAFU 的一个题外话
害, 真是不知道该不该佩服我自己的坚持呢… 故事的开始是要给 cl-corsika 做一个可视化的程序, 以及数据分析拟合的东西.
不是说学一个东西, 最简单的方式就是自己上手试试看吗? 于是我决定从 Common Lisp Modules 这本书里面的 Neural Network 开始, 然后, 嗯, 嗯…
我看到了一个 Sigmoid Activation Function 的函数图… 然后就想, 啊, 要是我自己可以把这个图画出来的话, 就好了, 于是我就开始了写 GURAFU 这个画图程序…
于是就拖到了现在… 啊, 这个函数调用栈的调用和回溯的事件有点长呢… 啊, 哈, 哈…
不过感谢我的友人提供了一个非常好的狡辩借口, 下面允许我进行原文引用:
你就说你卡了
但是你收货了很多
嗯, 虽然确实收获了很多… 至少我现在有自信说如果真的要让我从零开始, 比如说在只有语言的基础上 (或者只有汇编? ), 并且没有 性能考虑 的情况下, 来实现到目前为止的所有东西… 应该, 也, 肯定会是个坑爹的不可能的事情…
我还是太菜了啊… orz
虽然我对这个绘图库还算是有点自信… 但是这个绘图库怎么说都还算是 WIP (work in progress… ), 所以我在写这个的过程中, 也会往 GURAFU 里面添加需要的函数和功能的… 所以可能未来你会发现现在这个代码是不能用的,
Good Luck.
不过线性代数部分还是使用了 magicl, 但是也不是不能自己写, 虽然感觉可能会很慢, 比如一个简单的矩阵乘法的例子:
(declaim (inline matrix-product))
(defun matrix-product (matrix vec
&key (type 'vector) (product #'*) (sum #'+))
"Product list `matrix' with list `vec'. "
(map type (lambda (row) (reduce sum (map 'list product row vec))) matrix))
这里本来应该用一些更加靠谱的矩阵库来做这个事情的…
你可以参考:
但是不知道为什么在我的电脑 (macbook air m1) 上有些问题… 虽然可以通过换电脑的方式来解决这个问题, (猜测是缺少对 arm 的支持? 因为另外一台是 x86), 可以看 #203 Issue, 目前的解决方法就是使用逃避法…
不过一个更加让人破防的事情是我在 Github 闲逛的时候, 看到了一个 cl-waffle2, 是一个日本高中生做的 Deeplearning 的库. 这位大佬还写了一个 cl-metal 的库给苹果的 metal 做绑定…
真是让人汗流浃背, 果然日本高中生真的像漫画里面一样无所不能啊…
不过鉴于目前的问题规模还不是很大, 估计可以先用朴素的 list matrix 来普通的计算:
- 算一个转动:
(flet ((z-rot-mat (theta) (let ((cos (cos theta)) (sin (sin theta))) (list (list cos sin) (list (- sin) cos)))) (rand-norm () (let ((a (random 1.0)) (b (random 1.0))) (list (* (sqrt (* -2 (log a))) (cos (* 2 pi b))) (* (sqrt (* -2 (log a))) (sin (* 2 pi b))))))) (with-present-to-file (plot plot :margin 20) (out-path :width 400 :height 400) (let ((points (loop for count below 100 for (x y) = (rand-norm) collect (list (+ x 3.0) (+ y 1.0))))) (add-plot-data plot (scatter-pane origin-cluster :color +鹅黄+ :point-style :circle :point-size 4) points) (add-plot-data plot (scatter-pane rotated-60d :color +大红+ :point-style :cross :point-size 4) (loop with mat = (z-rot-mat (/ pi 3)) for point in points collect (matrix-product mat point :type 'list))) (add-plot-data plot (scatter-pane rotated-180d :color +茶褐+ :point-style :square :point-size 4) (loop with mat = (z-rot-mat pi) for point in points collect (matrix-product mat point :type 'list))) (add-plot-data plot (scatter-pane origin :color +black+ :point-style :+ :point-size 10) '((0.0 0.0)))))) out-path
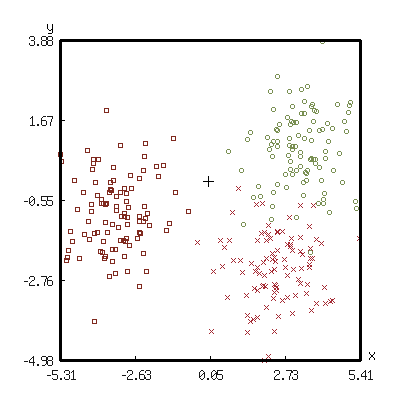
感觉差不多得了… 之后有时间再思考自己做一个… 毕竟线代已经寄了.
Dictionary
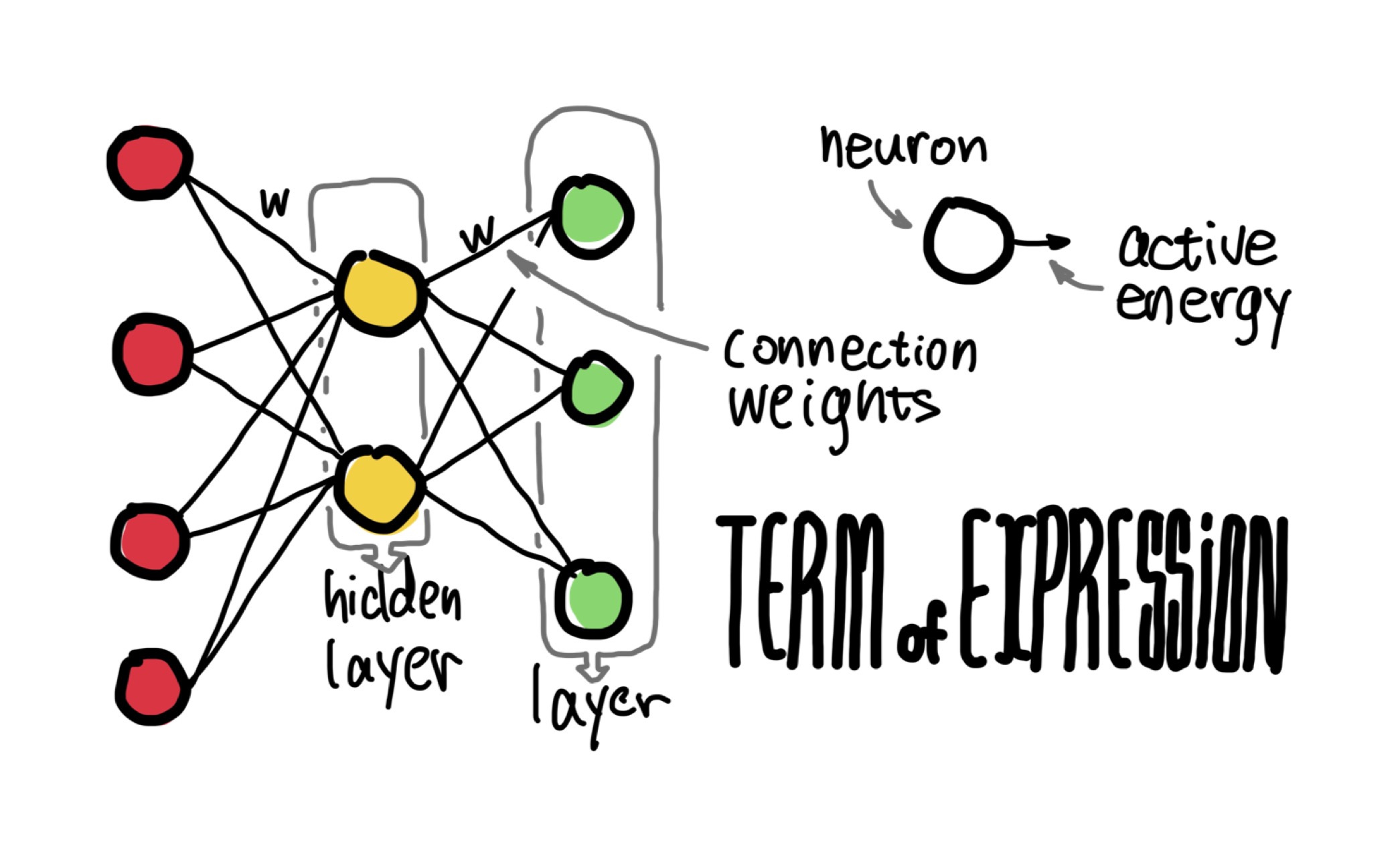
- neuron: a simple processor which sums the output from one or more
other neurons, applies some form of transfer function to this sum,
and outputs this transformed sum to the inputs of other neurons.
\[\mathrm{SumProducts}_{\mathrm{output}} = ∑_{\mathrm{input} = 0}^{\mathrm{sizeInput}} \mathrm{Input}_{\mathrm{input}} × \mathrm{Weight}_{\mathrm{input}, \mathrm{output}}\]
貌似是全链接网络的样子… 虽然这样听起来有点落后于时代了的感觉… 但是还是从简单的来开始吧.
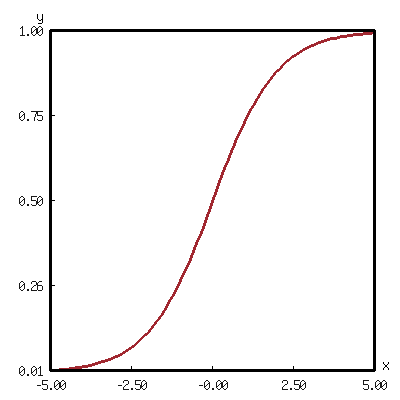
- activation energy: the output of a neuron
\[\mathrm{Output}_{\mathrm{output}} = \mathrm{Sigmoid}(\mathrm{SumProducts}_{\mathrm{output}})\]
sigmoid 函数
(defun sigmoid (x) "The S-shaped curve function, or the logistic function. " (/ 1.0 (+ 1.0 (exp (- x))))) (defun d-sigmoid (x) "The derivative of sigmoid function. " (let ((sigmoid (sigmoid x))) (* sigmoid (- 1.0 sigmoid))))
(with-present-to-file (plot plot :margin 10) (out-path :width 400 :height 400) (add-plot-data plot (line-plot-pane sigmoid :color +莲红+) (loop for x from -5.0 to 5.0 by 0.1 collect (list x (sigmoid x))))) out-path
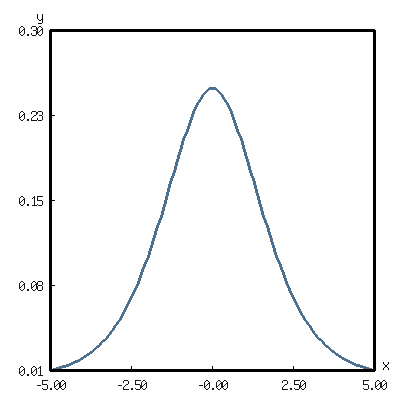
(with-present-to-file (plot plot :margin 10 :y-max 0.3) (out-path :width 400 :height 400) (add-plot-data plot (line-plot-pane sigmoid :color +月白+ ) (loop for x from -5.0 to 5.0 by 0.1 collect (list x (d-sigmoid x))))) out-path
- connection weight, weights, connections: numeric quantity which
determines how much of a neuron's output value reaches the input
to the next neuron to which it is connected.
a connection weight is is defined by a source neuron, a target neuron, and a numeric weighting factor.
- layer of neuron, slabs: a set of logically grouped neurons
- hidden layer: having no direct connections to neural network input or output signals
Simple Delta Rule Neural Network Simulator
这是一个只有输入和输出的模型, 没有隐藏层. (2-Layer, No hidden layer)
一些接口
(defgeneric network-size (network)
(:documentation
"Return a list represent the `network' size.
The returned list like below:
(input-size ... hidden-layer-size ... output-size)
"))
(defgeneric output (network input)
(:documentation
"Return the output of `input' for `network'. "))
(defgeneric train-on (network input target)
(:documentation
"Train on specific `input' and `target' for `network'. "))
- 首先是数据的表示 (注: 原文这里用的是
list做数据结构, 并且是对应数组为数据格式, 这里把原本的list改成了更加直观的 oop, 不过还是会尽量保留原文的代码的逻辑, 虽然还是会加入我自己的随机魔改的代码. )(defparameter *default-learning-rate* 0.6 "The default learning rate. ") (defparameter *default-intern-type* 'single-float "The default interner type used for network. ") (defclass layer () ((inputs :initarg :inputs) (outputs :initarg :outputs) (weights :accessor weights) (active-function :initform #'sigmoid :initarg :active-function) (d-active-function :initform #'d-sigmoid :initarg :d-active-function) (learning-rate :initform *default-learning-rate* :initarg :learning-rate) (intern-type :initform *default-intern-type* :initarg :intern-type)) (:documentation "The class representing a network layer.")) (defmethod initialize-instance :after ((layer layer) &key) (with-slots (inputs outputs weights intern-type) layer ;; init weights with random noises (setf weights (rand (list outputs inputs) :type intern-type)))) (defun make-layer (input output &key (learning-rate 0.6) (intern-type 'single-float)) "Make a layer with `input' inputs and `output' outputs. " (make-instance 'layer :inputs input :outputs output :learning-rate learning-rate :intern-type intern-type))
- 将输入带入模型, 计算输出
\[\mathrm{SumProducts}_{\mathrm{outputs}} = ∑_{\mathrm{inputs} = 0}^{\mathrm{sizeInput}} \mathrm{Input}_{\mathrm{inputs}} * \mathrm{Weight}_{\mathrm{inputs}, \mathrm{outputs}}\]
可以发现基本上为一个矩阵乘法:
(defmethod sum-products ((layer layer) input) (@ (slot-value layer 'weights) input))
为了方便, 这里把
input直接作为一个(list INPUTS)形状的矩阵 (一维向量).对于最终的输出:
\[\mathrm{Output}_{\mathrm{outputs}} = \mathrm{Sigmoid}(\mathrm{SumProducts}_{\mathrm{outputs}})\]
(defmethod output ((layer layer) input) (map! #'sigmoid (sum-products layer input)))
- 训练
对于输出的
output, 其和target所对应的值所差的error:\[\mathrm{Error}_{\mathrm{outputs}} = (\mathrm{Target}_{\mathrm{outputs}} - \mathrm{Output}_{\mathrm{outputs}}) * \mathrm{Sigmoid}^P(\mathrm{SumProducts}_{\mathrm{outputs}})\]
(大概如上的感觉.)
从误差中可以学得的:
\[\mathrm{DeltaWeight}_{\mathrm{inputs}, \mathrm{outputs}} = \mathrm{LearningRate} * \mathrm{Error}_{\mathrm{outputs}} * \mathrm{Output}_{\mathrm{outputs}}\]
(defmethod train-on ((layer layer) input target) (with-slots (inputs outputs intern-type active-function weights learning-rate) layer (let* ((magicl::*default-tensor-type* intern-type) (noised (.+ (rand (list inputs)) input)) (output (output layer noised)) (errors (.* (.- target output) (map! active-function (@ weights input)))) (delta-weights (.* learning-rate (@ (reshape errors (list outputs 1)) (reshape noised (list 1 inputs)))))) (values (norm errors) delta-weights)))) (defmethod train ((layer layer) training-data) ;; return a value for the average error signal at each output neuron (with-slots (inputs outputs weights intern-type) layer (let ((magicl::*default-tensor-type* intern-type)) (loop with rms-error = 0 with delta-weights = (zeros (list outputs inputs)) for (input target) in training-data do (multiple-value-bind (err delta-w) (train-on layer input target) (incf rms-error err) (setf delta-weights (.+ delta-weights delta-w))) finally (progn (setf weights (.+ weights delta-weights)) (return (values rms-error delta-weights)))))))
呃, 感觉不就是线性拟合么… 并且代码还不是很直观… 对最终结果的可靠性表示怀疑…
但是单从误差上来看, 确实发生了误差的减少…
(let* ((layer (make-layer 2 2))
(data (loop for (in tar) in '(((1 0) (0 1))
((0 1) (0 1)))
collect (list (from-list in '(2) :type 'single-float)
(from-list tar '(2) :type 'single-float))))
(rms (loop for i below 100
collect (list i (train layer data)))))
(with-present-to-file
(plot plot :margin 10 :y-max 0.4 :y-min 0.0 :x-min 0
:x-label "iter" :y-label "RMS Error")
(out-path :width 600 :height 400)
(add-plot-data plot
(line-plot-pane rms-error :color +大红官绿+)
rms)))
out-path
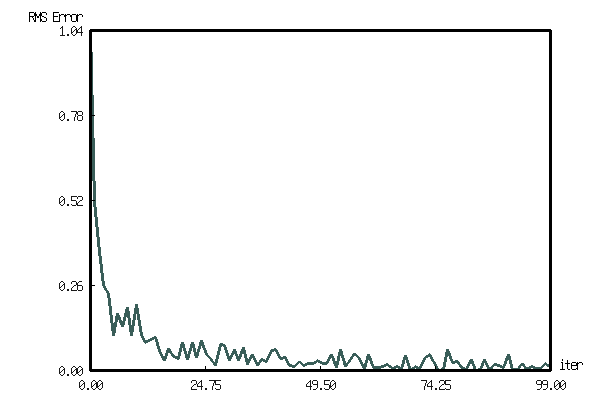
A Complete Delta Rule Neural Network Simulator
只有单层的网络可以说根本没有什么用啊… kora…
这里会借用书中的接口定义来经行设置:
(defclass network ()
((inner-layers :initform ())
(layer-sizes :initform () :initargs :layer-sizes))
(:documentation
"The network is a collection of layers, connected in sequence. "))
(defmethod initialize-instance :after
((network network) &key layer-sizes)
(setf (slot-value network 'inner-layers)
(loop for (in out) on layer-sizes by #'cddr
while (and in out)
collect (make-layer in out))))
(defun make-network (top-slab second-slab &optional more-layers)
"Make a network with each slab size, at least two slab size should be given."
(make-instance 'network
:layer-sizes (cons top-slab (cons second-slab more-layers))))
- 训练
(defmethod train ((network network) training-data) (with-slots (inner-layers) network (loop for (input target) in training-data )))
(嗯, 貌似当时看到这里就期中考了… 结果被一对快慢刀给干到了现在… 不过现在回过头来看这个, 感觉有点怪, 一般神经网络不应该是 \(\boldsymbol{A} \boldsymbol{x} + \boldsymbol{b} = \boldsymbol{y}\) 这样的形式么? 这里的偏置项 \(\boldsymbol{b}\) 好像完全没有啊… 真是奇怪. 不过也有可能是对输入项进行强制括项, 将其变成原本输入的 \(n + 1\) 维, 最后一维放一个常数来作为偏置. )
后记
Lisp 的语法被 diss, 被抛弃不是没有理由的, 在没有编辑器的辅助,
没有好的缩进习惯的情况下, 从纸面上去阅读 Lisp 代码简直就是折磨…
早期是这样的没错, 毕竟没有 Github, 商业上主要是被大公司 Symbolics 之类的垄断,
(注: 垄断的说法不合理, 实际上是 LMI, Symbolics, MIT AI Lab 三个为主要, 但是里面不仅有版权纠纷, 还有利益冲突, 只能说是各种因素导致的失败, 还是非常可惜的. 可以参考一个还算客观的回顾? History of Symbolics lisp machines)
学术上主要是大学的一些论文.
(注: 其实 Lisp 应该算是作为原型设计来说非常方便的, 但是现在原型设计应该还是通过调库来实现会更加方便, 像以前的那种一个实验室维护一套代码的情况应该非常少见了. 尽管现在随着 quicklisp 这样的分发工具的普及, 调库对于 Lisp 来说绝对不是难事, 更何况 Lisp 有 CFFI, 可以非常轻松地去调用 C 的库来解决自己的问题. )
不过感觉现在的传播条件和编辑条件上来了, 对于 Lisp 应该会更加容易使用来说才是.
并且感觉这本书里面的代码真的不能说是 “易于阅读” 的… 感觉完全就是在用命令式的 C 来写 Lisp, 根本没有用宏, 也没有函数包装.
不过里面的代码里面有一个让我觉得可以学习的点就是里面用变量进行设参.
之前写代码都是用 &optional 和 &key 进行传参, 结果就是把函数参数变得超长,
这样就很难受.
如下的例子:
(defvar *closure-variable*)
(defun this-is-a-function ()
(do-some-thing-with *closure-variable*))
(let ((*closure-variable* updated-local-closure-value))
(this-is-a-function))
这样就可以在函数调用链里面一直把参数传下去用, 非常方便呢.
不过接下去有点想先去读读看 Let Over Lambda 而不是继续看这本书了, 因为感觉自己现在写 LISP 缺少一些花活和技术, 或者说缺少对大型项目和底层的抽象能力.