Data structure: Linked List
About
本文是给 UCAS-CTF C 语言缓速班数据结构中链表一节的讲义.
Detour: 给我一块内存空间: malloc, free
一个简单的复习: 当我们使用 malloc 的时候, 我们会向系统要一个一定大小的内存空间.
比如说, 如果我们要申请一个大小是 64 个 float 的空间, 那么我们会使用:
float* farr_64 = malloc(sizeof(float) * 64);
而当我们结束了这块内存空间的使用时, 又可以通过 free 的方式释放这块内存空间:
free(farr_64);
如此这般申请得到的内存空间是一块连续的内存空间, 我们可以用:
for (size_t i = 0; i < 64; i++)
*(farr_64 + i) // 指针的形式
= a_simple_function(farr_64[i]); // 类似数组的形式
来读写这个内存空间上的数据.
示例代码
#include <stdlib.h>
#include <stdio.h>
#define SIZE 5
int
main (int argc, char** argv)
{
float *arr = malloc(sizeof(float) * SIZE);
// init arr with random number [0, 1)
for (size_t i = 0; i < SIZE; i++)
arr[i] = ((float)rand() / (float)RAND_MAX);
for (size_t i = 0; i < SIZE; i++)
printf("%.2f, ", *(arr + i));
printf("\n");
free(arr);
return 0;
}
0.00, 0.13, 0.76, 0.46, 0.53,
问题: 你现在需要储存一个用户的名字的数据,
你认为正常人类的名字应该可以在 80 个字符内搞定,
所以你 malloc(80 * sizeof(char)) 作为了用户的名字的空间,
然后你得到了这样的名字:
寿限无寿限无扔屎机前天小新的内裤新八的人生巴尔蒙克·费扎利昂艾萨克·修奈达 三分之一纯情的感情的剩下三分之二是在意肉刺的感情我知道无法逃离的背叛其实 可以逃离离家出游鱿鱼煎鲣鱼鱼子自家粪池鲣鱼……这条鲣鱼跟刚才的不同这条 是池乃鲣鱼啦辣油雄帝宫王木村皇呸呸呸呸呸呸呸呸呸呸呸呸小屎丸
emmm… 好吧, 那么把 SIZE 设为 256 吧, 这下足够大了吧:
Adolph Blaine Charles David Earl Frederick Gerald Hubert Irvin John Kenneth Lloyd Martin Nero Oliver Paul Quincy Randolph Sherman Thomas Uncas Victor William Xerxes Yancy Zeus Wolfeschlegelsteinhausenbergerdorffwelche voralternwarengewissenhaftschaferswessenschafewarenwohl gepflegeundsorgfaltigkeitbeschutzenvorangreifendurchihr raubgierigfeindewelchevoralternzwolfhunderttausendjahres vorandieerscheinenvonderersteerdemenschderraumschiff genachtmittungsteinundsiebeniridiumelektrischmotorsgebrauch lichtalsseinursprungvonkraftgestartseinlangefahrt hinzwischensternartigraumaufdersuchennachbarschaftderstern welchegehabtbewohnbarplanetenkreisedrehensichundwohinder neuerassevonverstandigmenschlichkeitkonntefortpflanzenundsich erfreuenanlebenslanglichfreudeundruhemitnichteinfurchtvor angreifenvorandererintelligentgeschopfsvonhinzwischensternartig raum Sr.
emmm… 那么把 SIZE 设为 1028 吧…
好像也不太对劲, 当然, 你也不是不能强制用户将自己的名字设定为 3-20 个字符,
但如果我们想要一个能够支持储存任意长度的输入的数据结构, 这该如何呢?
也不是不能…
我们可以做一个数组 append 的操作:
- 若需要填充的数据大小
< length(arr), 则将数据写入arr[fill-pointer] - 防止, 新建一个数组, 其大小为
length(arr) + APPEND_SIZE, 然后将旧数组的所有数据都拷贝进去.
#include <stdio.h>
#include <stdlib.h>
#define DATA_T int
typedef struct appendable_vector_ {
size_t fill_pointer;
size_t length;
DATA_T* data;
} AppendableVector;
/*
Return a pointer to allocated `AppendableVector`.
If failed to alloc, return NULL;
Parameters:
+ `length`: size of `AppendableVector`
*/
AppendableVector *make_vector(size_t length) {
AppendableVector *vec = malloc(sizeof(AppendableVector));
vec->data = malloc(sizeof(DATA_T) * length);
vec->fill_pointer = 0;
vec->length = length;
if (vec == NULL || vec->data == NULL) {
free(vec->data);
free(vec);
return NULL;
}
return vec;
}
/*
Push `element` to the end of `vec`.
Parameters:
+ `vec`: a pointer to `AppendableVector`
+ `element`: an element as `vec` new element
*/
AppendableVector *vector_push(AppendableVector *vec, int element) {
// no space to fill
if (vec->fill_pointer == vec->length) {
int *data = malloc(sizeof(DATA_T) * (vec->length + (vec->length / 2) + 1));
for (size_t i = 0; i < vec->length; i++)
data[i] = vec->data[i];
free(vec->data);
vec->data = data;
}
vec->data[vec->fill_pointer] = element;
vec->fill_pointer++;
return vec;
}
/*
Free allocation of AppendableVector `vec`.
*/
void free_vector(AppendableVector *vec) {
free(vec->data);
free(vec);
}
/*
Print all the data in AppendableVector `vec`.
*/
void print_vector(AppendableVector *vec) {
printf("[");
for (size_t i = 0; i < vec->fill_pointer; i++)
printf("%d, ", vec->data[i]);
printf("]\n");
}
int main(int argc, char **argv) {
AppendableVector *vec = make_vector(0);
for (int i = 0; i < 10; i++) {
print_vector(vector_push(vec, i));
}
free_vector(vec);
return 0;
}
[0, ] [0, 1, ] [0, 1, 2, ] [0, 1, 2, 3, ] [0, 1, 2, 3, 4, ] [0, 1, 2, 3, 4, 5, ] [0, 1, 2, 3, 4, 5, 6, ] [0, 1, 2, 3, 4, 5, 6, 7, ] [0, 1, 2, 3, 4, 5, 6, 7, 8, ] [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ]
链表 LinkedList
一个非常简单的链表的实现
一个简单的想法就是: 好吧, 如果当前分配的内存不够用了, 就在它后面跟一块补丁. 类似如下图所示:

即, 我们可以把每一份储存的数据片段看作是由两个部分组成的:
car: 数据片段本身, 或是一个指向该数据片段的指针cdr: 一个指向下一段数据片段的指针, 如果其指向NULL, 则表示没有更多的数据了, 即数据本身的结束.
为什么叫作 car 和 cdr? (一点点的历史)
在 IBM 的 704 机 上, 有一个叫作 Type A 的指令 (page 8), 其由 prefix, decrement,
tag, address 组成. 早期的 LISP-1 的实现使用了这样的一个 Word 来表示一个 cons
数据结构 (有点类似于下面定义的 LinkedString).
所以叫作 *C*ontent of the *A*ddress *R*egister 以及 *C*ontent of the *D*ecrement *R*egister.
那么为什么要用 LISP 里的名字来叫 list 呢? 明明我们可以有其他各种各样的称呼,
这是因为 LISP (*LIS*t *P*rocessing, 列表处理) 差不多可以算是最早的 (仅次于 Fortran)
的编程语言之一了. 用它来代表一类的编程语言以及其结构, 我觉得并无不可.
我们将会在后面的例子里面看到, 使用列表结构可以如何简单地定义一门编程语言的解释器.
于是我们可以用这样的方式来实现我们前面的 “任意长度名称” 存储的数据结构:
typedef struct linked_string_ {
char chr; // car
struct linked_string_ *next; // cdr
} LinkedString;
假如我们有一个函数可以构造这样的数据对 cons_LinkedString(chr, next),
具体的实现
LinkedString* cons_LinkedString(char chr, LinkedString *next) {
LinkedString *str = malloc(sizeof(LinkedString));
str->chr = chr;
str->next = next;
return str;
}
void print_LinkedString(LinkedString *str) {
putchar(str->chr);
if (str->next != NULL)
print_LinkedString(str->next);
}
void free_LinkedString(LinkedString *str) {
if (str->next != NULL)
free_LinkedString(str->next);
free(str);
}
于是我们就可以把一个字符串 =”Hello”= 写作:
cons_LinkedString('H', cons_LinkedString('e', \
cons_LinkedString('l', cons_LinkedString('l', \
cons_LinkedString('o', NULL)))));
一个完整的演示
#include <stdio.h>
#include <stdlib.h>
<<LinkedString>>;
<<cons_LinkedString>>;
int main (int argc, char **argv) {
LinkedString *hello = <<linked_string_hello>>;
print_LinkedString(hello);
free_LinkedString(hello);
return 0;
}
Hello
对链表的各种操作
这部分可能有些无趣, 我会尽量用图示, 伪代码算法描述以及折叠的 C 代码进行介绍.
- 读第
n个元素的值nth_LinkedString(n, str)
Algorithm:
- 从
list头开始, 若n为0, 则返回first(str) - 反之, 若
n > 0, 则返回nth_LinkedString(n - 1, rest(str))
简单的实现和实现需要注意的问题
char nth_LinkedString(int n, LinkedString *str) { if (n == 0) return str->chr; if (n < 0) return '\0'; if (str->next == NULL) return '\0'; return nth_LinkedString(n - 1, str->next); }
如何处理边界条件
n?一些有趣的其他的数据结构的模拟
这部分不是那么有用, 大家可以看看就好.
我们可以用
list去模拟一个表:((a1 1 2 3) (a2 3 4 5) ...)

思考: 大家可以思考一下如何:
- 从表里面读取和写入数据
- 合并两个表
- …
- 从
- 判断两个链表是否相等
equalp_LinkedString(str1, str2)
Algorithm:
- 若
str1和str2都是NULL, 则相同 - 若
car(str1)和car(str2)不相同, 则不同 - 比较
equalp(cdr(str1), cdr(str2))
简单的实现
int equalp_LinkedString(LinkedString *str1, LinkedString *str2) { if (str1 == NULL && str2 == NULL) return TRUE; if (str1->chr != str2->chr) return FALSE; return equalp_LinkedString(str1->next, str2->next); }
- 若
- 删除第
n个元素delete_nth_LinkedString(n, str)
Algorithm:
- 找到第
n个元素的cons_n, 以及前一个元素的cons_{n-1}, 以及后一个元素cons_{n+1} - 将
cons_{n-1}->next指向cons_{n+1}
简单的实现
LinkedString* delete_nth_LinkedString(int n, LinkedString* str) { n = n - 1; LinkedString *search = str; while (n-- && search != NULL) search = search->next; search->next = search->next->next; return str; }
思考: 如果我们不希望删除的操作对
str本身存在修改的行为 (side-effect), 我们该如何设计这个算法?注: 这个思考题其实包含了一个
immutable(不可变) 对象的处理方法的考虑. - 找到第
- 替换链表中的第
n个元素set_nth_LinkedString(chr, n, str)
思考: 这个算法并不难想, 留作习题.
思考: 同样的, 我们也可以考虑该如何去实现这样的无 side-effect 版本的算法.
- 合并两个链表
append_LinkedString(str1, str2)思考: 这个算法并不难想, 看看上面的
set_nth_LinkedString, 留作习题.思考: 如果我们希望的是
union_LinkedString(str1, str2), 该如何设计?思考: 同样的, 如果我们希望实现非 destructive 的算法, 又该如何设计?
为什么在这里会要求一些无 side-effect 的算法?
尾递归
我们会发现, 前面的算法往往都有如下的形式:
RESULT_T foo(LinkedList *list) {
if (continuep(list->car) && list->cdr != NULL)
return foo(list->cdr);
else
return process_on(list->car);
}
即我们通过递归的方式构建我们的算法, 这样的算法写起来和读起来都非常容易, 只是… 对于性能敏感肌的同学们往往会问一个问题: 你这递归算法, 函数调用的开栈过程是不是很影响性能啊?
那么难道没法解决了么? 并非如此, 我们会发现上面的递归算法可以写成循环的形式:
RESULT_T foo(LinkedList *list) {
while (continuep(list->car) && list->cdr != NULL)
list = list->cdr;
return process_on(list->car);
}
当然, 这个例子还是有点太简单了, 实际上在编译器中这样的替换会被自动执行, 称为 “尾递归” 优化.
思考: 请比较下面的同一个函数的两种不同表示, 哪一种会被尾递归优化?
LinkedString* str_to_LinkedString (char* str) {
if (*str == '\0')
return NULL;
else
return cons_LinkedString(*str, str_to_LinkedString(str + 1));
}
和:
LinkedString* str_to_LinkedString_acc (char* str, LinkedString *lstr) {
if (*str == '\0')
return lstr;
else
return str_to_LinkedString_acc(str + 1, cons_LinkedString(*str, lstr));
}
答案
后者… (废话, 选名字长的, bushi)
相当于用函数 argument 作为了循环中的循环变量.
那么古尔丹, 代价是什么呢?
- 空间上更占空间
不难发现, 和数组相比, 链表的每个元素还多了一个指向下一个元素的指针, 虽然占用的内存不多, 但是总归也算是内存
- 时间上也没占优势
比如访问第
n个元素的时候, 我们总要进行n次寻址, 而与之对比的是, 数组的第n个元素的访问快的多了.
那么难道就完蛋了吗?
其实也不是不能做一些简单的优化:
- 比如可以用一个简单的标记来标记数据, 将数据分为 normal cdr 和 compressed cdr:
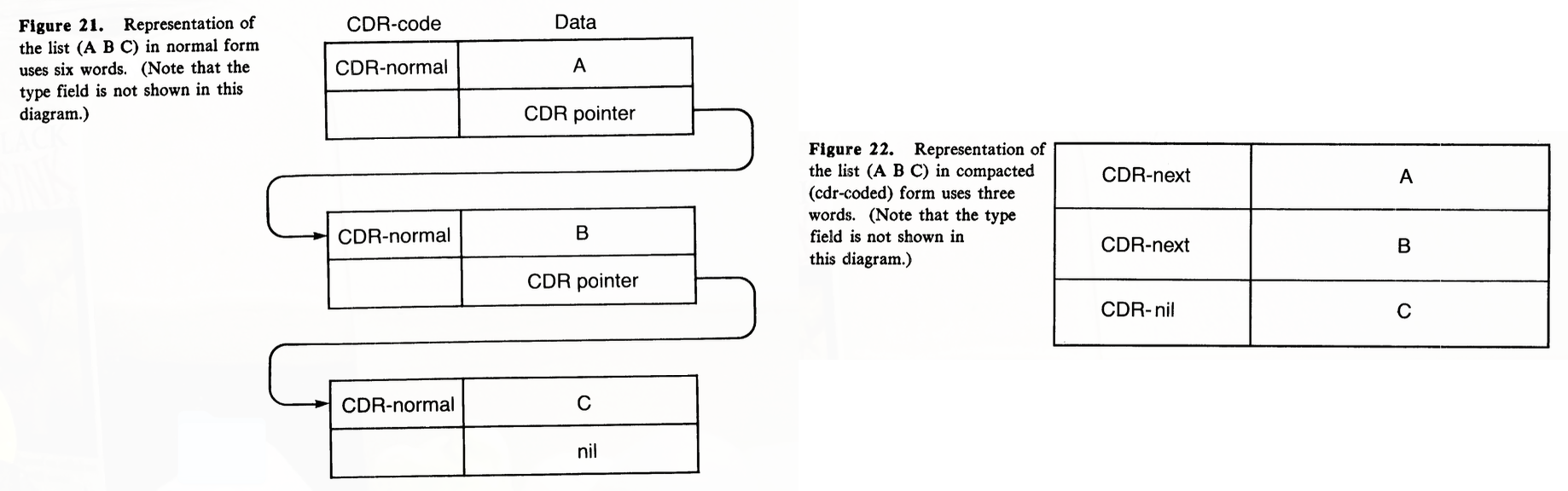
(Symbolics 3600 Techical Summary)
- 或者可以用类似于一块数组接另一块数组的形式:
typedef struct linked_string_ { char buff[BUFF_SIZE]; struct linked_string_ * next; } LinkedString;
- 当然, 在硬件层面上的优化也是可以的
- 不过问题又回来了, 写得爽不就好了? 嫌跑不快的可以换一个更新的电脑, 以及尝试并行的算法
注: 不过还是建议在使用数据类型的时候还是需要考虑具体的引用场景.
既然你已经学会了单向链表, 那么双向链表和环链表估计也不是问题了吧
因为我们暂时用不到这两个, 所以只会非常简单地进行一个介绍.
- 双向链表

- 环链表

用链表实现一些有趣的东西
用链表实现逆波兰表达式的计算
读逆波兰表达式 read_from_string(str)
总的代码有点长, 这里直接给一个能用的代码了 (foo.c).
运行的效果类似于:
> (hello world) (hello . (world . nil))
- 读取输入行
- 然后打印出来
- 循环上面的步骤
一点点的解释
- 定义数据结构
typedef struct cons_ { Object* car; Object* cdr; } Cons; struct object_ { enum { CONS, SYMBOL } tag; union { Cons *cons; SymbolName *symbol; } val; };
这里用
tag的形式标记了数据结构使得其能够更好地支持不同的数据类型, 在这里, 只有SYMBOL和CONS两种数据类型. - 其实最麻烦的部分就是读取了
Object *read_from_string_(char *str, size_t *pos) { FUNC_CALL("read_from_string_"); Object *obj; SKIP_WHITESPACE(str, (*pos)); switch (str[*pos]) { case '\0': DEBUG(str, (*pos), "read_from_string_", "End of input line. "); free(obj); FUNC_RET(NULL); break; case '(': DEBUG1(str, (*pos), "read_from_string_", "read list cons mark ( \n"); (*pos)++; // skip ( obj = read_cons_from_string_(str, pos); break; default: obj = malloc(sizeof(Object)); obj->tag = SYMBOL; obj->val.symbol = read_SymbolName_from_string_(str, pos); // failed to read SymbolNames if (obj->val.symbol == NULL) { free(obj); FUNC_RET(NULL); } break; } FUNC_RET(obj); }
用的是非常简单粗暴的读取方法.
请阅读代码, 然后拓展代码使得能够支持 NUMBER 类型的数
- 第一个函数: 让我们历遍
SymbolName以判断其是否是一个NUMBERint SymbolName_numberp(SymbolName *sym); // -> TRUE or FALSE
- 第二个函数: 让我们将
SymbolName变成数if (SymbolName_numberp(obj->val.symbol)) { obj->tag = NUMBER; obj->val.number = SymbolName2number(obj->val.symbol); }
- 第 n 个函数: 大家写点四则运算之类的函数吧
比如, 举个例子:
Object *op2_add(Object *a, Object *b) { if (a == NULL || b == NULL || a->tag != NUMBER || b->tag != NUMBER) { fprintf(stderr, "Cannot add "); print_object(a, stderr); fprintf(stderr, " and "); print_object(b, stderr); fprintf(stderr, " together. "); } Object *c = malloc(sizeof(Object)); c->tag = NUMBER; c->val.number = a->val.number + b->val.number; return c; }
大家可以实现一些简单的函数来自己玩一下. 然后用:
op2_add(read_from_string("1"), read_from_string("2"));
这样的简单函数测试一下.
那么我们的内存要在什么时候回收呢?
你说的对, 我们的内存确实完全没有回收, 这会导致随着计算的增加, 我们的程序的内存占用会越来越大. 这非常的坏.
我们会在后面有空的时候介绍一下简单的 GC (垃圾回收).
eval: 让我们计算一下表达式的值
假如我们现在希望能够计算 (+ 1 2 3) 这样的表达式的值, 我们需要?
- 对于读到的表达式
expr, 我们取其car(expr)元素, 若其为+: 则将cdr(expr)元素全部加在一起-: 则将car(cdr(expr))用剩余的其他cdr(cdr(expr))元素相减- …
于是我们可以写这样的一个函数
eval:Object *eval(Object *expr) { if (expr == NULL || expr->tag != CONS) { fprintf(stderr, "Don't know how to eval("); print_object(expr, stderr); fprintf(stderr, ")\n"); return NULL; } Object *cmd = car(expr); if (eq(cmd, Sadd)) // Object *Sadd = read_from_string("+"); return op_add(cdr(expr)); else if (eq(cmd, Ssub)) // Object *Ssub = read_from_string("-"); return op_sub(cdr(expr)); // add more commands ... fprintf(stderr, "Unknown command "); print_object(cmd, stderr); fprintf(stderr, "\n"); return NULL; }
- 不难发现, 如果把这样的表达式用 C 语言一般的函数调用来写
(func arg1 arg2 arg3 ...)func(arg1, arg2, arg3, ...)
两者是等价的
一些补注: 这里提供一些辅助函数的实现
car(cons)Return
carofcons.Object *car(Object *cons) { if (cons == NULL) return NULL; if (cons->tag != CONS) { print_object(cons, stderr); fprintf(stderr, " is not cons. "); return NULL; } return cons->val.cons->car; }
cdr(cons)Return
cdrofcons.Object *cdr(Object *cons) { if (cons == NULL) return NULL; if (cons->tag != CONS) { print_object(cons, stderr); fprintf(stderr, " is not cons. "); return NULL; } return cons->val.cons->cdr; }
cons(car, cdr)Make
consofcarandcdr.eq(a, b)Test if two symbol
aandbis equal (literally). Returntif true,nilif not.cond((condition . exprs) ...)If
conditionis nonnil, evalexprs. Otherwise, test on other(condition . exprs)pairs. If non of the(condition . exprs)pairs works, returnnil.atom(expr)Test if
expris notcons.
补注的补注: 既然我们已经实现了这么多的函数…
其实可以考虑参考:
- From Linked List to the Old Yet Modern Computer (1)
- From Linked List to the Old Yet Modern Computer (2)
来只用上面的几个 car, cdr, cons, atom, eq, cond
来实现一个简单的编程语言解释器.
一些更多的乐子
- 内存回收: 前面我们已经指出了貌似我们好像缺少一些内存回收的机制, 会导致内存爆炸的危机… 这非常的坏. 那么我们该如何解决这个问题呢?
- 宏: 既然我们的表达式 (代码) 都是和数据一样的列表, 那么为啥不能用代码生成代码呢?
- 自举: 既然是图灵完备的编程语言解释器, 所以为何不妨试试让其自举呢?
- JIT: 既然能自举了, 为啥不试试 JIT 呢? 这里我们的 JIT 同样可以使用链表, 同时配合内存回收机制, 这样就能实现许多好玩的特性了.
不过太麻烦了, 跳过.
用链表实现一个 ed (略)
行储存
typedef struct line_ {
size_t line_size;
char buff[LINE_BUFF_SIZE];
struct line_ *rest;
} Line;
我们可以用一个 linked-trunk 来表示行这个数据结构.
文件 buffer 的储存
typedef struct buffer_lines_ {
size_t line_number;
Line *curr;
struct buffer_lines_ *prev;
struct buffer_lines_ *next;
} BufferLines;
typedef struct buffer_ {
char *filename;
BufferLines* head;
BufferLines* tail;
BufferLines* curr;
} Buffer;
可以用一个双向链表实现的环来储存文件 buffer.
一些操作
append_line_(BufferLines *pos, BufferLines *line)Insert
lineafterpos.read_BufferLines_(char *str, size_t *pos)Return
Bufferlinesfromstr, increasingpos.append_line(BufferLines *pos, char *line)Insert
lineafterpos.delete_line(BufferLines *pos)Delete line at
pos.read_Buffer(char *file)Read and return
Bufferfromfile.write_Buffer(char *file, Buffer *buffer)Write
buffertofile.
注: 假如课上有时间的话, 我们可以尝试实现一下.
注: 比较困难的部分是指令的读取
大家可以参考 ed 的官方文档来实现指令读取和操作功能. 这里就略过了.